
Yan Cui
I help clients go faster for less using serverless technologies.

Many students and clients have asked me how to implement Map-Reduce workloads serverlessly. In most cases, they are actually asking about Fan-Out/Fan-In!
At a glance, the two patterns look very similar and they are often used interchangeably in conversations. So in this post, let’s compare them and see how they differ.
Why? Because names matter ;-)
Fan-out/Fan-in
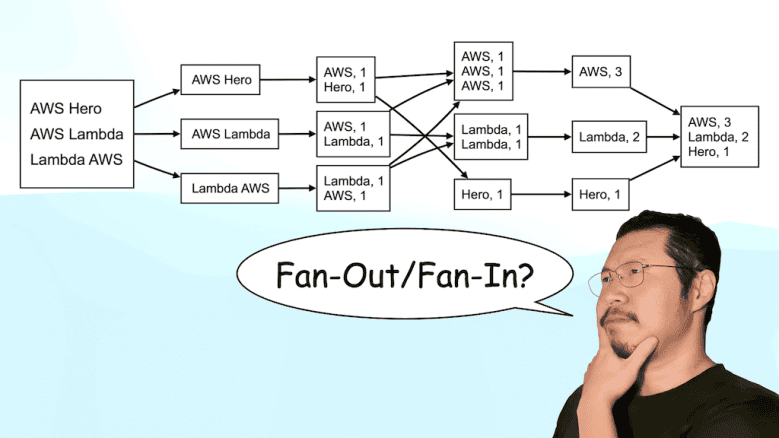
Fan-Out and Fan-In are two patterns that are often used together to divide and conquer a large task by:
- Divide the task into smaller subtasks (Fan-Out);
- Process each subtask in parallel;
- Collect the results of the subtasks into a single result (Fan-in).
You can also use the Fan-Out pattern without the Fan-In step. For example, if you don’t need to capture and return the result of processing these subtasks.
Map-Reduce
While Fan-Out/Fan-In is a general pattern for parallel processing, Map-Reduce has a specific structure that involves “map” and “reduce” steps. Typically, a Map-Reduce framework (such as Hadoop) has the following steps:
- Map: The input data is divided into chunks, and a map function processes each chunk to produce an output;
- Shuffle: The intermediate key-value pairs are shuffled and sorted to group all values associated with the same key;
- Reduce: A reduce function processes each group of intermediate values to produce the final output.
Map-Reduce is typically used to process large amounts of data across a fleet of worker nodes. Data locality is an important performance consideration (to avoid making costly network calls).
Fan-Out/Fan-In vs. Map-Reduce
You can think of Map-Reduce as a specific flavour of Fan-Out/Fan-In. It has a particular structure that involves “map” and “reduce” steps.
They differ in some subtle and important ways.
Use cases
Fan-Out/Fan-In is commonly used in scenarios where independent tasks can be processed in parallel. There’s no need to aggregate intermediate results and group them. For example, web scraping and making concurrent API calls to 3rd party services.
Map-Reduce is typically used for large-scale data processing such as indexing, log analysis, and data transformations. It’s well suited for situations when you need to group and aggregate results by an intermdiate key. For example, if you need to query TBs of user click-stream data and calculate the percentage of website visitors who have clicked a link.
Data locality
With Fan-Out/Fan-In, data locality is typically not a major concern. Because each task is processed independently and the results are only aggregated at the end.
With Map-Reduce, data locality is crucial for minimizing data transfers across the network. That’s why it has a “shuffle” step to group related intermediate results so they can be processed together.
Serverless implementation
There are many ways to implement Fan-Out/Fan-In using serverless services such as Lambda and Step Functions.
In fact, I wrote about several ways to do exactly this back in 2018. A lot has changed since then, so in the next post, I will share my thoughts on the best ways to implement Fan-Out/Fan-In serverlessly in 2024.
In the context of serverless, if you’re using Lambda, you’re probably not using Hadoop or Spark (there’s no clear integration path). And when you use services such as Lambda or Step Functions, you also don’t have access to the underlying worker nodes.
However, it’s possible to perform Map-Reduce jobs with other serverless services on AWS. For example, AWS Glue offers a serverless ETL service that lets you run Spark jobs. Amazon EMR also gives you a managed Hadoop environment.
Summary
Both Fan-Out/Fan-In and Map-Reduce patterns execute tasks in parallel, but they serve different purposes and are suited to different types of workloads.
Fan-Out/Fan-In is a more general pattern applicable to a wide range of parallel processing tasks, whereas Map-Reduce is a specific pattern that’s designed for big data processing.
I hope you’ve found this post useful and answered a questions that you have always wondered about! ;-)
Related Posts
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.