
Yan Cui
I help clients go faster for less using serverless technologies.

When I discuss AWS Lambda cold starts with folks in the context of API Gateway, I often get responses along the line of:
Meh, it’s only the first request right? So what if one request is slow, the next million requests would be fast.
Unfortunately that is an oversimplification of what happens.
Cold start happens once for each concurrent execution of your function.
API Gateway would reuse concurrent executions of your function that are already running if possible, and based on my observations, might even queue up requests for a short time in hope that one of the concurrent executions would finish and can be reused.
If, all the user requests to an API happen one after another, then sure, you will only experience one cold start in the process. You can simulate what happens with Charles proxy by capturing a request to an API Gateway endpoint and repeat it with a concurrency setting of 1.
As you can see in the timeline below, only the first request experienced a cold start and was therefore noticeably slower compared to the rest.
1 out of 100, that’s bearable, hell, it won’t even show up in my 99 percentile latency metric.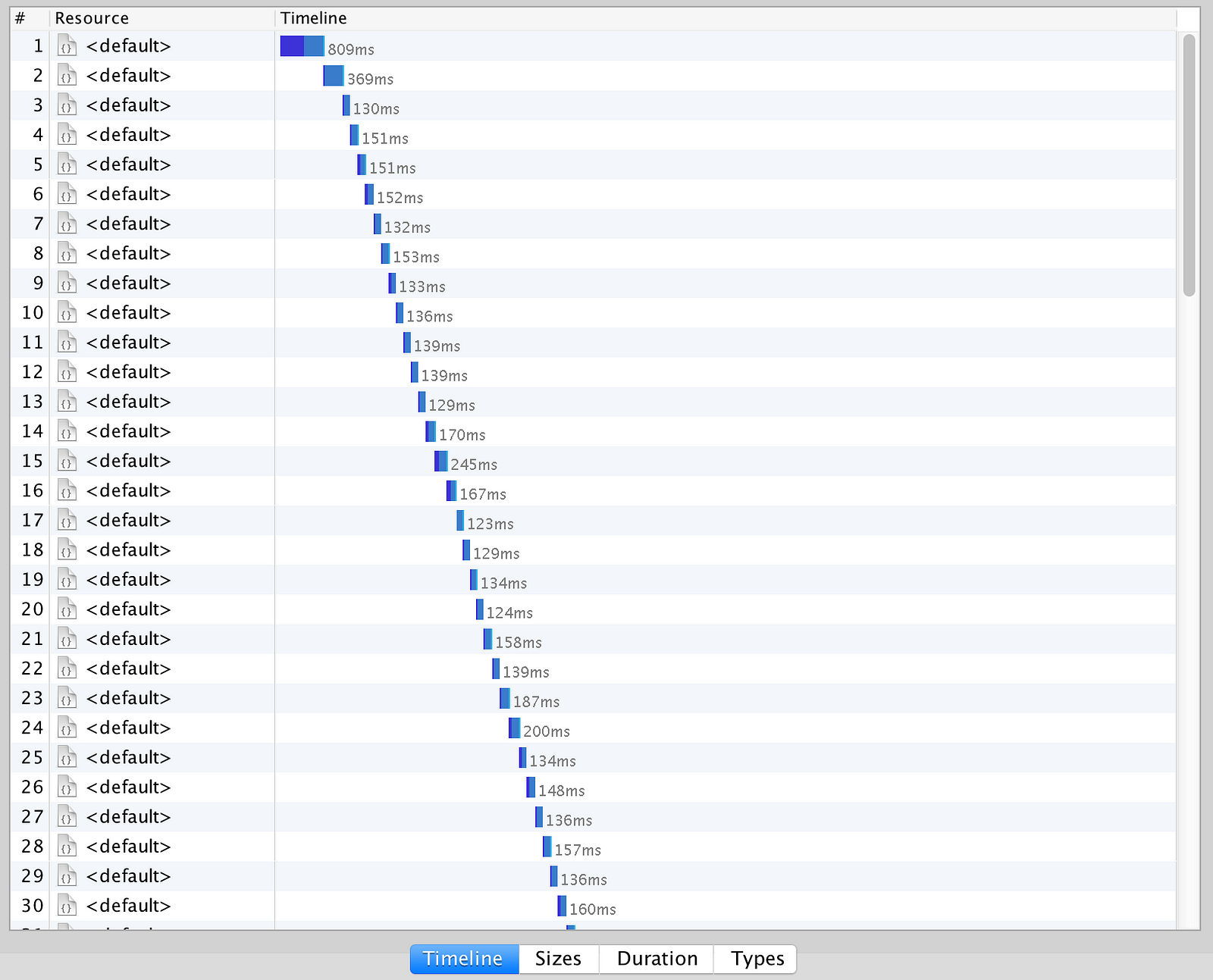
What if the user requests came in droves instead? After all, user behaviours are unpredictable and unlikely to follow the nice sequential pattern we see above. So let’s simulate what happens when we receive 100 requests with a concurrency of 10.
