

Yan Cui
I help clients go faster for less using serverless technologies.

Last week, PrimeVideo posted a headline-grabbing article that broke tech Twitter. The article is a case study of how a PrimeVideo team cut the running cost of its service by 90% by moving away from a microservice architecture running on serverless technologies (Lambda and Step Functions).

The team didn’t expect the service to run at a high scale and built the initial version on Lambda and Step Functions to help them get to market quickly. But then the service became popular and the team started to experience scaling and cost issues with this initial implementation. So they adapted and moved to a monolithic architecture running on ECS. Along the way, they identified and removed unnecessary overheads and optimized the system based on learnings from the initial implementation.
What should have been an interesting case study for “evolution architecture” turned into a social media shitstorm.
You have the DHH school of “serverless/microservices is dead”. (hint: it’s not. It’s one team, one service within a huge organization.)
You have the outcry of “They architected it wrong in the first place!” (well, hindsight is always 20/20.)
You have conspiracy theories that AWS leadership forced Lambda on its teams, which was debunked by people who were closer to the leadership.

Occasionally, someone reminds us that “one swallow does not make a summer”.

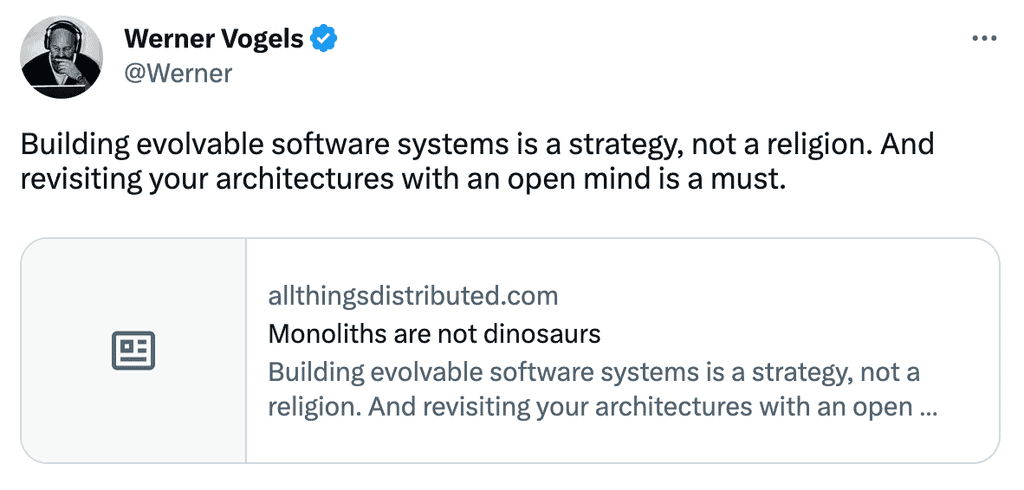
And even Werner chimed in with a reminder about building evolutionary architectures!
Now that some of the initial excitement and craziness has died down. Let’s take a more balanced look at what we could learn from this case study, and answer a few common questions about Lambda and serverless.
There are no silver bullets
As my favourite saying goes: “There are no solutions, only trade-offs”.
There is no practice that is inherently best for all situations, it always depends on your context. In other words, there are no silver bullets.
And your context can change over time.
As a startup founder, you have a limited budget and need to find market fit before you run out of runway. So you would naturally prioritize time-to-market and value solutions that have low or no capital expenditure.
Serverless components that offer pay-per-use pricing are a great choice here. You get a good baseline for:
- Scalability (more on this later).
- Redundancy. Services such as Lambda, API Gateway and DynamoDB are multi-AZ out-of-the-box so you’re protected from AZ-wide failures.
- Security.
And you only pay for them when people use your system. This makes them very cost-efficient when you have lots of great ideas to test out but not a whole lot of users (yet!).
Fast forward a few months or years, and you have a profitable product with millions of users. The product has stabilized and you are no longer pivoting the product every 90 days! You have learnt a lot about your system and identified its inefficiencies.
Now you’re operating under a very different context. You are now in a position to optimize efficiency and cost for a high throughput workload.
Bringing this back to the PrimeVideo article…
The article talks about a similar journey that a team within PrimeVideo went through. They built a service and found an internal market fit and have to adapt their architectural approach accordingly.
