

Yan Cui
I help clients go faster for less using serverless technologies.

How Lambda pricing works
When it comes to cost, Lambda charges you based on the amount of memory you allocate to the function and how long this function runs for by the millisecond. And it also charges you a fixed fee of 20 cents per million invocations.
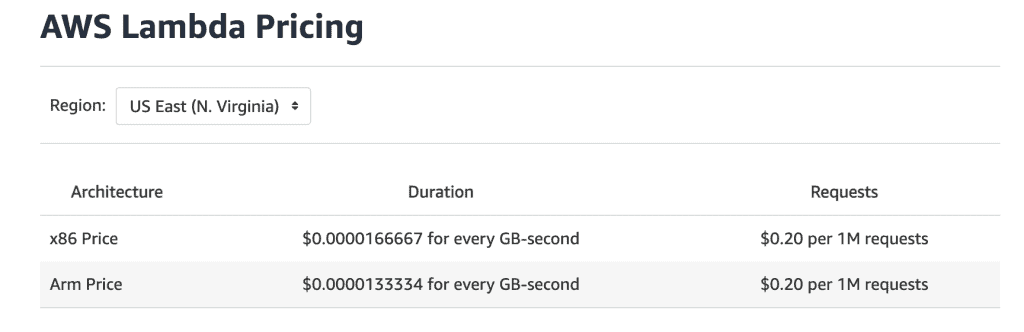
source: https://aws.amazon.com/lambda/pricing
There can be other costs involved, such as the data transfer cost, but also when you enable certain features. Such as when you allocate additional space to the /temp storage, or when you use provisioned concurrency. But for vanilla on-demand functions, your main costs are:
- how long your function runs for; and
- how many invocations you get.
The cost per millisecond of execution time is scaled proportionally to the amount of memory you allocate. As an example, one second of execution for a 512MB function would be 4 times the cost for one second of execution of a 128MB function.
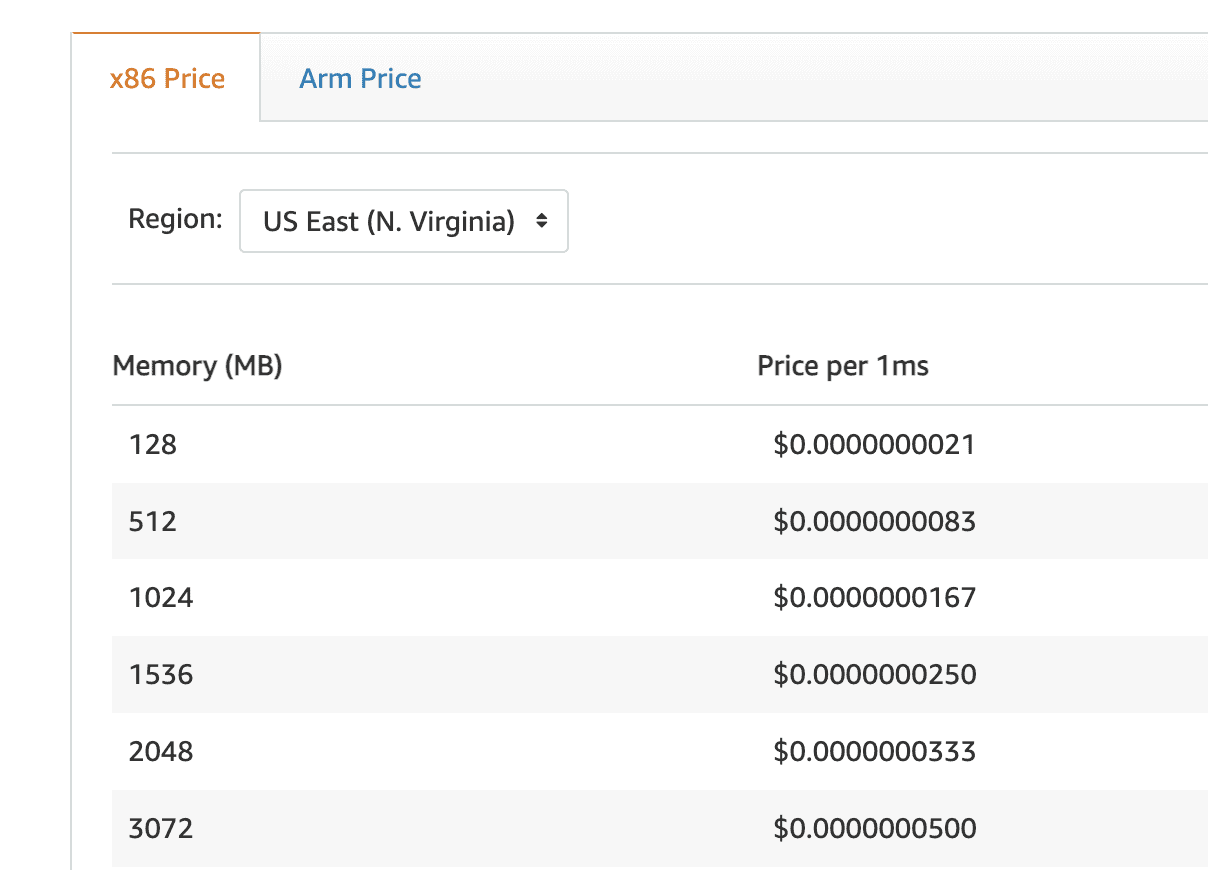
source: https://aws.amazon.com/lambda/pricing/
Avoid premature optimization
The most effective way to save money on your Lambda functions is to make sure that you don’t allocate more memory than your functions actually need.
