
Yan Cui
I help clients go faster for less using serverless technologies.

This is a lesson that I wished I learnt when I first started using AWS Lambda in anger, it would have made my life simpler right from the start.
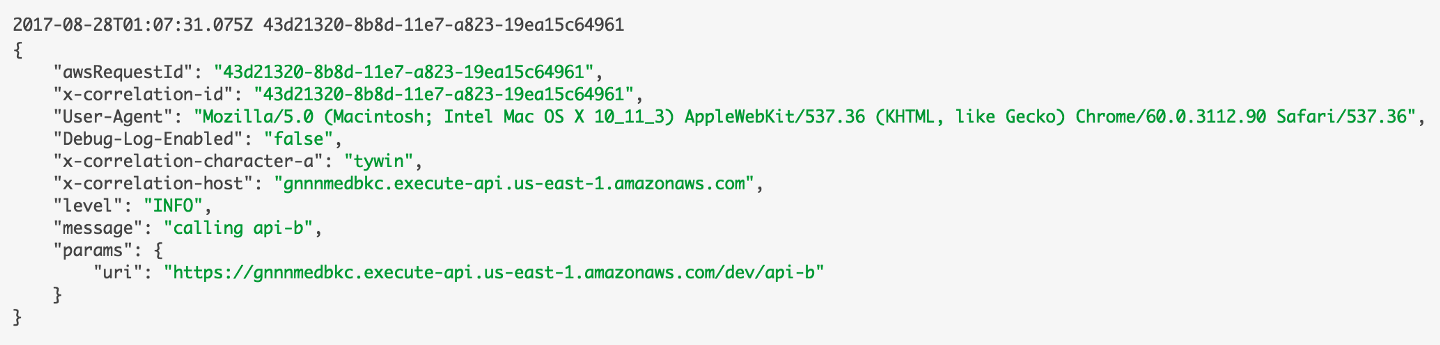
But, we did get there before long, and it allowed us to track and include correlation IDs in our log messages (which are then pushed to an ELK stack)which would also include other useful information such as:
- age of the function execution
- whether invocation was a cold start
- log level
- etc.
Looking back, I fell into the common trap of forgetting the practices that had served us well in a different paradigm of developing software, at least until I figured out how to adopt these old practices for the new serverless paradigm.
In this case, we know structured logs are important and why we need them, and also how to do it well. But like many others, we started with console.log because it was simple and it worked (to a limited degree).
But, this approach has a really low ceiling:
- you can’t add contextual information with the log message, at least not in a way that’s consistent (you may change the message you log, but the contextual information should always be there, e.g. user-id, request-id, etc.) and easy to extract for an automated process
- as a result, it’s also hard to filter the log messages by specific attributes – e.g. “show me all the log messages related to this request ID”
- it’s hard to control what level to log at (i.e. debug, info, warning, …) based on configuration – e.g. log at debug level for non-production environments, but log at info/warning level for production
Which is why, if you’re just starting your Serverless journey, then learn from my mistakes and write your logs as structured JSON from the start. Also, you should use whatever log client that you were using before – log4j, nlog, loggly, log4net, whatever it is – and configure the client to format log messages as JSON and attach as much contextual information as you can.
As I mentioned in the post on how to capture and forward collection IDs, it’s also a good idea to enable debug logging on the entire call chain for a small % of requests in production. It helps you catch pervasive bugs in your logic (that are easy to catch, but ONLY if you have the right info from the logs) that would otherwise require you to redeploy all the functions on the entire call chain to turn on debug logging…

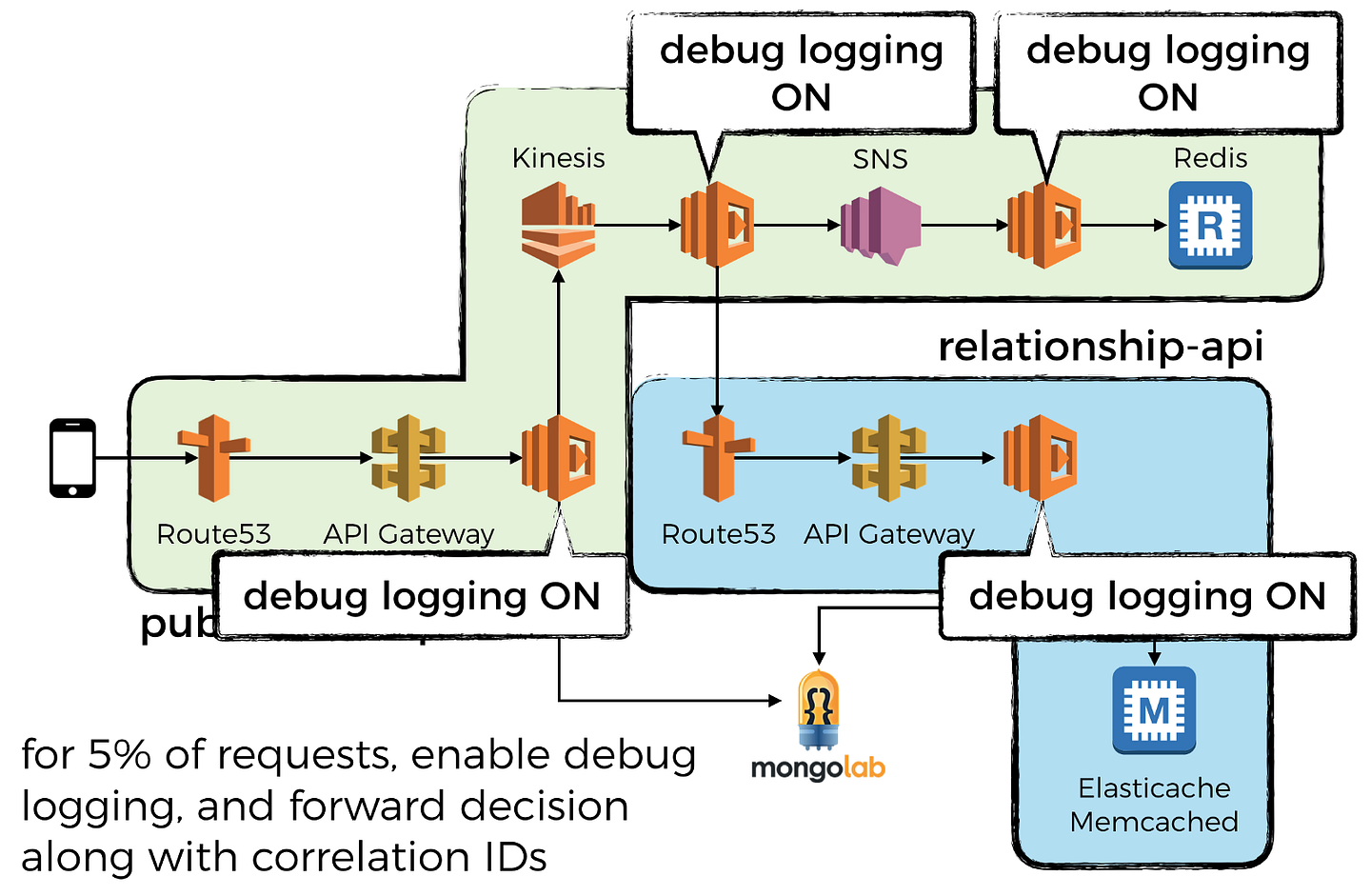
So there, a simple and effective thing to do to massively upgrade your serverless architecture. Check out my mini-series on logging for AWS Lambda which covers log aggregation, tracking correlation IDs, and some tips and tricks such as why and how to send custom metrics asynchronously.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.