
Yan Cui
I help clients go faster for less using serverless technologies.

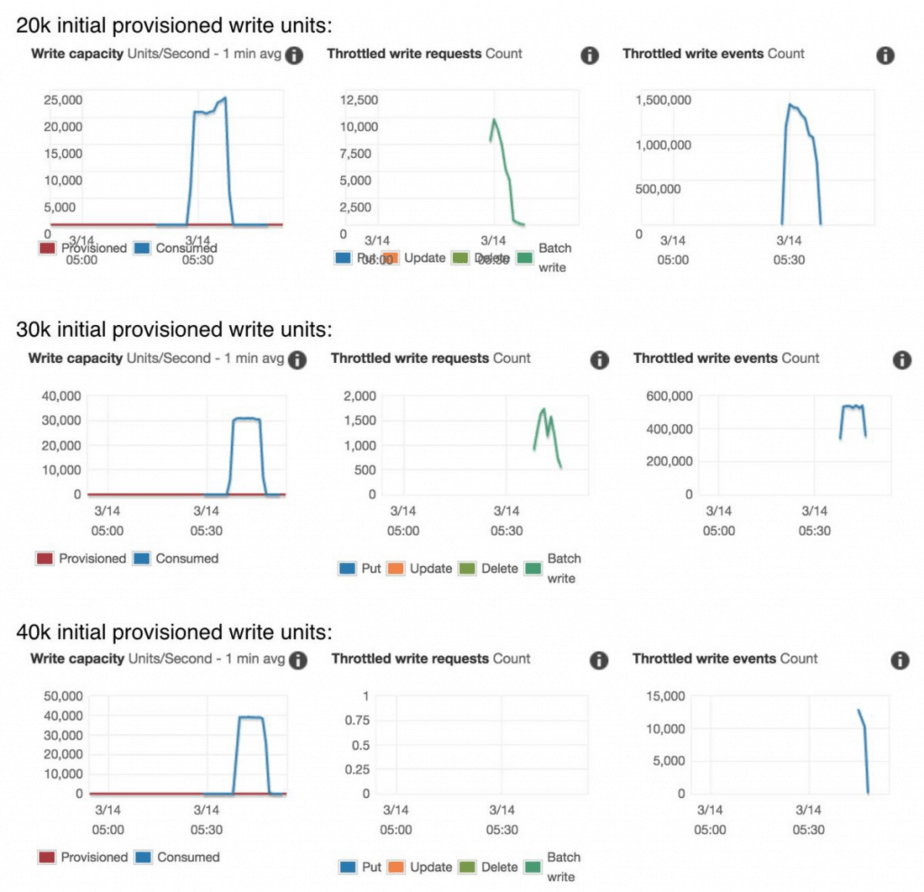
Update 15/03/2019: Thanks to Zac Charles who pointed me to this new page in the DynamoDB docs. It explains how the OnDemand capacity mode works. Turns out you DON’T need to pre-warm a table. You just need to create the table with the desired peak throughput (Provisioned), and then change it to OnDemand. After you change the table to OnDemand it’ll still have the same throughput.
To confirm this behaviour, I ran a few more experiments:
- create a table with 20k/30k/40k provisioned write throughput
- change the table to OnDemand
- apply 40k writes/s traffic to the table right away
The result confirms the aforementioned behaviour.
At re:invent 2018, AWS also announced DynamoDB OnDemand. DynamoDB OnDemand tables have different scaling behaviour, which promises to be far superior to DynamoDB AutoScaling.

Talking with a few of my friends at AWS, the consensus is that “AWS customers no longer need to worry about scaling DynamoDB”! So I ran a number of experiments to help me understand how OnDemand tables deal with sudden spikes in traffic.
From 0 to 4000, no problem!
Let’s assume that a newly created table can handle X amount of read/write throughput before it needs to scale. We can find out the value of X by:
- create a new table
- generate a traffic that ramps up to Y writes/s throughput in one minute (using UUIDs as keys to avoid hotspots)
- observe the throughput at which writes are throttled
To help me quickly find the threshold, I used Step Functions to test different values of Y (i.e. peak throughput): 100, 200, 300, 500, 700, 900, 1100, 1300, 1500, 1750, 2000, 2500, 3000, 5000, 7000, and 9000.

For every value of Y up to 3000, there were no throttled writes. But I was not able to perform more than 4000 writes/s.
