
Yan Cui
I help clients go faster for less using serverless technologies.

CloudWatch Events let you easily create cron jobs with Lambda. However, it’s not designed for running lots of ad-hoc tasks, each to be executed once, at a specific time. The default limit on CloudWatch Events is a lowly 100 rules per region per account. It’s a soft limit, so it’s possible to request a limit increase. But the low initial limit suggests it’s not designed for use cases where you need to schedule millions of ad-hoc tasks.
CloudWatch Events is designed for executing recurring tasks.

The Problem
It’s possible to do this in just about every programming language. For example, .Net has the Timer class and JavaScript has the setInterval function. But I often find myself wanting a service abstraction to work with. There are many use cases for such a service, for example:
- A tournament system for games would need to execute business logic when the tournament starts and finishes.
- An event system (think eventbrite.com or meetup.com) would need a mechanism to send out timely reminders to attendees.
- A to-do tracker (think wunderlist) would need a mechanism to send out reminders when a to-do task is due.
However, AWS does not offer a service for this type of workloads. CloudWatch Events is the closest thing, but as discussed above it’s not intended for the use cases above. You can, however, implement them using cron jobs. But such implementations have other challenges.
I have implemented such service abstraction a few times in my career already. I experimented with a number of different approaches:
- cron job (with CloudWatch Events)
- wrapping the .Net
Timerclass as an HTTP endpoint - using SQS Visibility Timeout to hide tasks until they’re due
And lately I have seen a number folks use DynamoDB Time-To-Live (TTL) to implement these ad-hoc tasks. In this post, we will take a look at this approach and see where it might be applicable for you.
How do we measure the approach?
For this type of ad-hoc tasks, we normally care about:
- Precision: how close to my scheduled time is the task executed? The closer the better.
- Scale (number of open tasks): can the solution scale to support many open tasks. I.e. tasks that are scheduled but not yet executed.
- Scale (hotspots): can the solution scale to execute many tasks around the same time? E.g. millions of people set timer to remind themselves to watch the superbowl, so all the timers fire within close proximity to kickoff time.
DynamoDB TTL as a scheduling mechanism
From a high level this approach looks like this:
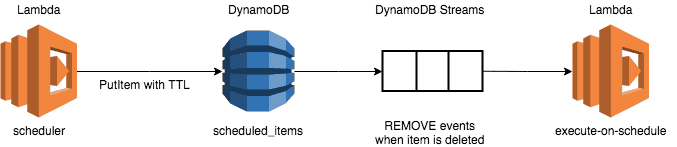
- A
scheduled_itemsDynamoDB table which holds all the tasks that are scheduled for execution. - A
schedulerfunction that writes the scheduled task into thescheduled_itemstable, with the TTL set to the scheduled execution time. - A
execute-on-schedulefunction that subscribes to the DynamoDB Stream forscheduled_itemsand react toREMOVEevents. These events corresponds to when items have been deleted from the table.
Scalability (number of open tasks)
Since the number of open tasks just translates to the number of items in the scheduled_items table, this approach can scale to millions of open tasks.
DynamoDB can handle large throughputs (thousands of TPS) too. So this approach can also be applied to scenarios where thousands of items are scheduled per second.
Scalability (hotspots)
When many items are deleted at the same time, they are simply queued in the DynamoDB Stream. AWS also autoscales the number of shards in the stream, so as throughput increases the number of shards would go up accordingly.
But, events are processed in sequence. So it can take some time for your function to process the event depending on:
- its position in the stream, and
- how long it takes to process each event.
So, while this approach can scale to support many tasks all expiring at the same time, it cannot guarantee that tasks are executed on time.
Precision
This is the big question about this approach. According to the official documentation, expired items are deleted within 48 hours. That is a huge margin of error!