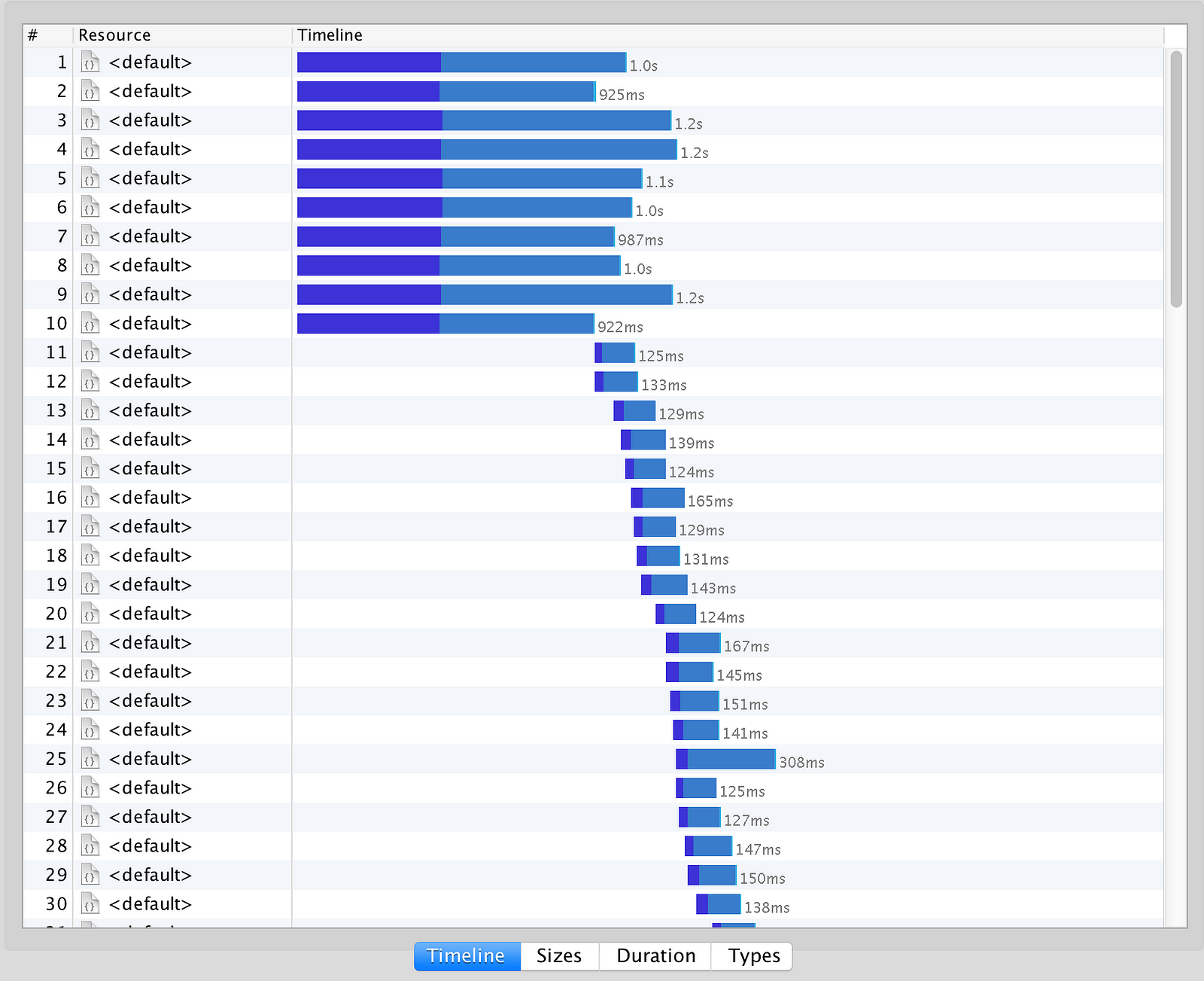
All of a sudden, things don’t look quite as rosy – the first 10 requests were all cold starts! This could spell trouble if your traffic pattern is highly bursty around specific times of the day or specific events, e.g.
