
Yan Cui
I help clients go faster for less using serverless technologies.

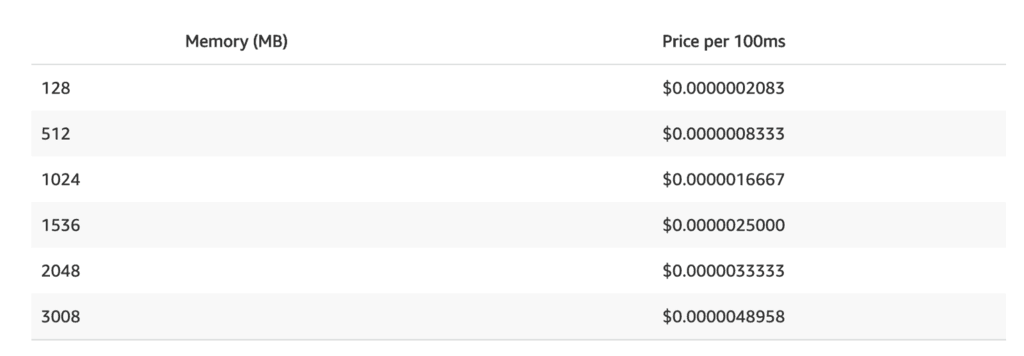
Lambda invocations are charged in 100ms blocks of execution time. But the cost per 100ms of execution time depends on how much memory you allocate to the function. The higher the memory, the more CPU cycles and network bandwidth, but the higher the cost as well.
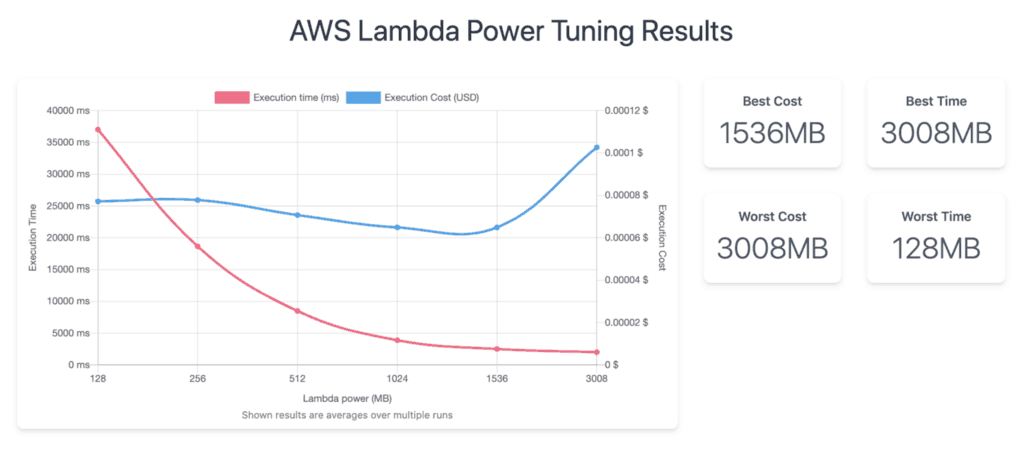
One of the simplest and most efficient cost optimization for Lambda is to right-size the memory allocation for your functions. It used to be a dark art that requires plenty of trial-and-error, until the aws-lambda power-tuning app from Alex Casalboni. Which uses Step Functions to execute your function against different memory sizes to help you find the best configuration for speed, cost or a balance of the two.
However, managing the deployment of the aws-lambda-power-tuning app (which is available via the Serverless Application Repository) is an extra overhead that most of us rather do without. Not to mention the headache of keeping it up-to-date whenever Alex releases new features.
So, to make power tuning functions more accessible, I added support for it in the lumigo-cli. You can tune a function with a simple command lumigo-cli powertune-lambda -r us-east-1 -n my-function --strategy balanced .

Since version 0.39.0 of the lumigo-cli, it’s now even easier to integrate it with CI/CD pipelines. Because I added support for storing the output of the app (see below) into a local file, so they can be easily parsed, and the ability to suppress the command line prompt to visualize the result.
{
"power": 512,
"cost": 8.32e-7,
"duration": 15.411500000000002,
"stateMachine": {
"executionCost": 0.0003,
"lambdaCost": 0.001075983999999999,
"visualization": "https://lambda-power-tuning.show/..."
}
}
Check out this repo for a demo project that automatically tunes its functions as part of its CI/CD pipeline. Let’s walk through it.