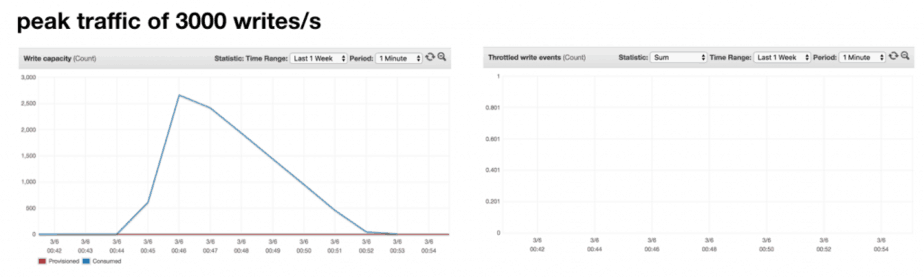
The conclusion is that, a newly created table can handle 4000 writes/s without any throttling.
Table handles previously CONSUMED peak & more
From the announcement post by Danilo, one paragraph piqued my curiosity in particular.

Is the adaptive behaviour similar to DynamoDB AutoScaling and calculate the next threshold based on the previous peak Consumed Capacity? I explained the problem with this approach in my previous post – the threshold should be based on the throughput you wanted to execute (consumed + throttled), not just what you succeeded with (consumed).
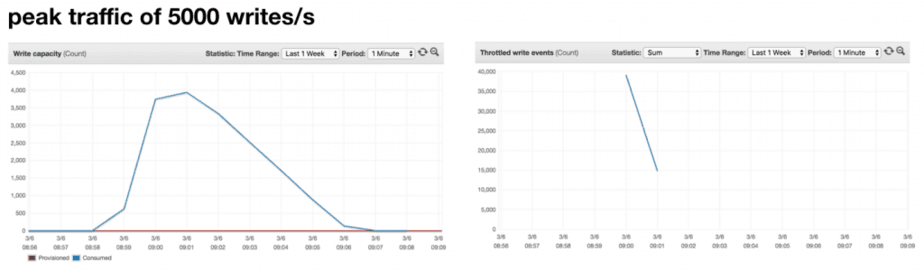
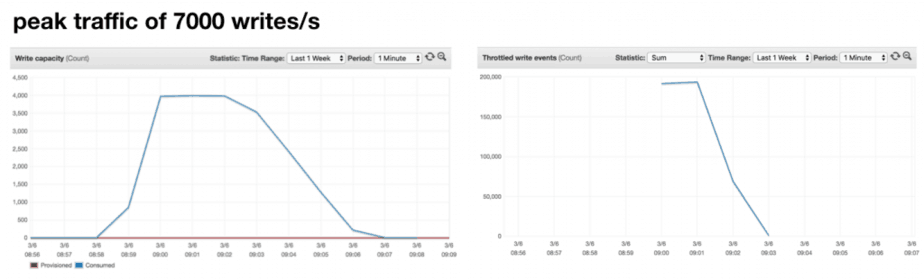
With this question in mind, I reran the experiment for peak traffic of 9000 writes/s. As you can see from the diagrams below, the table’s threshold has been raised to around 7000 writes/s.