- food ordering services (e.g. JustEat, Deliveroo) have bursts of traffic around meal times
- e-commence sites have highly concentrated bursts of traffic around popular shopping days of the year – cyber monday, black friday, etc.
- betting services have bursts of traffic around sporting events
- social networks have bursts of traffic around, well, just about any notable events happening around the world
For all of these services, the sudden bursts of traffic means API Gateway would have to add more concurrent executions of your Lambda function, and that equates to a bursts of cold starts, and that’s bad news for you. These are the most crucial periods for your business, and precisely when you want your service to be at its best behaviour.
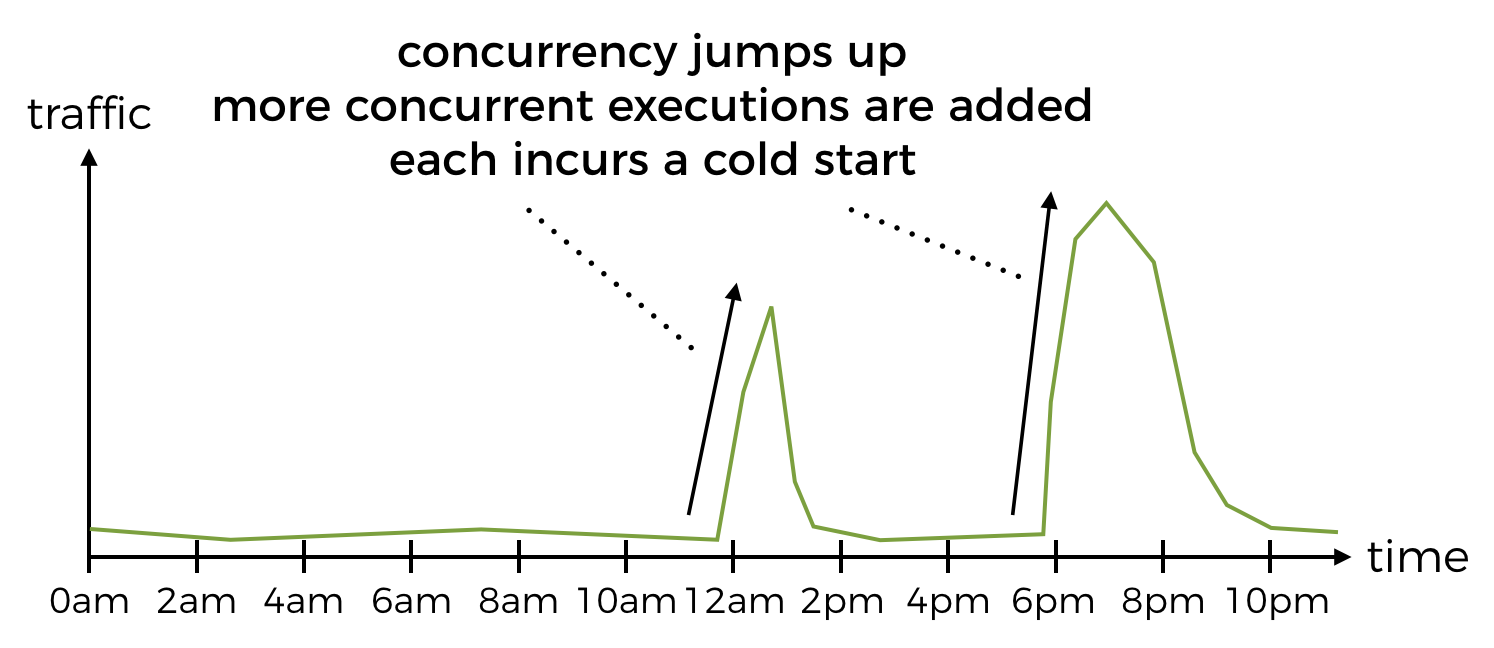
If the spikes are predictable, as is the case for food ordering services, you can mitigate the effect of cold starts by pre-warming your APIs – i.e. if you know there will be a burst of traffic at noon, then you can schedule a cron job (aka, CloudWatch schedule + Lambda) for 11:58am that will hit the relevant APIs with a blast of concurrent requests, enough to cause API Gateway to spawn sufficient no. of concurrent executions of your function(s).
You can mark these requests with a special HTTP header or payload, so that the handling function can distinguish it from a normal user requests and can short-circuit without attempting to execute the normal code path.
