
Yan Cui
I help clients go faster for less using serverless technologies.

A while back I wrote about using DynamoDB TTL to implement ad-hoc scheduling. It generated some healthy debate and a few of you have mentioned alternatives including using Step Functions. So let’s take a look at some of these alternatives, starting with the simplest – using a cron job.
We will assess this approach using the same criteria laid out in the last post:
- Precision: how close to my scheduled time is the task executed? The closer, the better.
- Scale (number of open tasks): can the solution scale to support many open tasks. I.e. tasks that are scheduled but not yet executed.
- Scale (hotspots): can the solution scale to execute many tasks around the same time? E.g. millions of people set a timer to remind themselves to watch the Superbowl, so all the timers fire within close proximity to kickoff time.
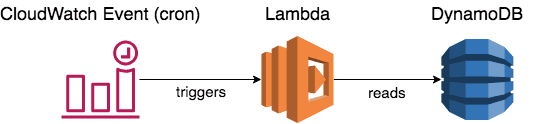
CloudWatch schedule and Lambda
The set up is very simple:
- A database (such as DynamoDB) that stores all the scheduled tasks, including when they should execute.
- A CloudWatch schedule (cron) that runs every X minutes.
- A Lambda function that reads overdue tasks from the database and executes them.
Scalability (number of open tasks)
Since the number of open tasks just translates to the number of items in the database, this approach can scale to millions of open tasks.
Precision
With CloudWatch Events, you can run a scheduled task as often as every minute. That’s the best precision you can get with this approach.
However, this approach is often constrained by the number of tasks that can be processed in each iteration. When there are too many tasks that need to be executed at the same time, they can be stacked up and cause delays. These delays are a symptom of the biggest challenge with this approach – dealing with hot spots.
Scalability (hotspots)
When the Lambda function executes, it would look for tasks that are at or past their scheduled execution time. For example, the time now is 00:00 UTC, our function would find tasks whose scheduled_time is <= 00:00 UTC.
What happens if it finds too many tasks that it can’t complete the current cycle before the next cycle kicks off at 00:01 UTC? To avoid the same task being executed more than once, often we’d set the function’s Reserved Concurrency to 1. This ensures that at any moment in time, only one instance of our Lambda function is running.
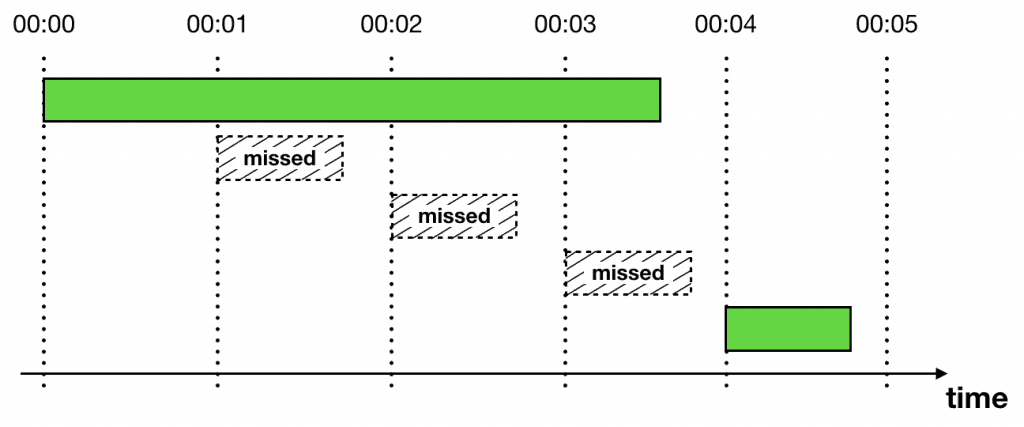
However, this means tasks that are scheduled for 00:02 UTC is not processed until the first batch is complete (see above). This can create unpredictable delays and can significantly impact the precision of the system.
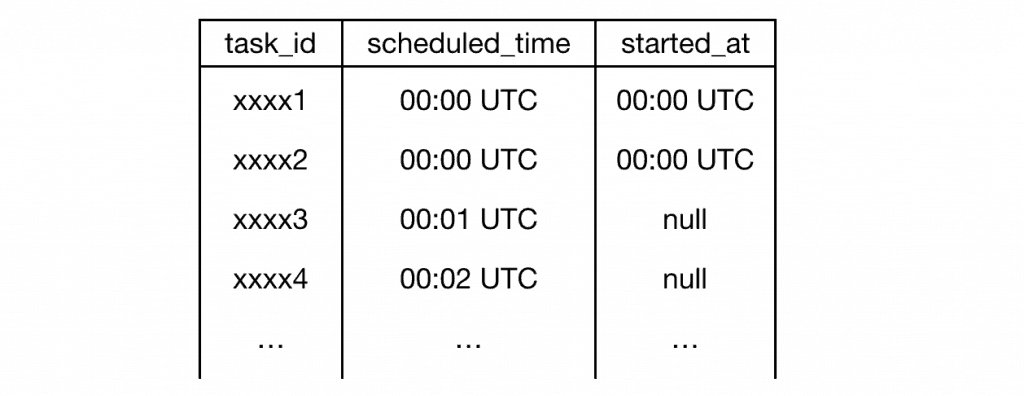
Alternatively, if you can mark a task as having started then you can prevent subsequent cycles from picking it up again except in failure cases. One such scheme might be to add a started_at attribute to the task definitions. When the cron function looks for tasks to execute, it’ll ignore tasks that are started but have not yet completed or timed out.