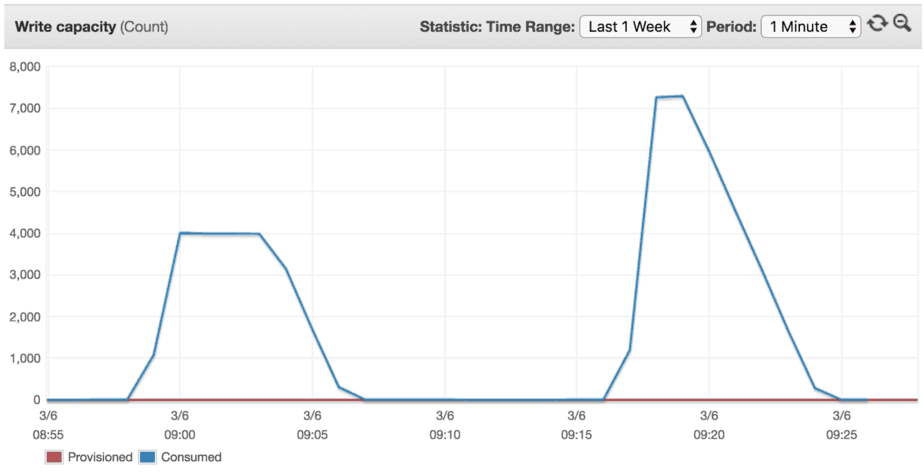
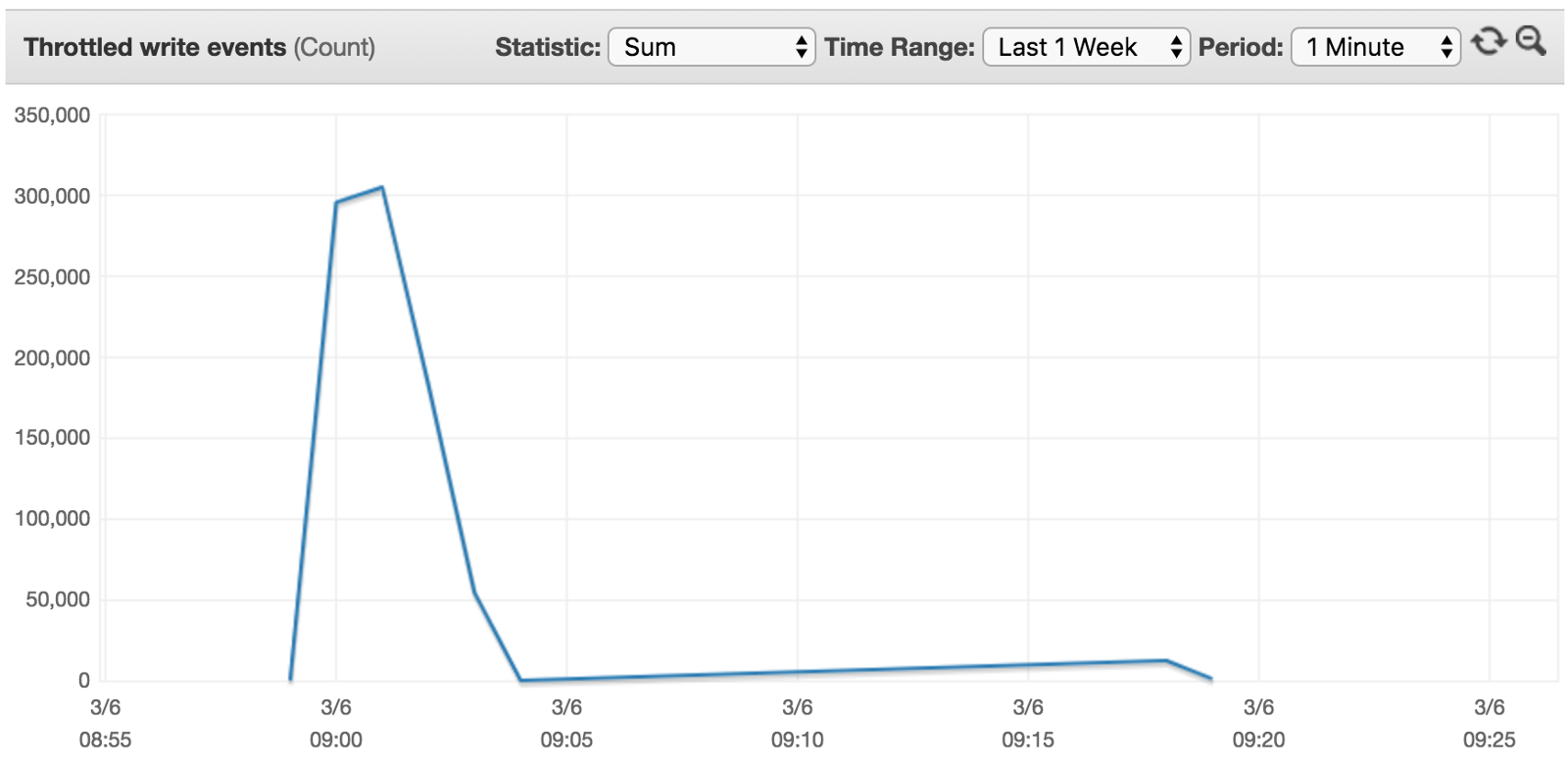
The good news is that, the table scaled to support throughput higher than the previous peak Consumed Capacity. The bad news is that it didn’t adapt to our desired throughput of 9000 writes/s so we still experienced some throttling.
The road to 40k writes/s
I ran another experiment to see how quickly a new table can scale to 40,000 writes/s and the steps it took.
For this experiment, I had to use a different Step Functions state machine. Using DynamoDB BatchWrites, I was able to achieve around 10,000 writes/s from a 1GB Lambda function. So to generate 40,000 writes/s I needed to run multiple instance of this function in parallel.
The new state machine looks like this.

As you can see from the result, it took roughly one hour to scale the table to meet our throughput demand of 40,000 writes/s.