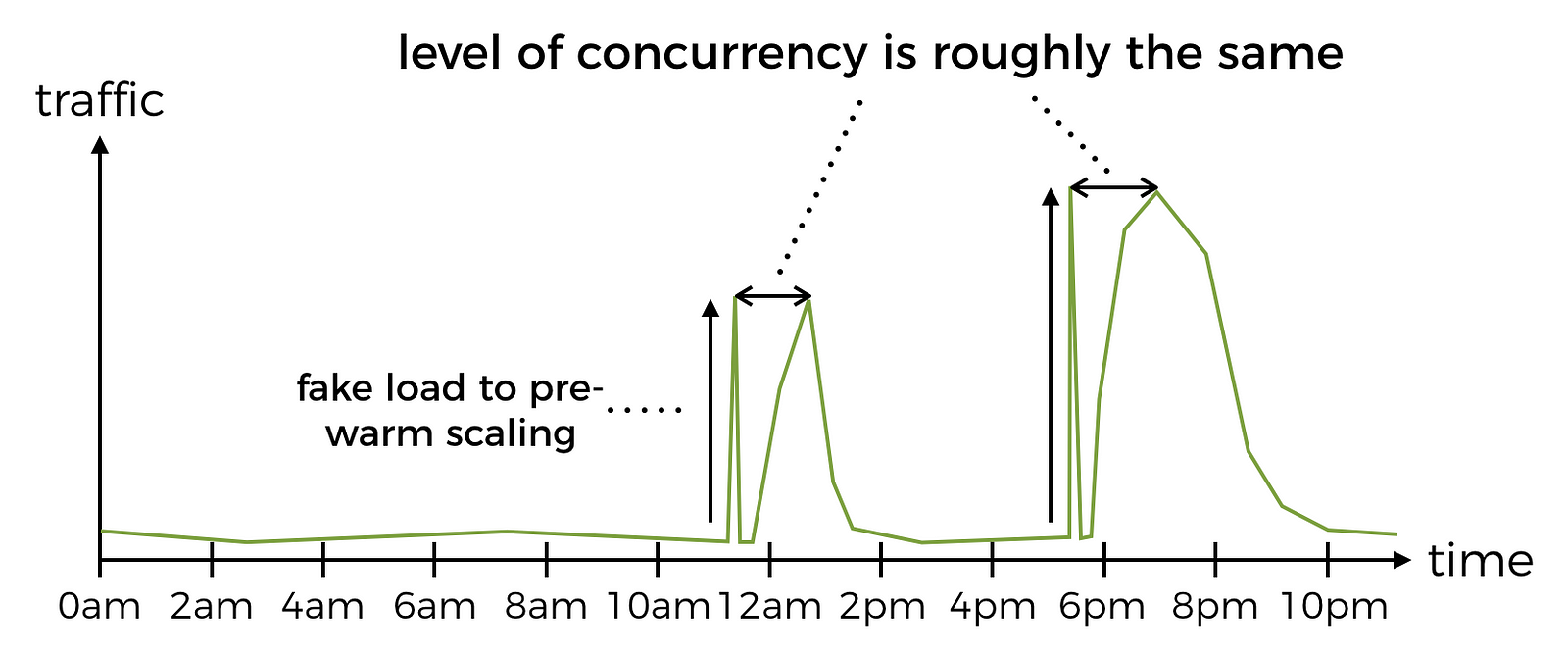
That’s great that you mitigates the impact of cold starts during these predictable bursts of traffic, but does it not betray the ethos of serverless compute, that you shouldn’t have to worry about scaling?
Sure, but making users happy thumps everything else, and users are not happy if they have to wait for your function to cold start before they can order their food, and the cost of switching to a competitor is low so they might not even come back the next day.
Alternatively, you could consider reducing the impact of cold starts by reducing the length of cold starts:
- by authoring your Lambda functions in a language that doesn’t incur a high cold start time – i.e. Node.js, Python, or Go
- choose a higher memory setting for functions on the critical path of handling user requests (i.e. anything that the user would have to wait for a response from, including intermediate APIs)
- optimizing your function’s dependencies, and package size
- stay as far away from VPCs as you possibly can! VPC access requires Lambda to create ENIs (elastic network interface) to the target VPC and that easily adds 10s (yeah, you’re reading it right) to your cold start
There are also two other factors to consider:
- executions that are idle for a while would be garbage collected
- executions that have been active for a while (somewhere between 4 and 7 hours) would be garbage collected too
Finally, what about those APIs that are seldom used? It’s actually quite likely that every time someone hits that API they will incur a cold start, so to your users, that API is always slow and they become even less likely to use it in the future, which is a vicious cycle.
