
Yan Cui
I help clients go faster for less using serverless technologies.

In the last post I discussed the pros & cons of following the Single Responsibility Principle (SRP) when moving to the serverless paradigm.
One of the questions that popped up on both Twitter and Medium is “how do you deal with shared code?”. It is a FAQ whenever I speak at user groups or conferences about AWS Lambda, alongside “how do you deal with shared infrastructure that doesn’t clearly belong to any one particular service?”
So here are my thoughts on these two questions.
Again, I’m not looking to convince you one way or the other and I don’t believe there’s a “right” answer that’d work for everyone. This is simply me talking out loud and sharing my internal thought process with you and hopefully get you asking the same questions of your own architecture.
As ever, if you disagree with my assessment or find flaws in my thinking, please let me know via the comments section below.
As you build out your system with all these little Lambda functions, there are no doubt going to be business logic, or utility code that you want to share and reuse amongst your Lambda functions.
When you have a group of functions that are highly cohesive and are organised into the same repo – like the functions that we created to implement the timeline feature in the Yubl app – then sharing code is easy, you just do it via a module inside the repo.
But to share code more generally between functions across the service boundary, it can be done through shared libraries, perhaps published as private NPM packages so they’re only available to your team.
Or, you can share business logic by encapsulating them into a service, and there are couple of considerations you should make in choosing which approach to use.

visibility
When you depend on a shared library, that dependency is declared explicitly, in the case of Node.js, this dependency is declared in the package.json.
When you depend on a service, that dependency is often not declared at all, and may be discovered only through logging, and perhaps explicit attempts at tracing, maybe using the AWS X-Ray service.
deployment
When it comes to deploying updates to these shared code, with shared library, you can publish a new version but you still have to rely on the consumers of your shared library to update.
Whereas with a service, you as the owner of the service has the power to decide when to deploy the update, and you can even use techniques such as canary deployment or feature flags to roll out updates in a controlled, and safe manner.
versioning
With libraries, you will have multiple active versions at the same time (as discussed above) depending on the upgrade and deployment schedule of the consumers. In fact, there’s really no way to avoid it entirely, not even with the best efforts at a coordinated update, there will be a period of time where there are multiple versions active at once.
With services, you have a lot more control, and you might choose to run multiple versions at the same time. This can be done via canary deployment or to run multiple versions side-by-side by maybe putting the version of the API in the URL, as people often do.
There are multiple ways to version an API, but I don’t find any of them to be satisfactory. Sebastien Lambla did a good talk on this topic and went through several of these approaches and why they’re all bad, so check out his talk if you want to learn more about the perils of API versioning.
backward compatibility
With a shared library, you can communicate backward compatibility of updates using semantic versioning – where a MAJOR version update signifies a breaking change. If you follow semantic versioning with your releases then backward compatibility can be broken in a controlled, well communicated manner.
Most package managers support semantic versioning by allowing the user to decide whether automatic updates should increment to the next MAJOR or MINOR version.
With a service, if you roll out a breaking change then it’ll break anyone that depends on your service. This is where it ties back to versioning again, and as I already said, none of the approaches that are commonly practiced feel satisfactory to me. I have had this discussion with my teams many times in the past, and they always ended with the decision to “always maintain backward compatibility” as a general rule, unless the circumstances dictate that we have to break the rule and do something special.
isolation
With a shared library, you generally expose more than you need, especially if it’s for internal use. And even if you have taken the care to consider what should be part of the library’s public API, there’s always a way for the consumer to get at those internal APIs via reflection.
With a service, you are much more considerate towards what to expose via the service’s public API. You have to, because anything you share via the service’s public API is an explicit design decision that requires effort.
The internal workings of that service is also hidden from the consumer, and there’s no direct (and easy) way for the consumers to access them so there’s less risk of the consumers of our shared code accidentally depending on internal implementation details. The worst thing that can happen here is if the consumers of your API start to depend on those (accidentally leaked) implementation details as features…
failure
When a library fails, your code fails, and it’s often loud & clear and you get the stack trace of what went wrong.
With a service, it may fail, or maybe it just didn’t respond in time before you stop waiting for the response. As a consumer you often can’t distinguish between a service being down, from it being slow. When that happens, retries can become tricky as well if the actions you’re trying to perform would modify state and that the action is not idempotent.
Partial failures are also very difficult to deal with, and often requires elaborate patterns like the Saga pattern in order to rollback state changes that have already been introduced in the transaction.

latency
Finally, and this is perhaps the most obvious, that calling a service introduces network latency, which is significantly higher than calling a method or function in a library.