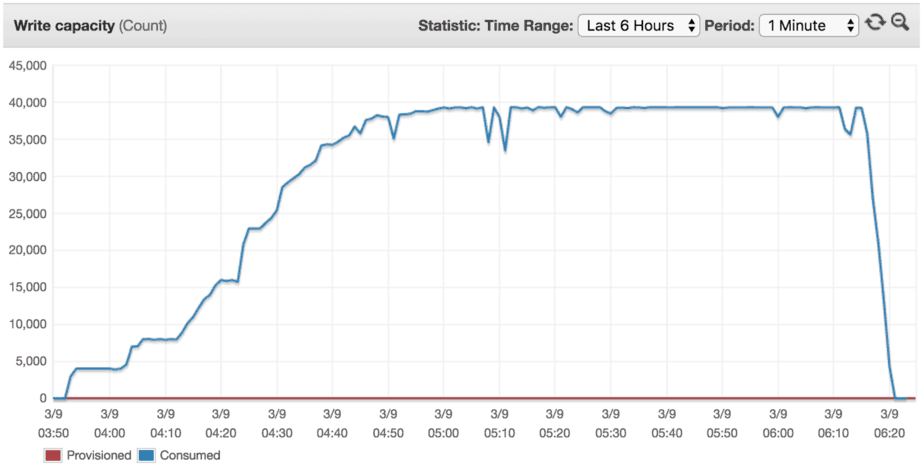
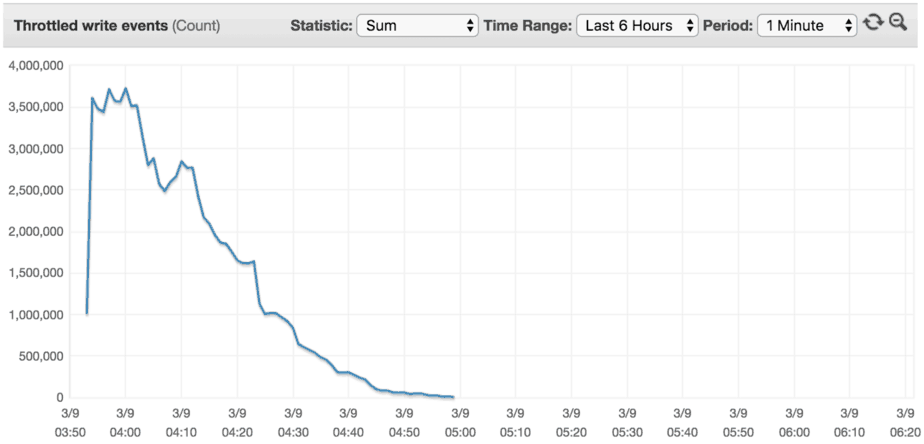
Afterwards, we’ll be able to achieve 40,000 writes/s against this table without any problems.
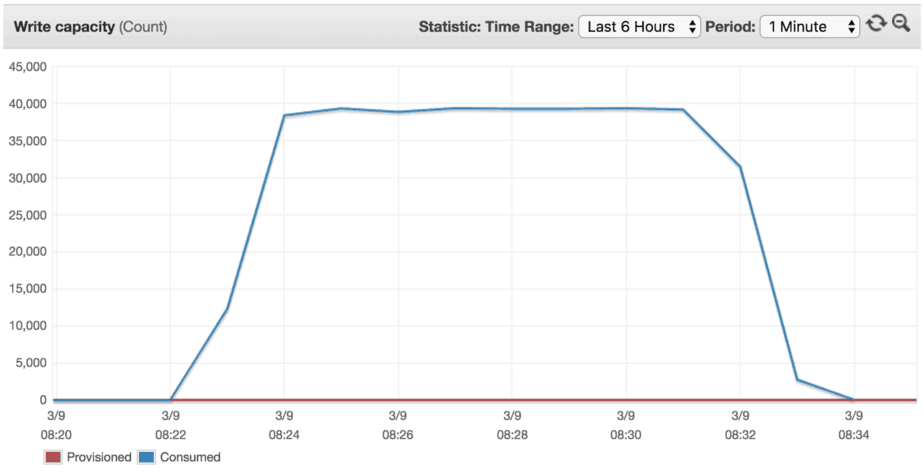
This behaviour opens up an interesting possibility.
Most DynamoDB table would never experience a spike of more than 4000 writes/s. For those that do, you can also “pre-warm” the table to your target peak throughput. After pre-warming the table, it would be able to handle your desired peak throughput.
The road to 40k writes/s, slowly…
What if the traffic ramps up to 40,000 writes/s steadily instead? I ran a series of experiments to find out.
0 to 40k in 60 mins (1 hour)
In this case, the traffic increases steady over the course of an hour until it reached 40,000 writes/s. As you can see from the results below, the rate of progression is too fast for the OnDemand table to adapt to on the fly. As a result we incurred a lot of throttled write events along the way.