It’s also worth pointing out that, for the vast majority of your Lambda functions, there are likely no meaningful cost savings to be had.
Lambda cost itself is usually pretty far down the list of the most expensive items in your monthly AWS bill. Often behind the likes of API Gateway and CloudWatch by a large distance.
There are exceptions to this of course. But as the famous saying goes…

The trick is in identifying that critical 3% of cases where we should optimise our Lambda function.
You should always optimise the memory setting for functions that use provisioned concurrency.
Because provisioned concurrency has an uptime cost per month per unit of concurrency. And that cost scales proportionally to the amount of memory allocated to the function. For example, one provision concurrency for a 128MB function has an uptime cost of just $1.40 per month, plus variable costs based on the no. of invocations and execution time. But one provision concurrency for a 10GB function would have an uptime cost of $111.61 per month, plus those variable costs as well.
With scaling effects like this, it’s easy to make mistakes that can increase your Lambda cost by orders of magnitude.
Another group of functions that fall into that critical 3% are functions that are invoked often (e.g. millions of times a month) and have a long execution time.
We can likely make meaningful savings on these functions by allocating less memory. This usually works great for functions that spend a lot of their execution time just sitting idle, and waiting for a response from API calls. So all that CPU cycles are just getting wasted anyway.
Funny enough, in some cases, it might be cheaper to allocate more memory, not less! Because the amount of CPU resources and network bandwidth is allocated proportionally to the amount of allocated memory. More memory equals more CPU cycles, which equals getting whatever CPU-intensive task done faster. And because we’re charged by the millisecond, so faster execution at a higher cost per millisecond can still work out to be cheaper than a longer execution time at a lower cost per millisecond.
Luckily for us, we don’t have to rely on guesswork. We can work this out using a data-driven approach.
How to right-size Lambda functions
Alex Casalboni, who now works at AWS, created a tool called aws-lambda-power-tuning. It’s a Step Functions state machine that can invoke a target function against an array of different memory settings and capture their performance and cost. It helps you find the best memory setting for your function based on performance, cost or a combination of the two.
First, you have to install the state machine, I find it easiest to install this through the Serverless Application Repository (SAR) here.
Once it’s deployed, you can start an execution using a JSON payload like this:
{
“lambdaARN”: “arn:aws:lambda:us-east-1:374852340823:function:workshop-yancui-dev-get-restaurants”,
“powerValues”: [128, 256, 512, 1024, 2048, 3008],
“num”: 100,
“payload”: “{}”,
“parallelInvocation”: true,
“strategy”: “balanced”
}
This tells the state machine to test my function against an array of different memory settings, with 100 invocations each.
I have to provide a payload for the invocations. Luckily, this function doesn’t require anything from the payload, so I can send an empty JSON object.
It supports three different strategies: performance, cost and balanced. With the “balanced” strategy, I’m essentially asking for the memory setting that gives me the most bang for my buck.
Once the state machine execution finishes, you can check its output tab and find the best memory setting in the result.