Another question that I get a lot is “how do you manage shared AWS resources like DynamoDB tables and Kinesis streams?”.
If you’re using the Serverless framework then you can manage these directly in your serverless.yml files, and add them as additional CloudFormationresources like below.
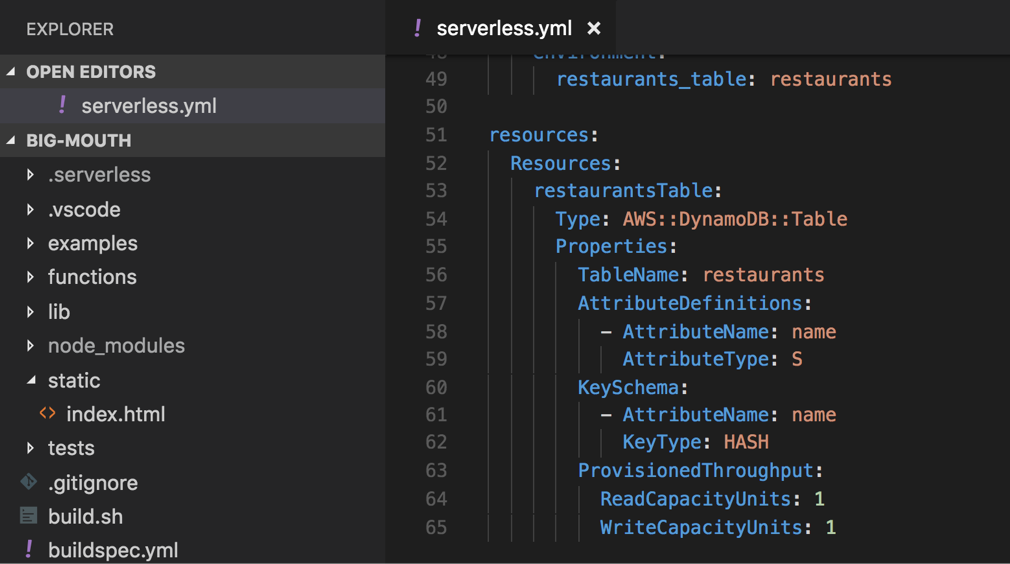
This is actually the approach I took in my video course AWS Lambda in Motion, but that is because the demo app I’m leading the students to build is a project with well defined start and end state.
But what works in a project like that won’t necessary work when you’re building a product that will evolve continuously over time. In the context of building a product, there are some problems with this approach.
"sls remove" can delete user data
Since these resources are tied to the CloudFormation stack for the Serverless(as in, the framework) project, if you ever decide to delete the functions using the sls remove command then you’ll delete those resources too, along with any user data that you have in those resources.
Even if you don’t intentionally run sls remove against production, the thought that someone might one day accidentally do it is worrisome enough.
It’s one thing losing the functions if that happens, and experience a down time in the system, it’s quite another to lose all the production user data along with the functions and potentially find yourself in a situation that you can’t easily recover from…
You can – and you should – lock down IAM permissions so that developers can’t accidentally delete these resources in production, which goes a long way to mitigate against these accidents.
You should also leverage the new backup capability that DynamoDB offers.
For Kinesis streams, you should back up the source events in S3 using Kinesis Firehose. That way, you don’t even have to write any backup code yourself!

But even with all the backup options available, I still feel uneasy at the thought of tying these resources that store user data with the creation and deletion of the compute layer (i.e. the Lambda functions) that utilises them.
when ownership is not clear cut
The second problem with managing shared infrastructure in the serverless.yml is that, what do you do when the ownership of these resources is not clear cut?
By virtue of being shared resources, it’s not always clear which project should be responsible for managing these resources in its serverless.yml.
Kinesis streams for example, can consume events from Lambda functions, applications running in EC2 or in your own datacenter. And since it uses a polling model, you can process Kinesis events using Lambda functions, or consumer applications running on EC2 and your own data centres.
They (Kinesis streams) exist as a way for you to notify others of events that has occurred in your system, and modern distributed systems are heterogeneous by design to allow for greater flexibility and the ability to choose the right tradeoff in different circumstances.