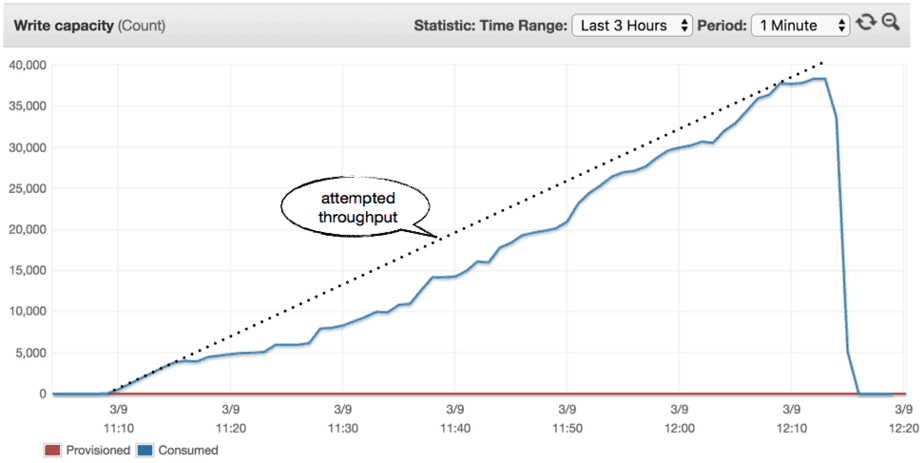
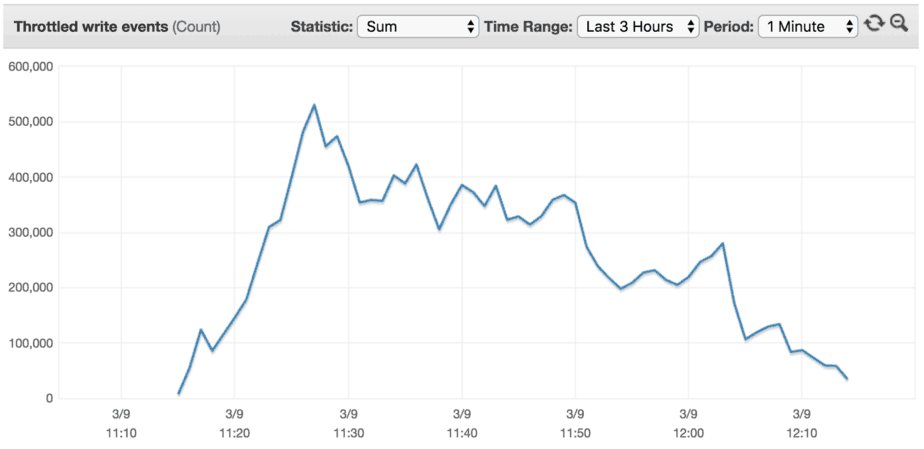
0 to 40k in 90 mins (1:30 hours)
Rerunning the experiment and slowing up the rate of progression shows improved results. But we still experienced a lot of throttling.
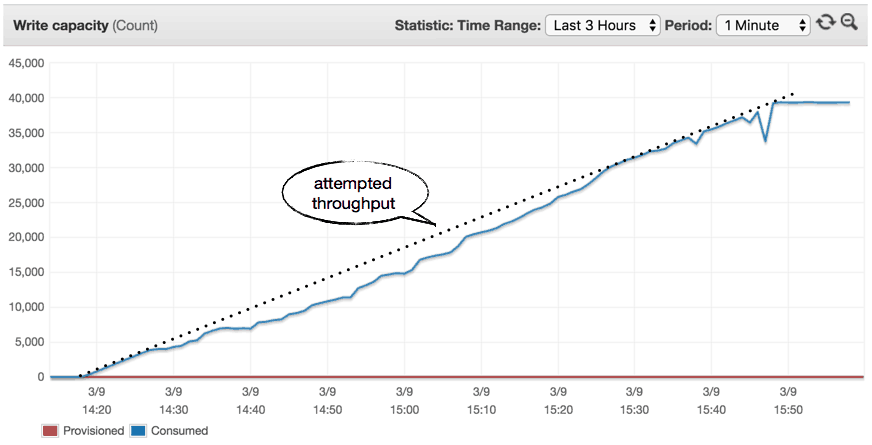
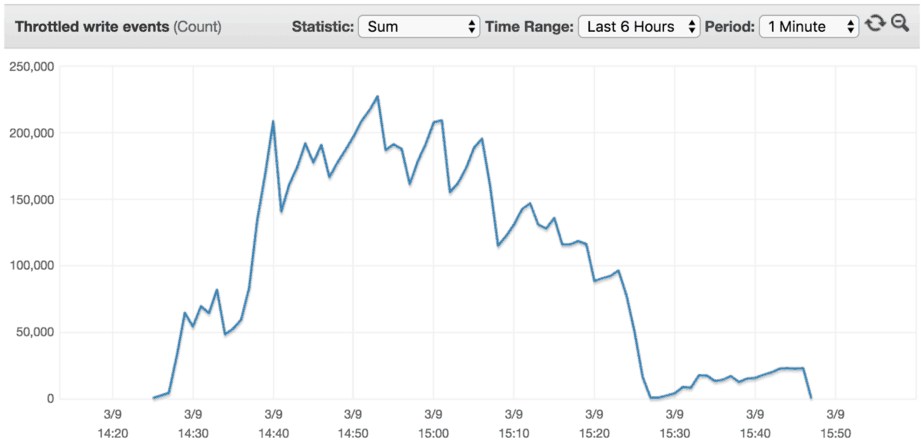
0 to 40k in 120 mins (2 hours)
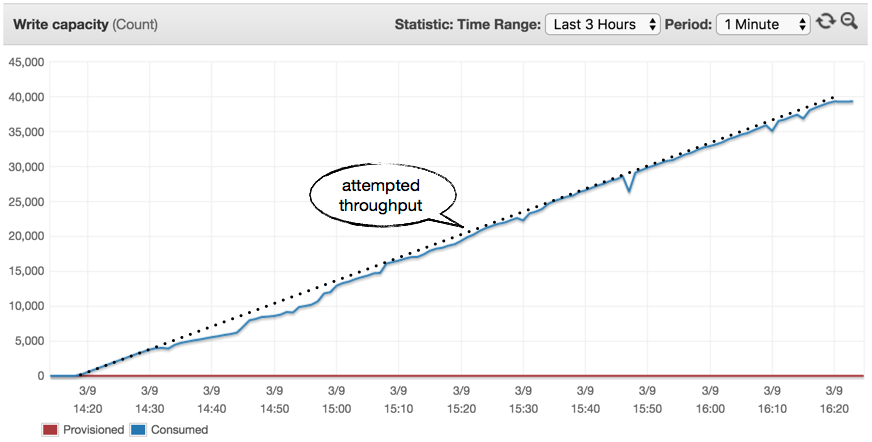
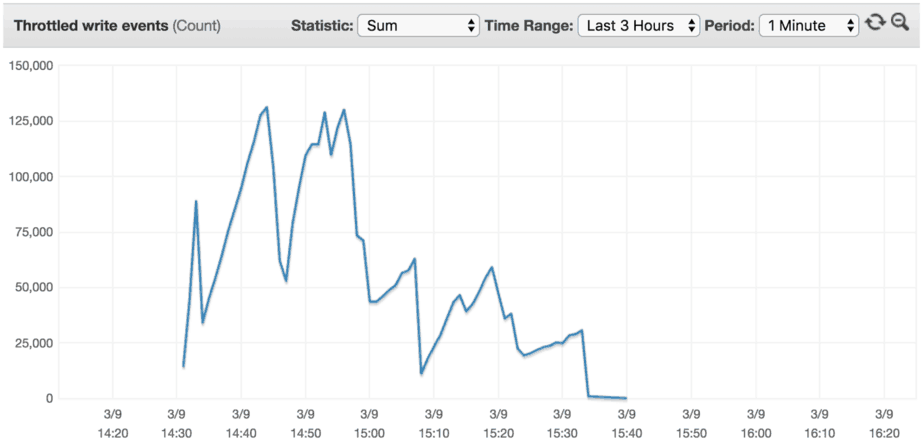