The setup
The demo project uses the Serverless framework to configure and deploy its functions. But the same approach works with other deployment frameworks too. The important thing to note is that we have three functions:
functions:
cpu-intense:
handler: functions/cpu-intense.handler
io-intense:
handler: functions/io-intense.handler
events:
- http:
path: /
method: POST
mixed:
handler: functions/mixed.handler
By default, the Serverless framework configures functions with 1024MB of memory and 6 seconds timeout.
In the project root, there is an examples folder. This is where you put the example payloads to use when tuning each of the functions.
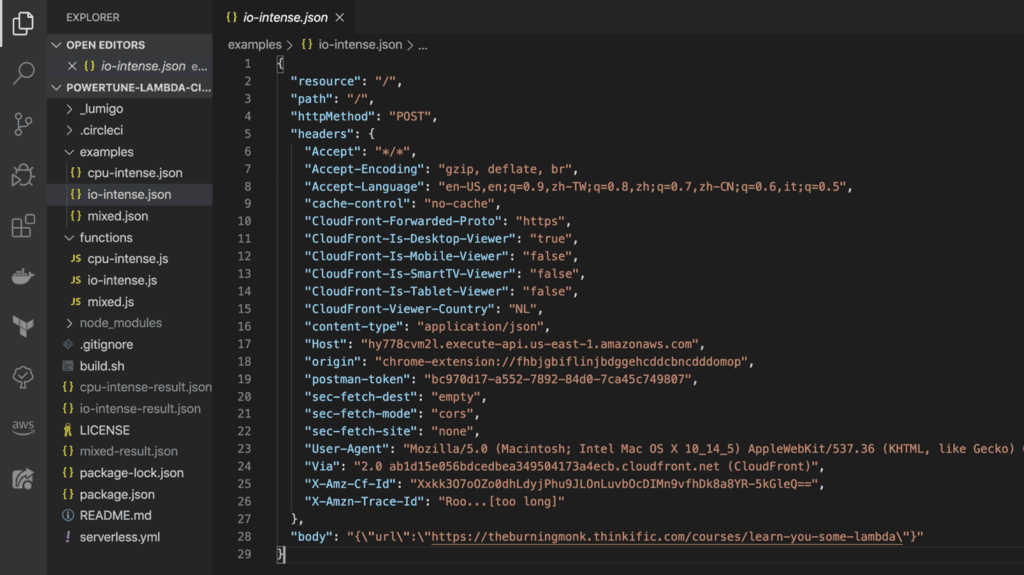
There is also a build.sh script, where much of the magic happens during the CI/CD pipeline.
The build.sh script
As part of my projects, I usually include a build.sh script. This script encapsulates the key steps for my CI/CD pipelines, such as running tests and deploying the project. It simplifies the process of testing my CI/CD pipelines since I can easily run it locally. And it allows me to move between CI tools easily since the “meat” of the pipeline is in the scripts.
When adopted broadly, it gives you a DSL for all of your projects, e.g.
./build.sh deploy dev us-east-1to deploy the project to thedevstage in theus-east-1region./build.sh int-test dev us-east-1to run the integration tests in thedevstage, against theus-east-1region./build.sh e2e-test dev us-east-1to run the end-to-end tests in thedevstage, against theus-east-1region- and so on…
In this particular case, I have a command to tune the functions in this project to a strategy of my choosing – cost, speed or balanced. For example, by running ./build.sh tune dev us-east-1 balanced .
#!/bin/bash
set -e
set -o pipefail
INSTRUCTION="If you want to deploy, try running the script with 'deploy stage region', e.g. 'deploy dev eu-west-1'"
function tune_function {
functionName=powertune-lambda-cicd-demo-$2-$3
echo ""
echo "$functionName:"
echo ""
echo "running 'lumigo-cli powertune-lambda'..."
lumigo-cli powertune-lambda \
-r $1 \
-n $functionName \
-s $4 \
-f examples/$3.json \
-o $3-result.json \
-z > /dev/null
optimalPower=`cat $3-result.json | jq -r '.power'`
echo "optimal power for is $optimalPower MB"
memorySize=`aws lambda get-function-configuration --region $1 --function-name $functionName | jq -r '.MemorySize'`
echo "current memory size is $memorySize MB"
if ((optimalPower != memorySize)); then
echo "updating function memory size to $optimalPower..."