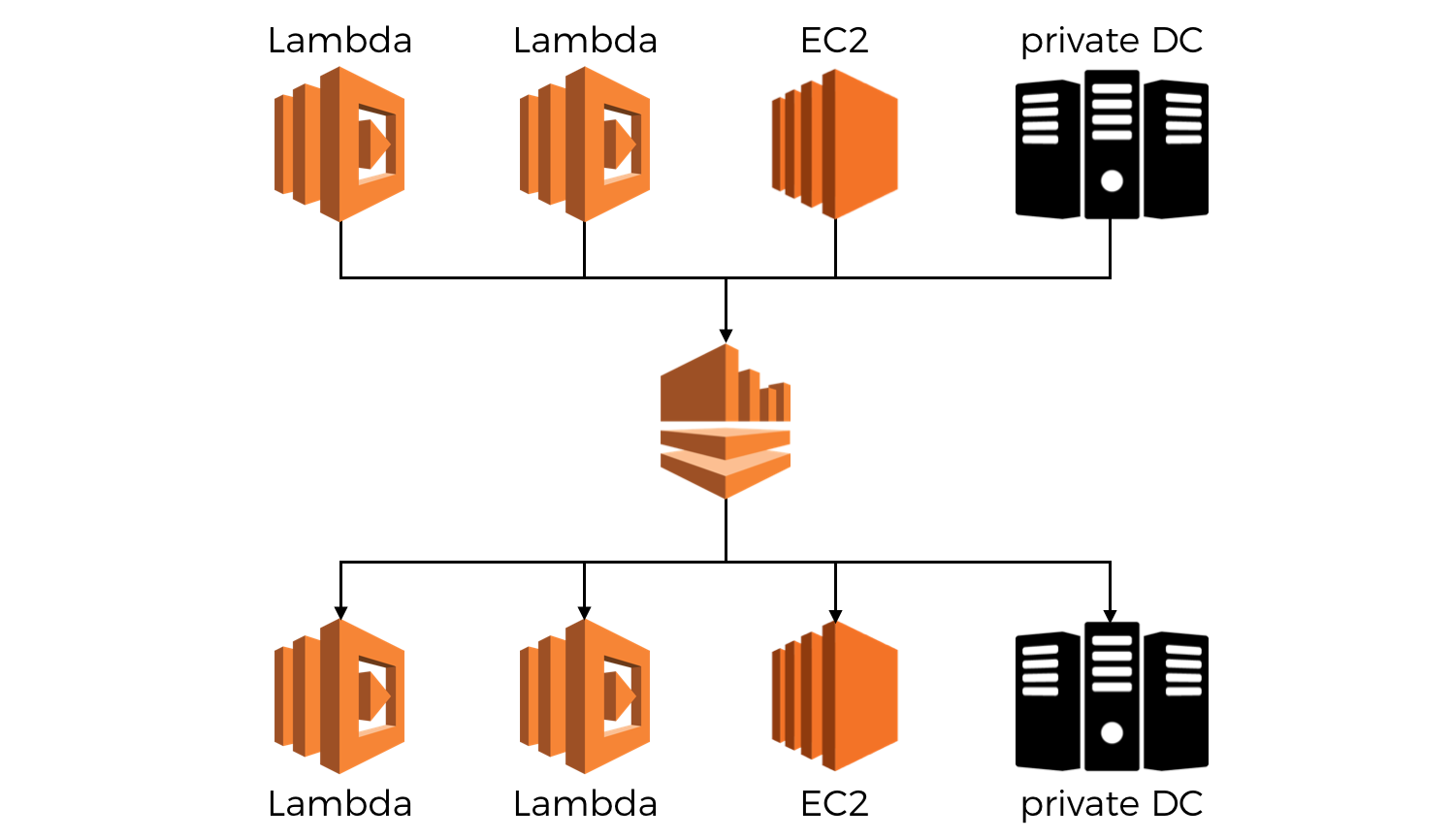
Even without the complex case of multi-producer and multi-consumer Kinesis streams, the basic question of “should the consumer or the producer own the stream” is often enough to stop us in our tracks as there doesn’t (at least not to me) seem to be a clear winner here.
One of the better ways I have seen – and have adopted myself – is to manage these shared AWS resources in a separate repository using either Terraform or CloudFormation templates depending on the expertise available in the team.
This seems to be the approach that many companies have adopted once their serverless architecture matured to the point where shared infrastructure starts to pop up.
But, on its own, it’s probably not even a good way as it introduces other problems around your workflow.
For example. if those shared resources are managed by a separate infrastructure team, then it can create bottlenecks and frictions between your development and infrastructure teams.
That said, by comparison I still think it’s better than managing those shared AWS resources with your serverless.yml for the reasons I mentioned.
If you know of other ways to manage shared infrastructure, then by all means let me know in the comments, or you can get in touch with me via twitter.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Quick note: I find the ability to protect cloud formation stacks from deletion very helpful in this context. One should do that for all their production stacks.