They decided to move to a monolithic architecture running on ECS because it’s a better fit for their workload and their context (ie. high throughput).
From the outside, this seems like a sensible choice to me. Good for them!
But this is one service within one large organization. We cannot extrapolate any general conclusion about what’s best for the rest of PrimeVideo, Amazon, or the wider tech community.
There is no one approach that will work for everyone.
And remember, you are not PrimeVideo and you are not Amazon. What works best at their scale is not guaranteed to work best for you.
The serverless-first mindset
Like most enterprises, I imagine PrimeVideo has a wide range of different use cases and contexts. Lambda and Step Functions might be better in some cases and containers/ECS would be better in others.
Many of my enterprise clients also operate with a mixed environment where different teams and services would use different compute services. This is normal and to be expected in an enterprise environment.
And in many cases, like the one described in the PrimeVideo article, they would start with serverless to go to market quickly. Then they would pivot if and when it makes sense to move a workload to containers. For example, when a service has to run at a high scale and it becomes more cost efficient to run the workload on containers instead.
And that’s how you should do it!
It’s what serverless advocates like myself have described as the “serverless-first” approach. And I think it’s the right approach for most greenfield projects.
But what about when you’re replacing an existing system?
When I was at DAZN, we had over 2 million concurrent viewers at peak. The traffic pattern was very spiky along the critical path of a user logging in and start watching a live sporting event. This is because users tend to log in to our platform just before a sporting event kicks off. The spikes are huge as millions of people would log in at the same time, but their timings are also very predictable.
This traffic pattern was well known to us as we embarked on a multi-year journey to bring the platform in-house and rebuild it from the ground up.
We were able to make some key decisions early on. For example, we decided that Lambda is not suitable for services along the critical path. This is because Lambda has a burst concurrency limit, which stands at 3000 concurrent executions for large regions such as us-east-1. (more on this later in the post)
But we still have a lot of Lambda and Step Functions because not every part of our system has the same traffic pattern. The APIs on the critical path might experience a spike from 100 to 50,000 req/s in a 30s span. Elsewhere, you might only ever see 50 req/s at peak on the payment system.
Even some services in that critical path were able to use Lambda and API Gateway for their services because their API responses are highly cacheable. So the large spikes are absorbed by CloudFront. If you want to learn more about caching for serverless architectures, then check out this related post.
Code reuse from Lambda to containers
Amongst all the arguments about microservices vs monoliths, many have missed this valuable nugget from the PrimeVideo article.