{
“power”: 256,
“cost”: 4.914000000000001e-7,
“duration”: 116.62700000000002,
“stateMachine”: {
“executionCost”: 0.0003,
“lambdaCost”: 0.0009826981500000004,
“visualization”: “https://lambda-power-tuning.show/#…”
}
}
With the visualization URL, I can see how the performance and cost of this function changed with each memory setting.
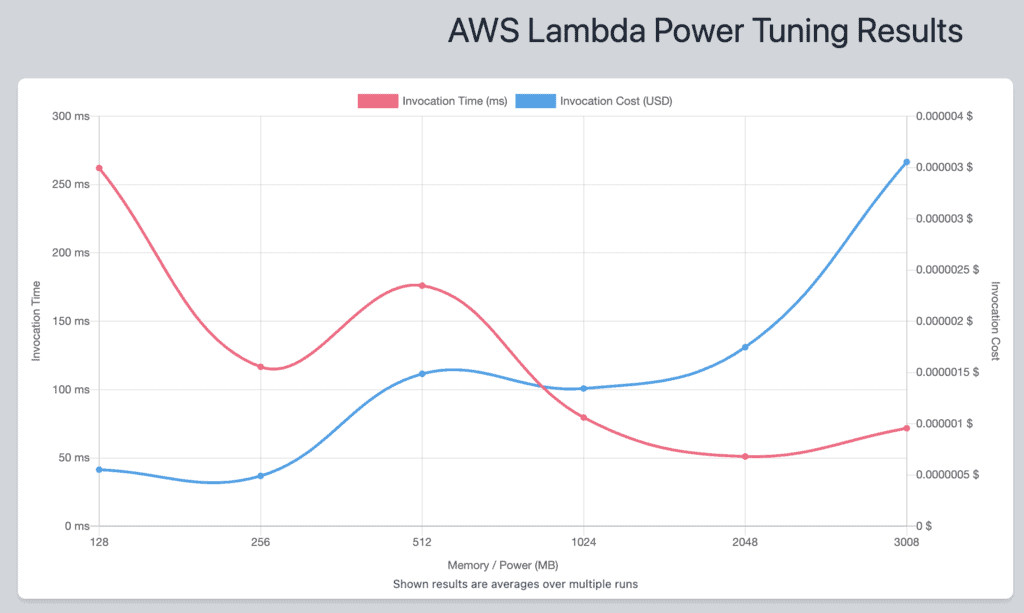
Lambda power tuning is a really powerful tool to have in your locker and when it’s used in the right circumstance it can give you significant cost savings.
But once again, you shouldn’t do this by default. Because there are no meaningful cost savings to be had in most Lambda functions and this cost saving is not free. You still have to work for it, including:
- capturing and maintaining a suitable payload to invoke a function with;
- plan and execute the state machines for every function;
- there is a cost associated with running the state machine itself;
- you have to repeat this process every time a function is changed, where you have to update the invocation payload and rerun the tests;
- and the most significant cost is the time you have to put into doing all the above.
If you use Lumigo, then a good way to identify good targets for power tuning is to go to the Functions tab and then sort your functions by cost in descending order.
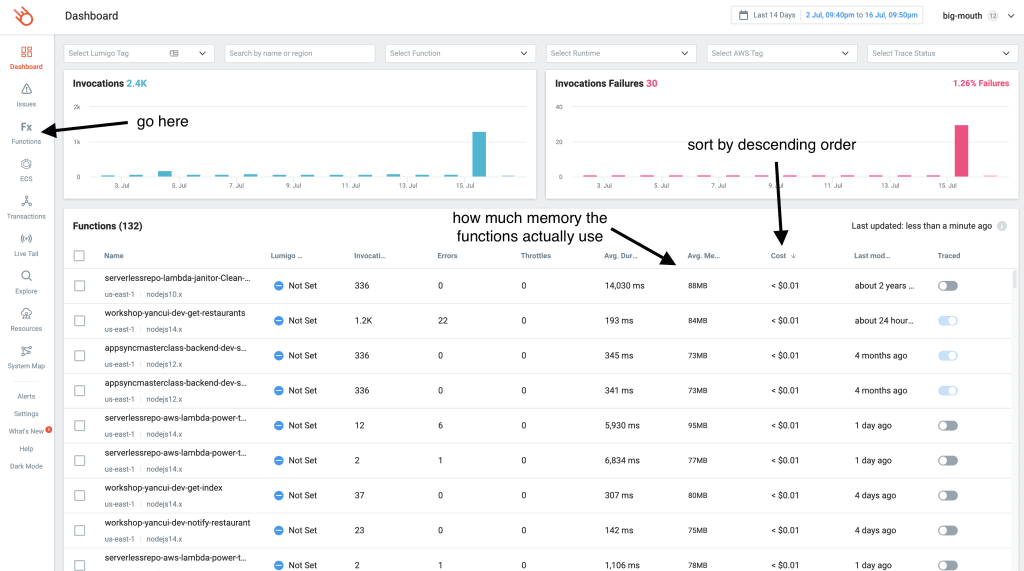
Here, you will find functions that have a meaningful cost and are allocated with more memory than it’s actually using, which you can see in the Avg. Memory column. These are the functions you should consider tuning.