aws lambda update-function-configuration --region $1 --function-name $functionName --memory-size $optimalPower > /dev/null
fi
echo ""
echo "-----------------------------"
}
if [ $# -eq 0 ]; then
echo "No arguments found."
echo $INSTRUCTION
exit 1
elif [ "$1" = "deploy" ] && [ $# -eq 3 ]; then
STAGE=$2
REGION=$3
npm install
npm run sls -- deploy -s $STAGE -r $REGION
elif [ "$1" = "tune" ] && [ $# -eq 4 ]; then
STAGE=$2
REGION=$3
STRATEGY=$4
tune_function $REGION $STAGE "cpu-intense" "balanced"
tune_function $REGION $STAGE "io-intense" "balanced"
tune_function $REGION $STAGE "mixed" "balanced"
else
echo $INSTRUCTION
exit 1
fi
This command can be run AFTER the functions have been deployed. As you can see, it uses the lumigo-cli to tune each of the functions.
lumigo-cli powertune-lambda \ -r $1 \ -n $functionName \ -s $4 \ -f examples/$3.json \ -o $3-result.json \ -z > /dev/null
Couple of things to note here:
- the input file (
-f) points to the aforementionedexamplesfolder. The input files need to be named after the names of the functions in theserverless.yml. In this case,cpu-intense.json,io-intense.jsonormixed.json. - the output file (
-o) would be named after the same function name too. - the
-zflag suppresses the command line prompt where thelumigo-cliasks you if you want to see a visualization of the results.
The io-intense function (see below) is an API Gateway function and extracts the url from the POST body. So, to tune this function we need to invoke it with a payload that looks like an API Gateway event.
const https = require('https')
module.exports.handler = (event, context, callback) => {
const { url } = JSON.parse(event.body)
https.get(url, (res) => {
console.log('statusCode:', res.statusCode)
callback(null, {
statusCode: 200,
body: "{}"
})
}).on('error', (e) => {
console.error(e)
})
}
Similar, if you have functions that process events from SNS, SQS, Kinesis and so on, you would need to tailor the payload for each. Hence the purpose of the examples folder.
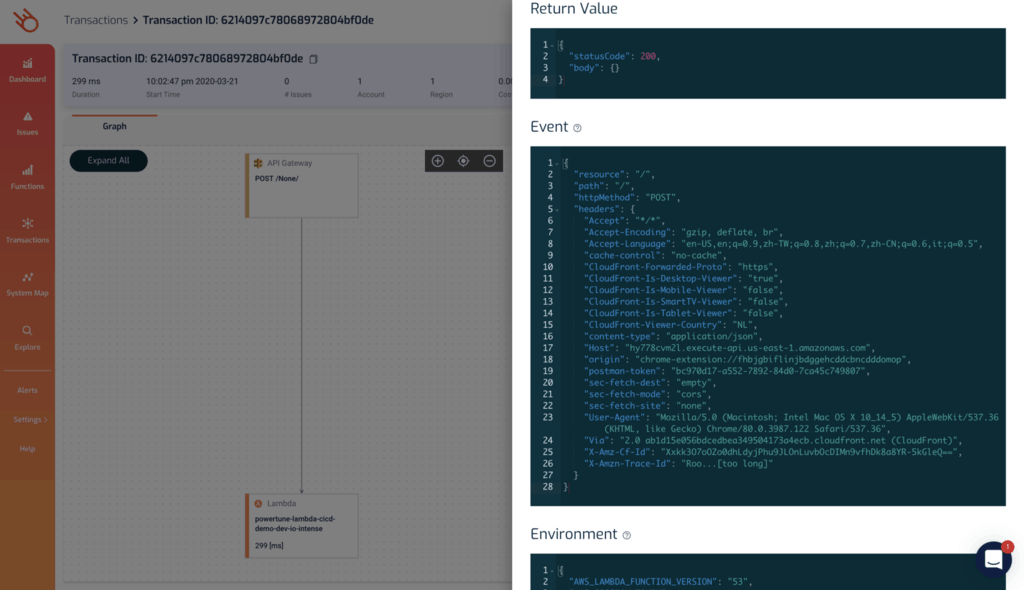
Third-party tools such as Lumigo can make your life easier here. As you can see the invocation event for a function in the Transactions view. This makes it easy to capture sample payloads without having to temporarily add print statements to your functions.
