
Yan Cui
I help clients go faster for less using serverless technologies.

The problem with DLQs
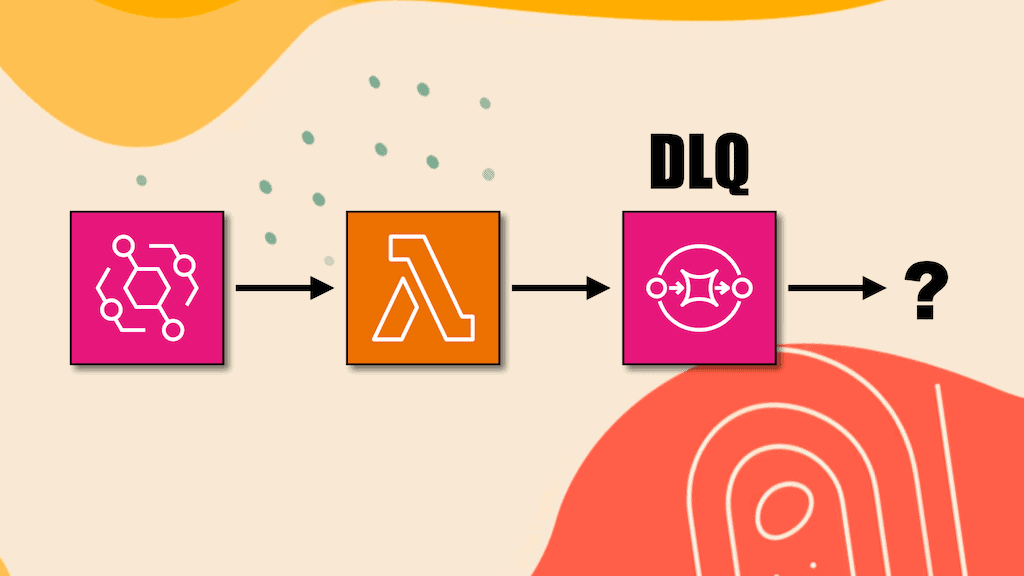
Imagine this. You have followed AWS best practices and set up a dead-letter queue (DLQ) or an OnFailure destination for every async Lambda function.
(sidebar: you should prefer Lambda Destination over DLQs, here’s why [1])
A message arrives in your DLQ. You are alerted right away because you have alarms on all of your DLQs.
You investigate the problem and determine that it was temporary and the message should be re-processed.
But now what?
Do you extract the payload and invoke the original function manually? What if there are hundreds of similar messages? This manual approach doesn’t scale well.
Do you use SQS’s StartMessageMoveTask [2] API to redrive messages back to the source queue? But this API doesn’t support source queues that are not DLQs of other SQS queues. So you can’t use it with a Lambda function’s DLQ or OnFailure destination.
A good approach is to subscribe another function to the DLQ but leave the event source mapping disabled.
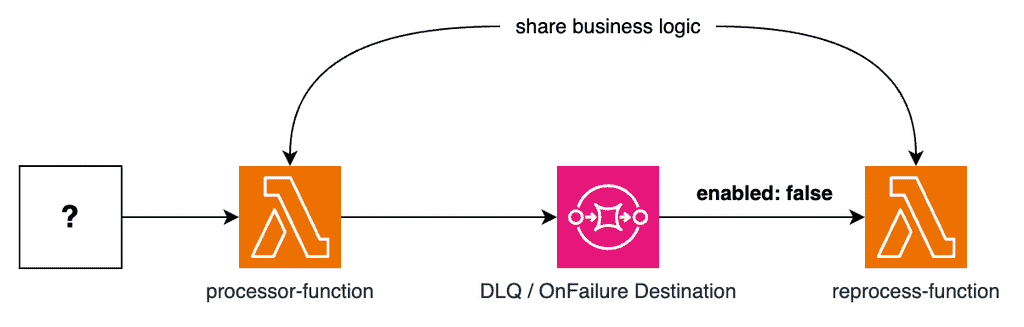
This way, messages would not be automatically reprocessed – that wouldn’t make sense. Instead, it can be enabled on demand if and when you decide to reprocess them.
The reprocess-function can share the same business logic as the initial processor-function.
If the queue is an OnFailure destination, then the SQS messages would contain additional wrapping (see below). The reprocess-function would unwrap the message before reprocessing the original payload.

