
Yan Cui
I help clients go faster for less using serverless technologies.

I had a really good question from one of my students at the Production-Ready Serverless workshop the other day:
“I’m reacting to S3 events received via an SNS topic and debating the merits of having the Lambda triggered directly by the SNS or having an SQS queue. I can see the advantage of the queue for enhanced visibility into the processing and “buffering” events for the Lambda but is there a reason not to use a queue in this situation?”
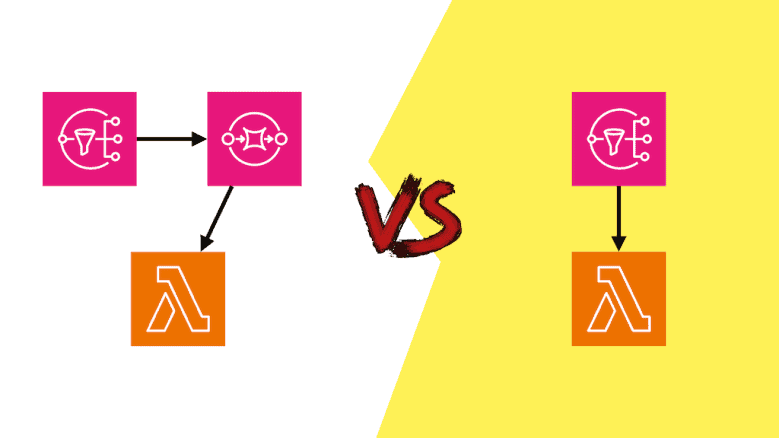
The case for SNS -> Lambda
It used to be that you’d always use SNS with SQS in case there was a problem with delivery to the target, so you don’t lose data. But now that SNS supports Dead-Letter Queues (DLQs) natively, you don’t need to do it for resilience anymore. There are still reasons to use SQS here, namely for cost efficiency and performance.
The main consideration here is that SQS is a batched event source for Lambda so you can process the same number of messages with fewer invocations. If the processing logic is IO-heavy (e.g. waiting for API responses) then you can even process messages in parallel and make more efficient use of the CPU cycles. This often leads to better throughput and lower Lambda costs when processing a large number of messages.
However, this cost-saving needs to be weighed against the additional cost for SQS:
- for publishing messages to it (via SNS), and
- for the polling requests (that the Lambda service performs on your behalf via the event source mapping).
This trade-off depends on your workload and how long it takes to process each message.
The main drawback of using SQS is complexity. Because now you’d need to:
1) Have a try-catch around each message so you can capture the failed messages and avoid failing the entire batch.
2) Implement partial batch response when there are partial failures (see official documentation here) by configuring the event source mapping and using the correct response format.
3) Configure a DLQ and set up alerts so you know when there are failed messages that require manual intervention. For example, to investigate why the messages failed and if possible, replay them by using the new StartMessageMoveTask API to send the messages back to the main queue.
It’s worth noting that point 3 is still necessary even if you don’t use SQS. But with SNS and Lambda, you can use Lambda Destination instead, which is a better solution than DLQs. Because the failure destination captures the error as well as the failed event, whereas the SQS DLQ would only capture the failed event. It then falls on you to figure out what caused the failure and if the failed message can be retried. You need to find the relevant log messages to figure out what the original error was. To do that, you need to have good observability in place so you can find the error logs related to a failed SQS message. This can be time-consuming if there is a large number of failed messages in the DLQ.
In general, I like to start with the simplest solution, and if it ticks all my boxes then I stop there. There should be a good reason to add a moving part to your architecture. In this particular case, if you’re processing lots of events and the Lambda cost starts to add up, then it’s a good reason to add SQS into the mix so you can process messages in batches.
Similarly, we can argue that you don’t even need SNS in the original question because S3 is capable of invoking Lambda functions. But if you need to fan out the S3 notifications to multiple targets then that’s a good reason to add SNS (or EventBridge) into the mix.
Consider Lambda’s internal queue
Oh, another thing that’s worth pointing out here is that for asynchronous invocation, the Lambda service already employs a fleet of internal SQS queues. There is a fleet of pollers that receive messages from these internal queues and invokes the target functions.