As I mentioned earlier, you should also optimise functions that are using provisioned concurrency. Because the uptime cost for these functions can be significant. So using the wrong memory setting with these functions can have a huge cost implication.
Switching to ARM architecture
Another way to cut down on Lambda execution costs is to switch to the ARM-based Graviton2 processor. It’s about 25% cheaper per millisecond of execution time compared to functions that are running on the x86 architecture.
Before you do, you need to test your workload on both the x86 and ARM architecture. The launch blog post from AWS mentioned a 19% better performance in the workloads they tested. But reports from the community have wildly different results. In some cases, I’ve seen ARM-based functions run for over 60% longer than x86-based functions. Depending on your actual workload, you might have a very different result.
Having said that, if your function is IO-heavy and spends most of its time waiting for responses from other AWS services such as DynamoDB, then they’re usually good candidates to switch to ARM. Because raw CPU performance is not going to have a big impact on the overall performance of the function in these cases.
Leveraging Provisioned Concurrency
Finally, another way to save money on Lambda is to use provisioned concurrency.
This might seem counter-intuitive at first, but let me explain.
With provisioned concurrency, the cost per millisecond of execution time is about 70% cheaper.
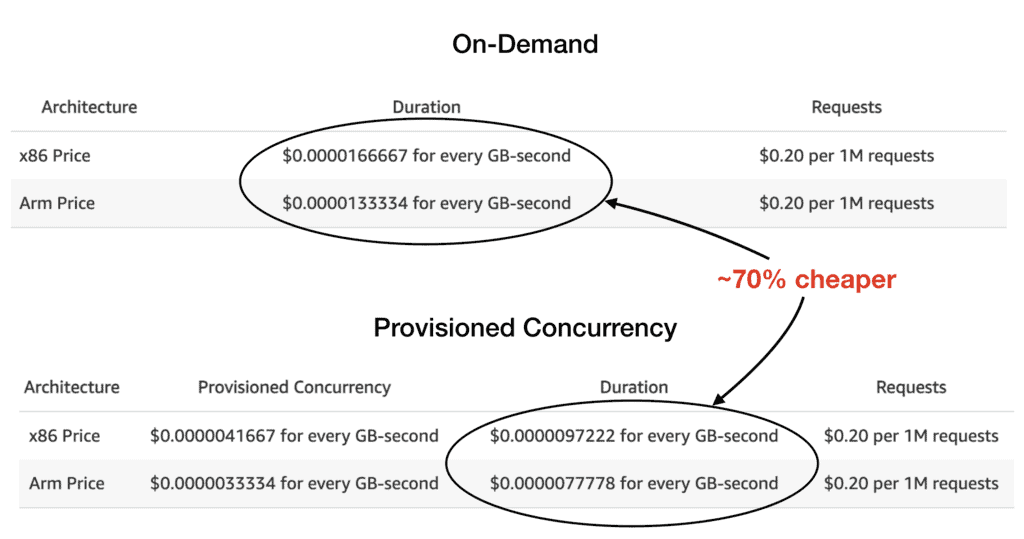
If you’re able to keep these provisioned concurrencies busy, say 60% of the time, then you’ll break even against the on-demand pricing. And anything beyond that 60% threshold would be cost savings.
This technique would only work for high throughput functions and there’s a potentially steep penalty if you get it wrong because of the aforementioned uptime cost. There are also operational overheads for using provision concurrency. So as far as optimising Lambda cost is concerned, I don’t recommend this technique unless you really know what you’re doing! Instead, use provisioned concurrency as a way to eliminate Lambda cold starts, as it’s intended for.
psst.. you can also watch this on YouTube instead.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.