That’s right. Turns out Lambda isn’t quite the lock-in some people have been telling us about, and it’s quite possible to reuse existing code when you move from Lambda to containers.
If you wanna hear my take on Lambda and the “vendor lock-in” argument, check out this segment from my conversation with The Geek Narrator recently.
Is Lambda scalable?
In theory, the Lambda service is infinitely scalable. You can run as many concurrent Lambda executions as you can afford (assuming you can convince the Lambda team to approve your raise request).
But it’s worth considering the burst concurrency limit, which determines how much you can scale at an instant. In us-east-1, you can scale from 0 to 3000 concurrent executions instantly. But after that, your concurrency can go up by only 500 per minute.
This means, it will take you 14 mins (7000 / 500) to reach the peak concurrency of 10000 concurrent executions.
When considering if Lambda is scalable enough for your use case, you need to consider:
- What is the expected peak throughput?
- How spiky is the traffic pattern?
- Are the traffic spikes predictable?
As Vlad Ionescu pointed out in his excellent post, Lambda scales significantly faster than other container services in AWS.
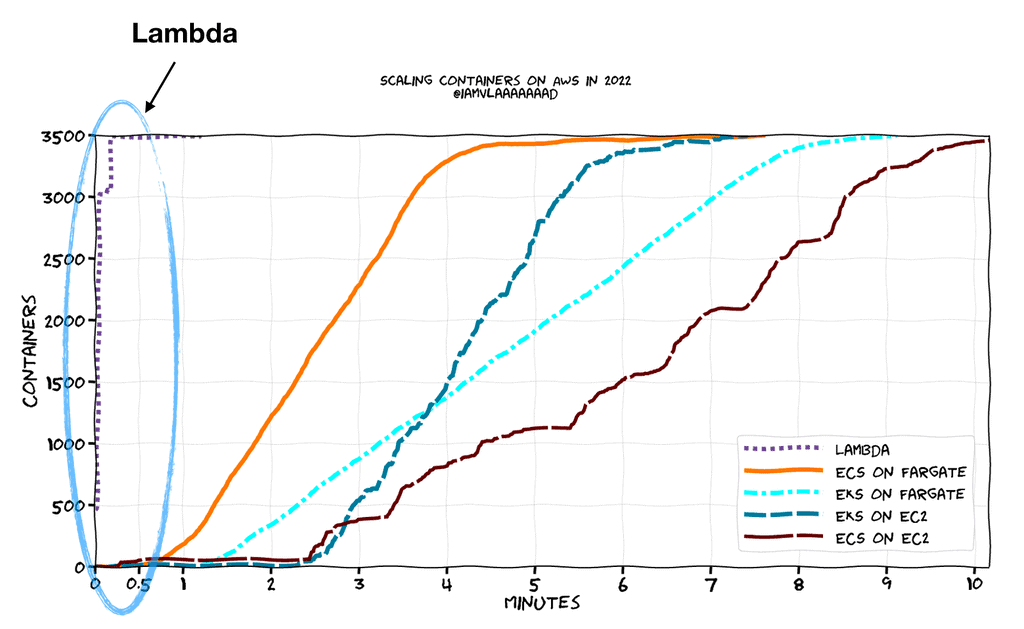
This makes Lambda a great fit for use cases where you have to deal with unpredictable traffic spikes, so long as you don’t run foul of the burst concurrency limit.
With containers, you have more control around scaling and are able to handle concurrent API requests in the same container instance.
In the DAZN example earlier, the spikes on the critical path are predictable and too much for Lambda’s burst concurrency limit. Which makes containers a better fit for services along the critical path.
The downside is that we have to over-provision every service along the critical path so they are able to handle smaller spikes in traffic. This leads to lots of wasted EC2 spending on unused CPU cycles. It gets worse when you factor in multi-AZ and you typically need to over-provision to protect against an AZ-wide outage. For example, if you’re operating in three AZs, then you need to have enough capacity in each AZ to handle 50% of the peak traffic. This ensures that if one AZ fails, then you still have enough capacity in the remaining two AZs to handle 100% of the peak traffic.
This is expensive and my heart bleeds a little every time I see an AWS account with hundreds of EC2 instances running at <5% CPU utilization.
For DAZN, this was part of the cost of doing business.
For my consulting clients who don’t have to worry about millions of users logging in at the same time, Lambda is often the more scalable and cost-efficient option.
Bustle, for instance, serves tens of millions of monthly users (see the AWS case study) with their serverless platform. Research institutions like CSIRO and Emerald Cloud Lab are using Lambda like a supercomputer and spins up thousands of CPU cores to perform high-performance computing tasks (listen to my conversations with them here and here).
When is Lambda not a good fit?
At high scale (say 1000+ req/s), services such as API Gateway and Lambda can be much more expensive to operate than running a bunch of containers on ECS. It makes sense to move these workloads to containers and save on operational costs, as the PrimeVideo article has described.
In my conversation with The Geek Narrator, I also outlined two other examples where Lambda is not a good fit:
- When you have a long-running task that can take more than 15 mins to complete. Assuming you can’t break the task into smaller tasks that can be parallelized.
- When you have really strict latency requirements, such as a real-time multiplayer game. Even when you eliminate cold starts with Provisioned Concurrency, it’s still difficult to achieve the ultra-low latency required by these applications. A long-running server that communicates with clients over persistent connections is still the best way to go.
Wrap up
I hope you have found this article insightful and helped you get a better understanding of where Lambda can be a right fit in your architecture.
If you want to learn more about building serverless architecture, then check out my upcoming workshop where I would be covering topics such as testing, security, observability and much more.
Hope to see you there.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.