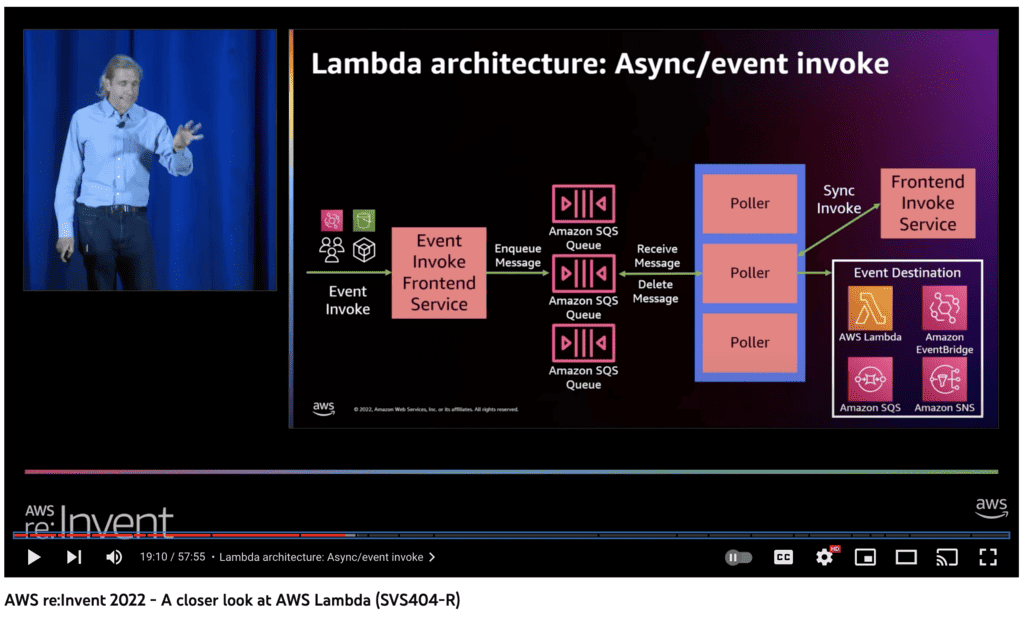
(source: https://www.youtube.com/watch?v=0_jfH6qijVY)
Counter Arguments
A common argument for using SQS is that you get better visibility into the state of the queue – e.g. how many messages are in the backlog.
While there is no direct metric that tells you the size of the internal queue for your function, you can estimate it with the available metrics. For example, you can use the delta between SNS’s NumberOfMessagesPublished metric and Lambda’s Invocations metric to estimate the no. of messages in the backlog. Alternatively, you can also use Lambda’s AsyncEventsReceived metric instead of the SNS metric.
You can also use Lambda’s AsyncEventAge metric to get a sense of how far behind you are. If a function is throttled due to its reserved concurrency setting and is not able to keep up with the flow of incoming messages, then the AsyncEventAge metric would continue to climb. Similarly, if a function fails repeatedly and the async messages have to be retried, then this metric would also spike. You can create an alert against this metric to notify you that your system is falling behind and you need to revisit its reserved concurrency setting.
Another common argument is that SQS gives you better concurrency control with the MaximumConcurrency setting on the event source mapping.
This is also a flawed argument, but there is a small caveat to it… Let me explain.
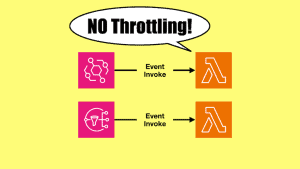
Lambda has built-in concurrency control with its reserved concurrency setting, which acts as the “maximum concurrency” for the function.
However, for async invocations (ie. SNS to Lambda), the pollers for the internal queues would attempt to invoke the function regardless. These attempts would be throttled and they will be reflected in the function’s Throttles metric. Luckily, even as these attempts to invoke the function are throttled, they do not count as “failed invocations” and the messages are not directed to the DLQ or Lambda Destination until they have been processed by the function and failed three times.
So what does this mean for you?
It means you have an effective concurrency control mechanism when using SNS with Lambda directly, using Lambda’s reserved concurrency setting. However, this can result in throttling happening in the background and you kinda have to turn a blind eye to it and ignore these throttling.
With SQS and Lambda, you can’t rely on Lambda’s reserved concurrency setting because it would lead to the SQS over-polling problem (see this post by Zac Charles). Instead, you have to use the MaximumConcurrency setting on the SQS event source mapping.
And it means the argument that SQS offers better concurrency control is incorrect, so long as you ignore the throttlings on the Lambda function.
Update 13/07/2023: a few people mentioned that reserved concurrency is not a good option for managing concurrency broadly. I agree. Because Reserved Concurrency takes away from the available regional concurrency and you don’t want to be in the business of micromanaging the concurrency allocation for individual functions. When used broadly across many functions it can leave too few available concurrency units for your functions that need to scale on-demand. I talked about concurrency management in much more detail in another post, you should give it a read if it’s a topic that interests you. Here’s what I had to say about the limitations of reserved concurrency.

Related Posts
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.