If the function’s memory size doesn’t match the optimal power, then we can update it in-place using the AWS CLI.
if ((optimalPower != memorySize)); then
echo "updating function memory size to $optimalPower..."
aws lambda update-function-configuration \
--region $1 \
--function-name $functionName \
--memory-size $optimalPower > /dev/null
fi
update 24/03/2020: since lumigo-cli v0.40.0 you can now apply the optimal power to the function with the powertune-lambda command, without having to script it yourself.

The CI/CD pipeline
I decided to use CircleCI here because it’s free for public repos and I have used it to good effect in the past. But the approach works with other CI tools too.
Here, my entire pipeline involves setting up the dependencies and then running ./build.sh deploy dev us-east-1 and ./build.sh tune dev us-east-1 balanced . In practice, I’d have used a custom docker image with all the dependencies (AWS CLI, jq, etc.) pre-installed.
version: 2
jobs:
deploy-dev:
docker:
- image: circleci/node:latest
working_directory: ~/repo
steps:
- checkout
- run: curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
- run: unzip awscliv2.zip > /dev/null
- run: sudo ./aws/install
- run: sudo apt-get install -yy less # required by aws cli v2
- run: sudo apt-get install jq
- run: sudo npm i -g lumigo-cli
- run: ./build.sh deploy dev us-east-1
- run: ./build.sh tune dev us-east-1 balanced
workflows:
version: 2
deploy:
jobs:
- deploy-dev:
filters:
branches:
only: master
And when the pipeline finishes, all 3 functions’ memory size would be fine-tuned to give the best performance-to-cost ratio.

Wrap up
In this post, we saw how you can optimize the memory configuration for your functions as part of the CI/CD pipeline. This ensures that your functions are always fine-tuned to deliver the best performance at the lowest cost.
The approach is applicable to different deployment frameworks and CI tools. Broadly speaking, your pipeline would consist of these steps:

The functions’ configurations are updated in-place and the changes are never committed back into the source code. The problems with this approach are:
- Functions need to be tuned in every environment, after every deployment.
- The payloads might be environment-specific, which introduces extra complexity and overhead for managing these.
- It might not be possible to tune functions that write to databases, etc. in the production environment. At the very least, you’ll have to pay special attention to manage this to avoid introducing test data to the production environment.
To address these problems, you can extend the approach I have shown you in this post. For example, instead of updating the functions in-place, you can create a PR when improvements are identified. Assuming there are no environmental factors that can drastically affect performance, then you’d only need to run tuning in the deployment pipeline for dev. This addresses the aforementioned problems.
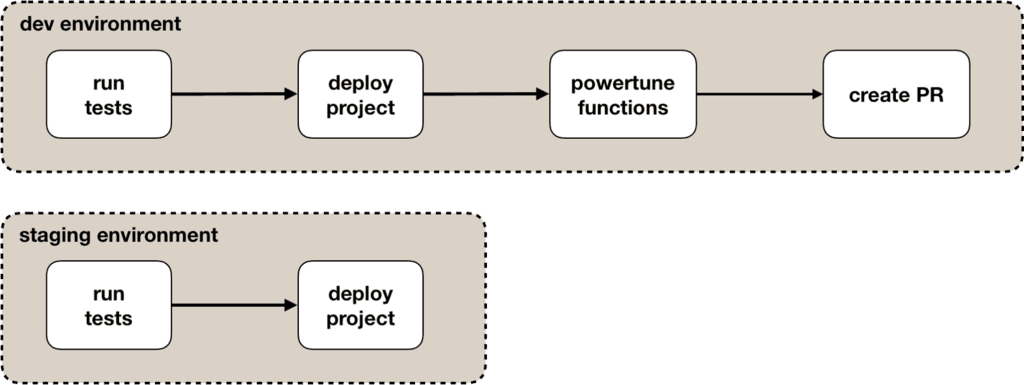
If you can standardise on the deployment and CI tool you use, then you can automate the process even more. For example:
- parse the
serverless.ymlto extract the function names so they don’t have to be hardcoded - auto-generate the payload based on the configured event source for each of the functions
- create an organization-wide CLI that lets you bootstrap new projects with a templated
build.shscript and CI/CD pipeline yml
And finally, here are some relevant resources for you to explore:
- The demo project used in this post
- Alex Casalboni’s aws-lambda-power-tuning app
- the Lumigo CLI used to automate the tuning process
- my course “Learn you some Lambda best practice for great good!” where I discussed power-tuning and other performance and cost optimization techniques for Lambda
Happy tuning!
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
If you register early, you can also get 30% off general admission with our early bird tickets!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.