Doing this would allow you to run multiple instances of the cron function without risking processing a task more than once.
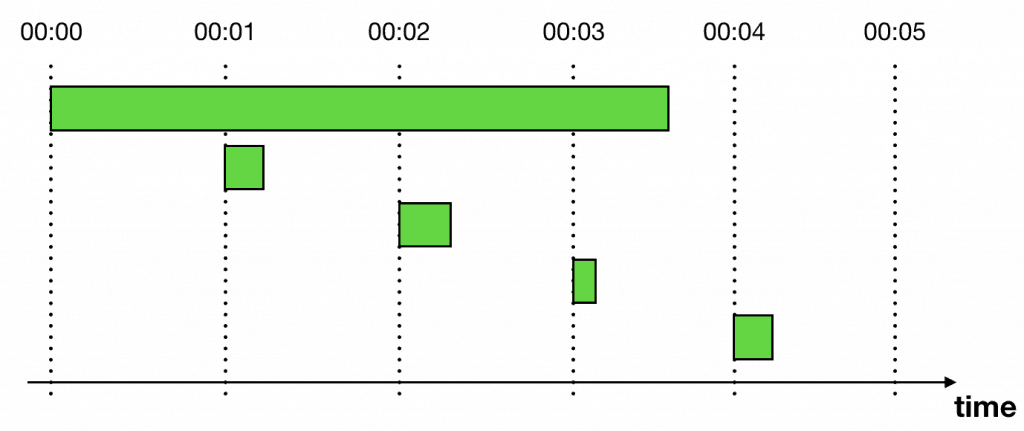
But that still leaves the issue that hotspots can cause some real damage:
- The function can timeout before it’s able to process the entire batch
- The precision of the system is highly unpredictable. If a function takes the full 15 mins to process the batch then some tasks will be executed 15 mins after their scheduled time.
Of course, you can process the tasks in parallel inside your code. But that adds complexity to your business logic and has other failure modes such as:
- Out of memory exception – if you start too many concurrent
Promise(in Node) or threads then you can hit the dreadedOutOfMemoryExceptionat runtime. Promise.allin Node.js would reject if any of the individual promises rejects. If you have an unhandled exception then it can reject all other promises, without knowing if which would have succeeded in the end.
Personally, I think a better approach would be to hand off the tasks to a SQS queue instead. This SQS queue can trigger another Lambda function.
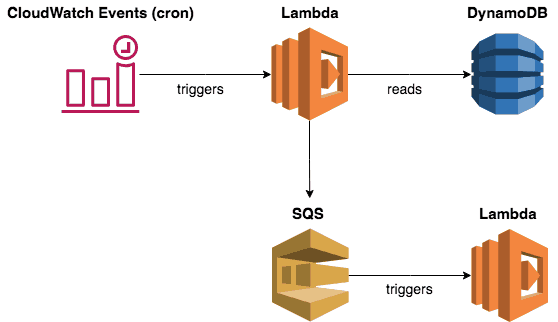
With SQS, you have built-in retry and dead letter queue (DLQ) support. The Lambda function would process SQS tasks in batches (of up to 10). The Lambda service would also auto-scale the number of concurrent executions based on traffic. Both characteristics would help you with throughput.
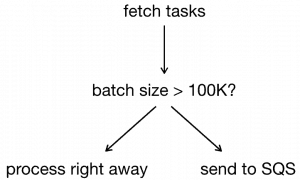
However, since this is an extra hop it will add delay to tasks being executed on time. Which impacts the precision of the system. So, maybe you don’t do this all the time. Instead, process the batch right away if the batch is small. Only when the batch is over a certain size, then defer processing through a SQS queue.
Database choice
I used DynamoDB in all the examples in this post because it’s easy to use and would suffice for many use cases. However, it’s not great at dealing with hot keys. Unfortunately, that’s exactly what we’d be doing here…
You are constraint by the limit of 3000 read throughput units per partition. So if your system needs to scale to more than a few thousand tasks per batch then DynamoDB is probably not for you.
Conclusions
This batch-based approach is not considered modern. But for many use cases, it’s also the simplest way to schedule ad-hoc tasks.
For instance, if your use case is such that:
- You can tolerate tasks being executed several minutes late.
- Tasks are evenly distributed across the day, and unlikely to form hotspots.
Then this approach of using a CloudWatch schedule and Lambda is likely sufficient for your needs. Even if you’re going to experience some hotspots, there are ways to mitigate them to a degree. As we discussed in this post, there are several things you can do to increase your throughput:
- You can track the status of the tasks. This allows multiple instances of the cron function to overlap.
- You can offload the tasks to SQS first. This lets you leverage the batching and parallelism support you get with SQS and Lambda. And you also get DLQ support for free as well.
I hope you have enjoyed this post, as part of this series we will discuss several other approaches to scheduling ad-hoc tasks. Watch this space ;-)
Read about other approaches
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.