

Yan Cui
I help clients go faster for less using serverless technologies.

AWS Lambda has a 6MB limit that applies both to request and response payloads. This can be problematic if you have an HTTP API that allows users to upload images and files to S3.
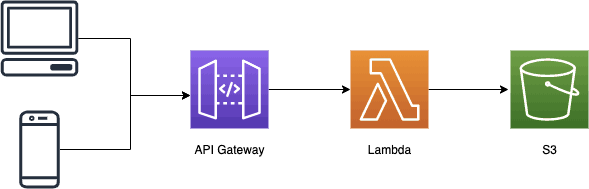
One day, a customer might complain that he couldn’t upload pictures of his cat to your app.
In your Lambda logs, you will see something like this.
Execution failed: 6294149 byte payload is too large for the RequestResponse invocation type (limit 6291456 bytes)

In this post, let’s look at 4 different solutions for working around this 6MB payload limit for Lambda.
Option 1: use API Gateway service proxy
You can remove Lambda from the equation and go straight from API Gateway to S3 using API Gateway service proxies.
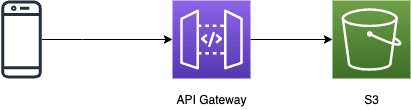
To learn more about API Gateway service proxies and why you should use them, please read my previous post [2] on the topic.
This approach doesn’t require any client changes. If you’re using the Serverless Framework [3] then the serverless-apigateway-service-proxy [4] plugin makes it easy to configure this S3 integration.
custom:
apiGatewayServiceProxies:
- s3:
path: /upload/{fileName}
method: post
action: PutObject
bucket:
Ref: S3Bucket
key:
pathParam: fileName
cors: true
The problem with this approach is that the API Gateway payload limit of 10MB still restricts you.

It’s more than Lambda’s 6MB limit, but not by that much… It’s a problem that you still have to worry about.
Option 2: use presigned S3 URL
You can also rearchitect your application so that uploading images becomes a two-step process:
- The client makes an HTTP GET request to API Gateway, and the Lambda function generates and returns a presigned S3 URL [6].
- The client uploads the image to S3 using the presigned S3 URL.

This approach requires updating both the client and the server, but it’s a simple code change on both sides.
Since the client will upload the files to S3 directly, you will not be bound by payload size limits imposed by API Gateway or Lambda. And with presigned S3 URLs, you can do this securely without opening up access to the S3 bucket itself.
Option 3: Lambda@Edge to forward to S3
Thank you to Timo Schilling for this idea.
First, set up a CloudFront distribution and point it to an invalid domain.
Then, attach a Lambda@Edge function to perform any necessary authentication and authorization and forward valid requests to the S3 bucket using a presigned S3 URL. This is similar to the official example here, which uses an “origin request” function to change the CloudFront origin based on the request.
Compared to option 2, this approach is much more developer-friendly for the caller. As far as the caller is concerned, it’s just a plain POST HTTP endpoint, which is great when you’re working with 3rd party/external developers.
However, using Lambda@Edge brings some operational overhead:
- Updates to Lambda@Edge functions take a few minutes (should be around 5 minutes following recent improvements to CloudFront deployment times) to propagate to all AWS regions.
- Lambda@Edge functions’ logs are sent to CloudWatch Logs in the nearest region. So, if you need to monitor your Lambda@Edge functions, then you need to check the logs in ALL the regions where they could have been sent. And if you’re ingesting Lambda logs to a centralised logging platform (e.g. logz.io) then you’d need to set up the ingestion process in all of these regions too.
Option 4: use presigned POST instead
Thank you to Zac Charles for this idea [7].
This is similar to option 2, but you can also specify a POST Policy [8] to restrict the POST content to a specific content type and/or size. There are also some other differences to option 2. For example, you need to use an HTTP POST instead of PUT, and pass in a number of HTTP headers returned by the createPresignedPost request.
Zac’s post has a lot more detail about caveats you need to be aware of. Please go and read it.
Wrap up
So there you have it. The 6MB Lambda payload limit is one of those things that tends to creep up on you because it is one of the less talked about limits.
Generally speaking, I prefer option 2 as it eliminates the size limit altogether, at the expense of requiring changes to both the frontend and backend.
If your application needs to impose some size limit on the payload in the first place, then it might not be the right solution for you. API Gateway and Lambda’s payload size limit is a built-in defence mechanism for you in that case. You can enable WAF with API Gateway, which can enforce even more granular payload limits without implementing them in your own code (and maintaining that code).
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications, check out my upcoming workshop, Production-Ready Serverless [9]!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Links
[2] The why, when and how of AWS API Gateway service proxies
[4] serverless-apigateway-service-proxy plugin for the Serverless framework
[5] API Gateway quotas and limits
[6] S3 sharing objects with presigned URLs
[7] S3 Uploads — Proxies vs Presigned URLs vs Presigned POSTs
[8] S3 Post Policy for presigned POST
[9] Production-Ready Serverless workshop
Related Posts


Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.