0 to 40k in 150 mins (2:30 hours)
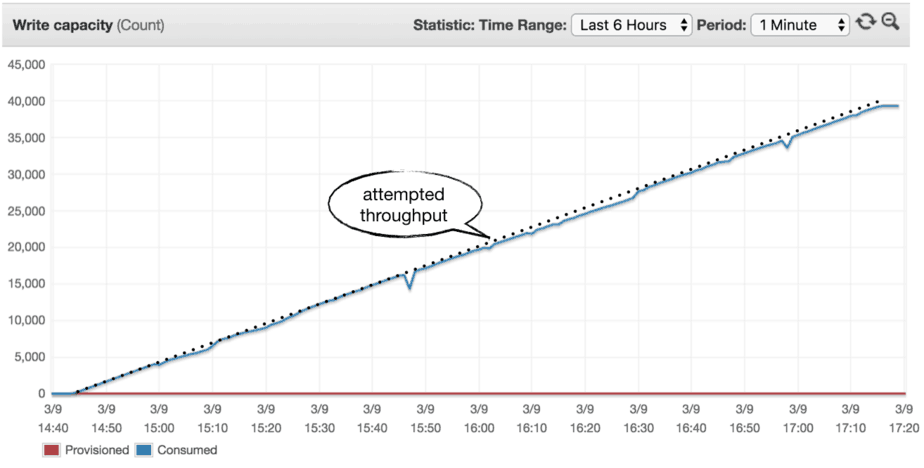
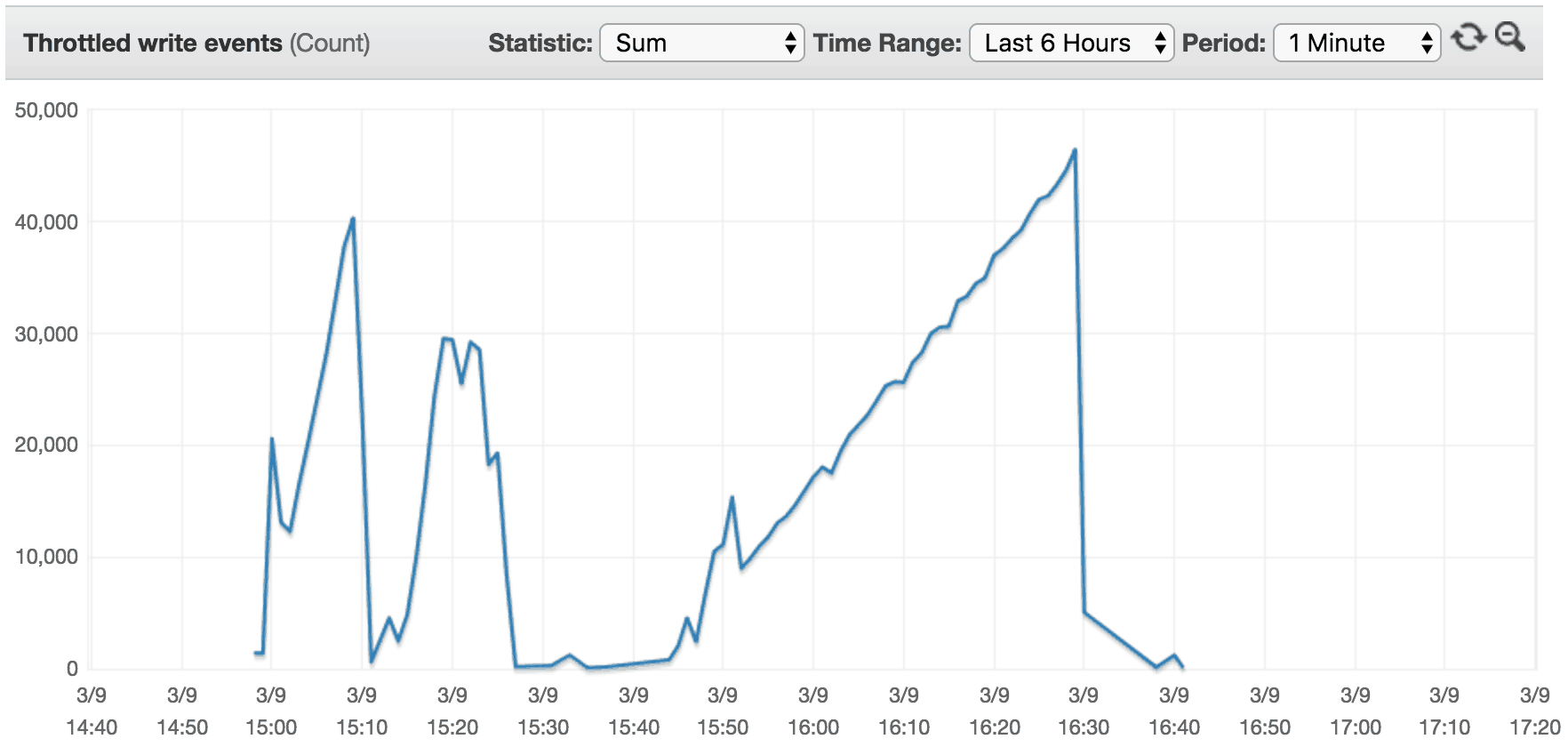
As we slowed down the rate the throughput goes up, we experienced less and less throttling along the way. One would assume that there is a rate of progression, Z, where the throughput increases slowly enough that there will be no throttling.
What about costs?
A lot have been made about the fact that OnDemand tables are more expensive per request. A rough estimate suggests it’s around 5–6 times more expensive per request compared to a provisioned table.
While that is the case, my experience with DynamoDB is that most tables are poorly utilized. A quick look at our DynamoDB tables in production paints a familiar picture. Despite the occasional spikes, tables are using less than 10% of the provisioned throughput on average.
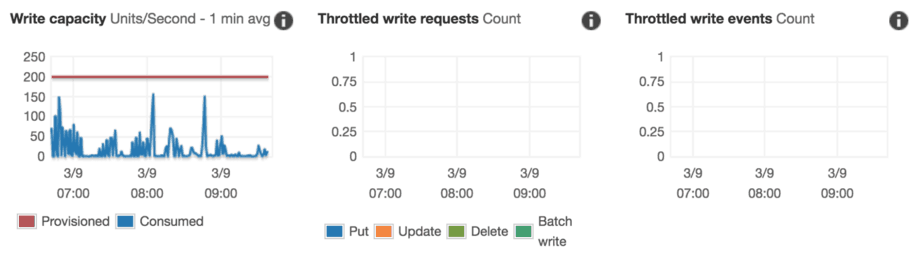
And it’s not hard to find even worse offenders.