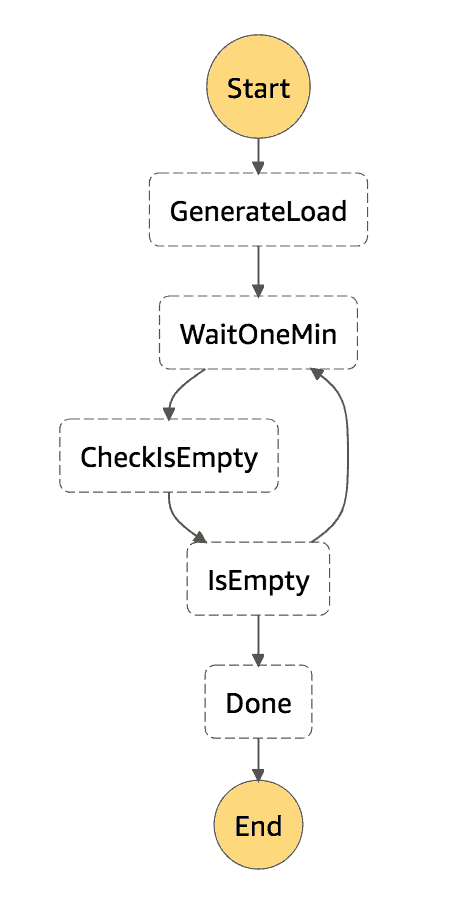
As an experiment, I set up a Step Functions state machine to:
- add a configurable number of items to the
scheduled_itemstable, with TTL expiring between 1 and 10 mins - track the time the task is scheduled for and when it’s actually picked up by the
execute-on-schedulefunction - wait for all the items to be deleted
The state machine looks like this:
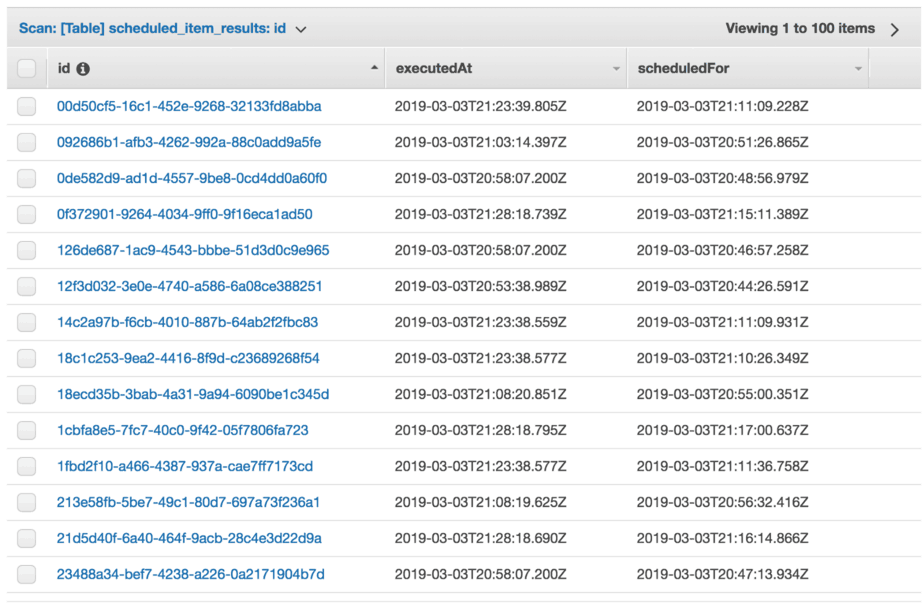
I performed several runs of tests. The results are consistent regardless the number of items in the table. A quick glimpse at the table tells you that, on average, a task is executed over 11 mins AFTER its scheduled time.
I repeated the experiments in several other AWS regions:
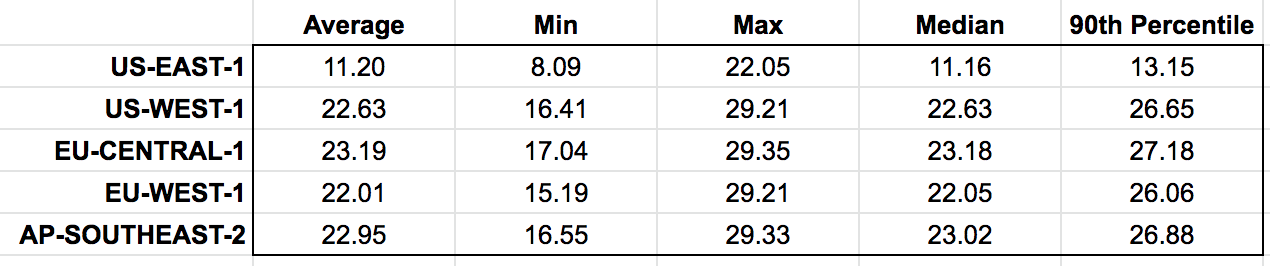
I don’t know why there are such marked difference between US-EAST-1 and the other regions. One explanation is that the TTL process requires a bit of time to kick in after a table is created. Since I was developing against the US-EAST-1 region initially, its TTL process has been “warmed” compared to the other regions.
Conclusions
Based on the result of my experiment, it will appear that using DynamoDB TTL as a scheduling mechanism cannot guarantee a reasonable precision.
On the one hand, the approach scales very well. But on the other, the scheduled tasks are executed at least severals minutes behind, which renders it unsuitable for many use cases.
Read about other approaches
- Using CloudWatch and Lambda to implement ad-hoc scheduling
- Step Functions as an ad-hoc scheduling mechanism
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.