For these APIs, you can have a cron job that runs every 5–10 mins and pings the API (with a special ping request), so that by the time the API is used by a real user it’ll hopefully be warm and the user would not be the one to have to endure the cold start time.
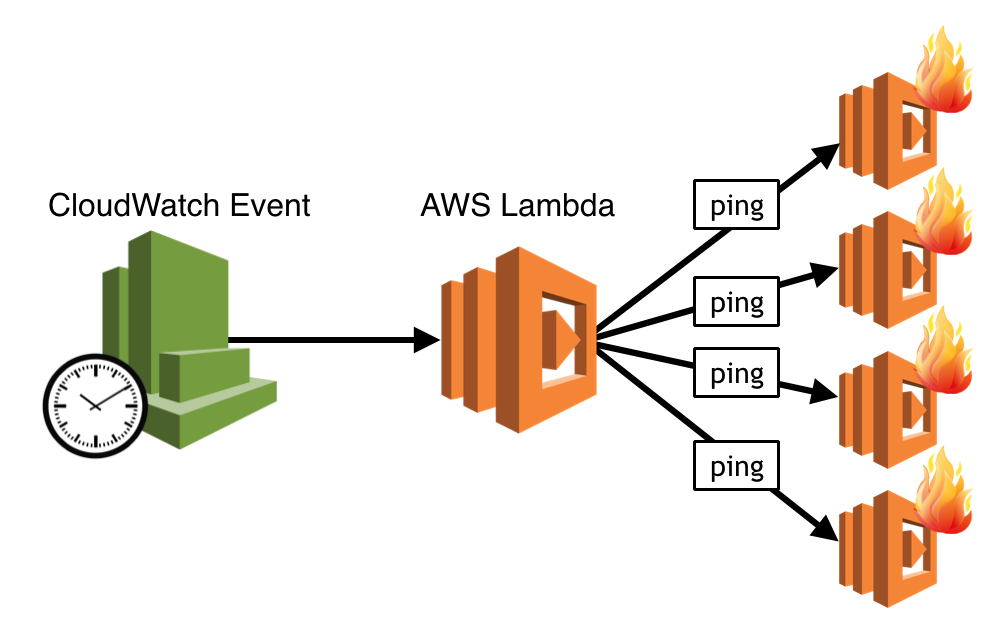
This method for pinging API endpoints to keep them warm is less effective for “busy” functions with lots of concurrent executions – your ping message would only reach one of the concurrent executions and if the level of concurrent user requests drop then some of the concurrent executions would be garbage collected after some period of idleness, and that is what you want (don’t pay for resources you don’t need).

Anyhow, this post is not intended to be your one-stop guide to AWS Lambda cold starts, but merely to illustrate that it’s a more nuanced discussion than “just the first request”.
As much as cold starts is a characteristic of the platform that we just have to accept, and we love the AWS Lambda platform and want to use it as it delivers on so many fronts. It’s important not to let our own preference blind us from what’s important, which is to keep our users happy and build a product that they would want to keep on using.
To do that, you do need to know the platform you’re building on top of, and with the cost of experimentation so low, there’s no good reason not to experiment with AWS Lambda yourself and try to learn more about how it behaves and how you can make the most of it.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hey, thanks for the article–I think many still repeat the “conventional wisdom” about the cold start, and never get past that point.
“stay as far away from VPCs as you possibly can!”
Can you elaborate on this? What is the solution? For example, if I’m running API Gateway and Lambda to return data from an RDS instance…
Also, is it guaranteed that if I ping concurrently, that’s all I need to do to have more than one function warmed and ready for more traffic? (Should we all be trying to keep 2+ function instance-whatevers warm?)
When I say “stay as far away from VPCs as you possibly can” it’s because of the overhead it adds to the cold start time. A lot of companies are sticking to the mindset of using VPCs as the sledgehammer to their security problems, even though there are a host of authentication and authorization options available to you via API Gateway, Cognito and IAM – it’s these cases where you should avoid VPCs.
Of course, if you’re using RDS or Elasticache there’s just no way around it at the moment, except to not use those services.
AWS has actually included a decision tree for when you should use VPCs in their best practices guide : https://docs.aws.amazon.com/lambda/latest/dg/best-practices.html#lambda-vpc
I don’t know if you’re guaranteed to hit all concurrent instances of your function if you issue multiple concurrent pings, probably. You could do that for sure, but I still don’t see that as a scalable solution – how do you choose that magic number X, and whatever number you choose there’s another number Y that will just undo your scheme. Also, the more concurrent instances you try to keep warm like this, the more it will increase your cost for Lambda invocations as well, which might not be trivial once you have many functions.