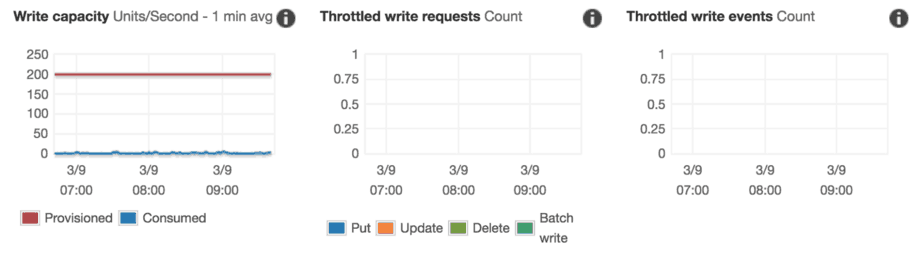
The bottom line is, we are terrible at managing DynamoDB throughputs! There are so much waste in reserved throughputs that, even with a hefty premium per request for OnDemand tables we will still end up with a huge saving overall.
Experiments are good!
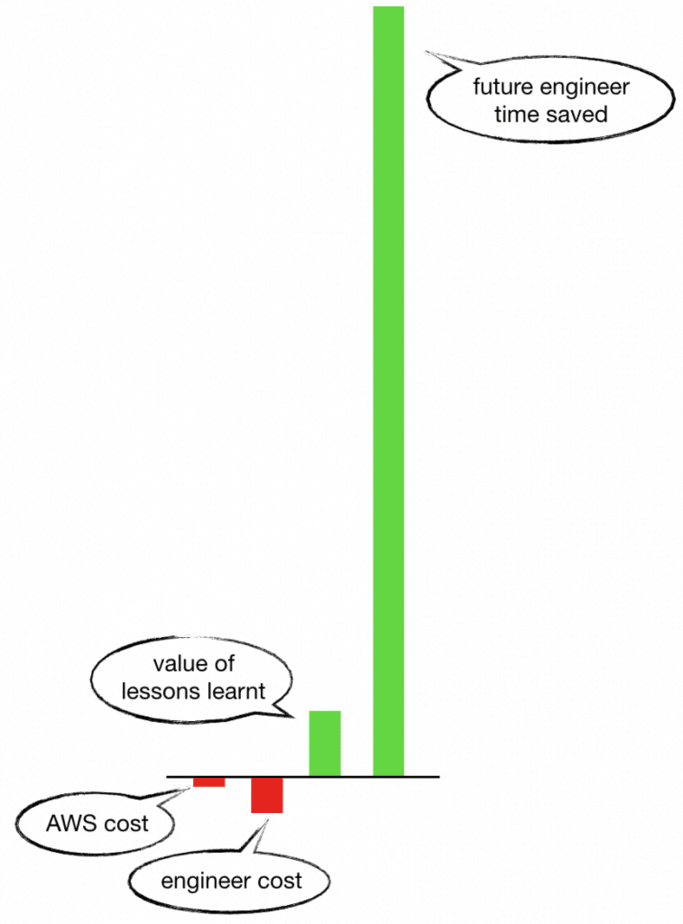
As a side, all these experiments cost us a total of $271.61 for over 217 million write requests.
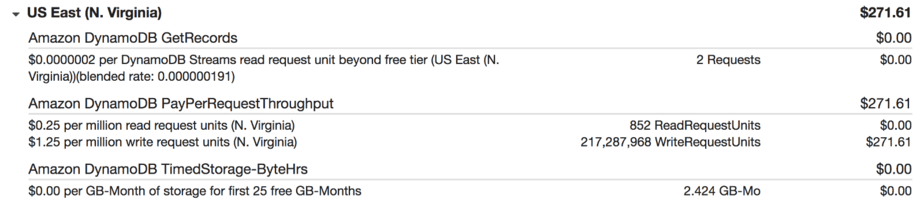
In the grand scheme of things, this is insignificant. The cost of the engineering time (my time!) to conduct, analyze and summarise the results of these experiments is far greater.
But even beyond that, the value of lessons we learnt is far greater. We now have the confidence to use OnDemand tables for anything that has a peak throughput of less than 4000 per second. Which means:
- less work for our engineers from an infrastructure-as-code perspective
- no need for capacity planning (in most cases)
The productivity saving this simple experiment creates for us makes the AWS cost look like peanuts! The moral of the story? Be curious, ask questions, experiment, and share your learnings with the community.
Summary
In summary:
- You should default to DynamoDB OnDemand tables unless you have a stable, predictable traffic.
- OnDemand tables can handle up to 4000
Consumed Capacityout of the box, after which your operations will be throttled. - OnDemand tables would auto-scale based on the
Consumed Capacity. - Once scaled, you can reach the same throughput again in the future without throttling.
- You should consider pre-warming OnDemand tables that need to handle spikes of more than 4000
Consumed Capacityto avoid initial throttling.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.