I like this approach because it’s a simple setup and it’s a repeatable pattern.
For CDK users, you can even turn it into a L3 construct so it can be scaled to large event-driven architectures with many async functions.
What do you think of this approach? Do you have other approaches that you prefer over this?
Option 2: EventBridge Pipes to resend the message
Another similar, and equally good approach is to use EventBridge pipes instead of a second function, as below. Big thanks to Michael Gasch for bringing this up on Twitter.
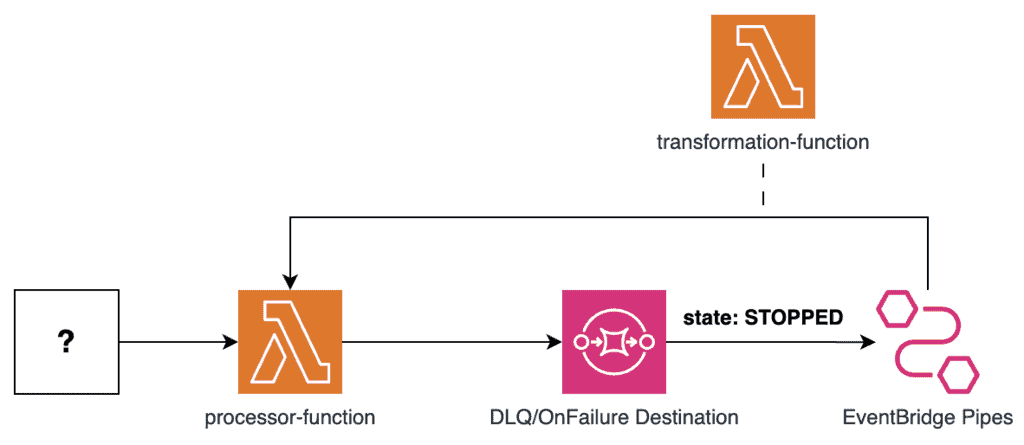
Again, we will leave the pipe in a STOPPED state initially. And we will start the pipe on demand when we need to reprocess the failed messages. The messages will be piped back to the original processor function.
In the case of an OnFailure Destination, we can use a transformation function to extract the original payload from the OnFailure event.
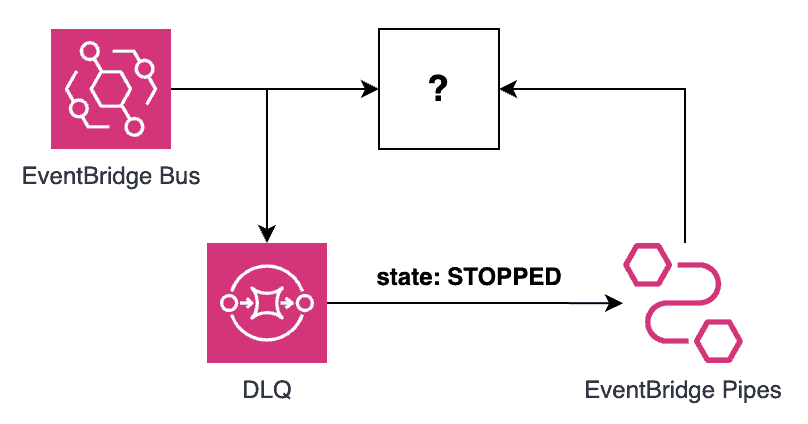
What’s nice about this approach is that it also works for event-driven architectures that leverage direct AWS integrations. For example, EventBridge can forward events to other AWS services without needing a Lambda function. You should still configure a DLQ for these direct integrations so failure to deliver the events to the target does not result in data loss.
Using this approach, you can use EventBridge Pipes to send the failed events back to the original target without needing to introduce another Lambda function into the mix. Resulting in a simpler architecture with fewer moving parts and less code for you to maintain.
EventBridge Pipes currently supports the following targets:
- API Destination
- API Gateway
- Batch job queue
- CloudWatch log group
- ECS task
- Event bus in the same account and Region
- Firehose delivery stream
- Inspector assessment template
- Kinesis stream
- Lambda function
- Redshift cluster data API queries
- SageMaker Pipeline
- Amazon SNS topic (SNS FIFO topics not supported)
- Amazon SQS queue
- Step Functions state machine
For this approach to work, the (?) box above must be one of these supported targets. Otherwise, you will need to add a Lambda function to bridge the gap.
Links
[1] Why you should stop using DLQs, use Destinations instead
[2] SQS’s StartMessageMoveTask API
Related Posts






Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.