
Yan Cui
I help clients go faster for less using serverless technologies.

Nowadays you see plenty of stories about Continuous Integration, Continuous Delivery and Continuous Deployment on the web, and it’s great to see that the industry is moving in this direction, with more and more focus on automation rather than hiring humans to do a job that machines are so much better at.
But, most of these stories are also not very interesting because they tend to revolve around MVC-based web sites that controls both the server and the client (since the client is just the server-generated HTML) and there’s really no synchronization or backward compatibility issues between the server and the client. It’s a great place to be to not have those problems, but they are real concerns for us for reasons we’ll go into shortly.
The Netflix Way
One notable exception is the continuous deployment story from Netflix, which Carl Quinn also talked about as part of an overview of the Netflix architecture in this presentation.
For me, there are a number of things that make the Netflix continuous deployment story interesting and worth studying:
- Scale – more than 1000 different client devices and over a quarter of the internet traffic
- Aminator – whilst most of us try to avoid creating new AMIs when we need to deploy new versions of our code, Netflix has decided to go the other way and instead automate away the painful, manual steps involved with creating new AMIs and in return get better start-up time as their VMs comes pre-baked

- Use of Canary Deployment – dipping your toe in the water by routing a small fraction of your traffic to a canary cluster to test it out in the wild (it’s worth mentioning that this facility is also provided out-of-the-box by Google AppEngine)
- Red/Black push – a clever word play (and reference to the Netflix colour I presume?) on the classic blue-green deployment, but also making use of AWS’s auto-scaling service as well as Netflix’s very own Zuul and Asgard services for routing and deployment.

I’ve not heard any updates yet, but I’m very interested to see how the Netflix deployment pipeline has changed over the last 12 months, especially now that Docker has become widely accepted in the DevOps community. I wonder if it’s a viable alternative to baking AMIs and instead Aminator can be adopted (and renamed since it’s no longer baking AMIs) to bake Docker images instead which can then be fetched and deployed from a private repository.
If you have see any recent talks/posts that provides more up-to-date information, please feel free to share in the comments.
Need for Backward Compatibility
One interesting omission from all the Netflix articles and talks I have found so far has been how they manage backward compatibility issues between their server and client. One would assume that it must be an issue that comes up regularly whenever you introduce a big new feature or breaking changes to your API and you are not able to do a synchronous, controlled update to all your clients.
To illustrate a simple scenario that we run into regularly, let’s suppose that in a client-server setup:
- we have an iPhone/iPad client for our service which is currently version 1.0
- we want to release a new version 1.1 with brand spanking new features
- version 1.1 requires breaking changes to the service API

In the scenario outlined above, the server changes must be deployed before reviewers from Apple open up the submitted build or else they will find an unusable/unstable application that they’ll no doubt fail and put you back to square one.
Additionally, after the new version has been approved and you have marked it as available in the AppStore, it takes up to a further 4 hours before the change is propagated through the AppStore globally.
This means your new server code has to be backward compatible with the existing (version 1.0) client.
In our case, we currently operate a number of social games on Facebook and mobile (both iOS and Android devices) and each game has a complete and independent ecosystem of backend services that support all its client platforms.
Backward compatibility is an important issue for us because of scenarios such as the one above, which is further complicated by the involvement of other app stores and platforms such as Google Play and Amazon App Store.
We also found through experience that every time we force our players to update the game on their mobile devices we alienate and anger a fair chunk of our player base who will leave the game for good and occasionally leave harsh reviews along the way. Which is why even though we have the capability to force players to update, it’s a capability that we use only as a last resort. The implication being that in practice you can have many versions of clients all accessing the same backend service which has to maintain backward compatibility all the way through.
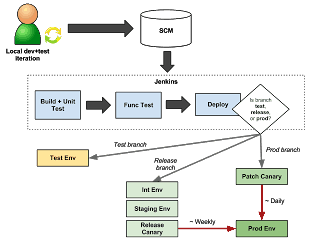
Deployment at Gamesys Social
Currently, most of our games follow this basic deployment flow:


The steps involved in releasing to production follow the basic principles of Blue-Green Deployment and although it helps eliminate downtime (since we are pushing out changes in the background whilst keeping the service running so there is no visible disruption from the client’s point-of-view) it does nothing to eliminate or reduce the need for maintaining backward compatibility.
Instead, we diligently manage backward compatibility via a combination of careful planning, communication, domain expertise and testing. Whilst it has served us well enough so far it’s hardly fool-proof, not to mention the amount of coordinated efforts required and the extra complexity it introduces to our codebase.
Having considered going down the API versioning route and the maintainability implications we decided to look for a different way, which is how we ended up with a variant of Netflix’s Red-Black deployment approach we internally refer to as..
Red-White Push
Our Red-White Push approach takes advantage of our existing discovery mechanism whereby the client authenticates itself against a client-specific endpoint along with the client build version.
Based on the client type and version the discovery service routes the client to the corresponding cluster of game servers.

With this new flow, the earlier example might look something like this instead:

The key differences are:
- instead of deploying over existing service whilst maintaining backward compatibility, we deploy to a new cluster of nodes which will only be accessed by v1.1 clients, hence no need to support backward compatibility
- existing v1.0 clients will continue to operate and will access the cluster of nodes running old (but compatible) server code
- scale down the white cluster gradually as players update to v1.1 client
- until such time that we decide to no longer support v1.0 clients then we can safely terminate the white cluster
Despite what the name suggests, you are not actually limited to only red and white clusters. Furthermore, you can still use the aforementioned Blue-Green Deployment for releases that doesn’t introduce breaking changes (and therefore require synchronized updates to both client and server).
We’re still a long way from where we want to be and there are still lots of things in our release process that need to be improved and automated, but we have come a long way from even 12 months ago.
As one of my ex-colleagues said:
“Releases are not exciting anymore”
– Will Knox-Walker
and that is the point – making releases non-events through automation.
References
Netflix – Deploying the Netflix API
Netflix – Preparing the Netflix API for Deployment
Netflix – Announcing Zuul : Edge Service in the Cloud
Netflix – How we use Zuul at Netflix
Netflix OSS Cloud Architecture (Parleys presentation)
Continuous Delivery at Netflix – From Code to the Monkeys
Continuous Delivery vs Continuous Deployment
Martin Fowler – Blue-Green Deployment
ThoughtWorks – Implementing Blue-Green Deployments with AWS
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: Metricano – simplifying application monitoring | theburningmonk.com
Pingback: QCon London 2015–Takeaways from “Service Architectures at Scale, Lessons from Google and eBay” | theburningmonk.com
Pingback: Red-White Push – Continuous Delivery at Gamesys Social – HGW XX/7
Hello. Please, can you help me? How can we use canary deployment with Spring Zuul? How can we support the versioning process with Zuul?