
Yan Cui
I help clients go faster for less using serverless technologies.

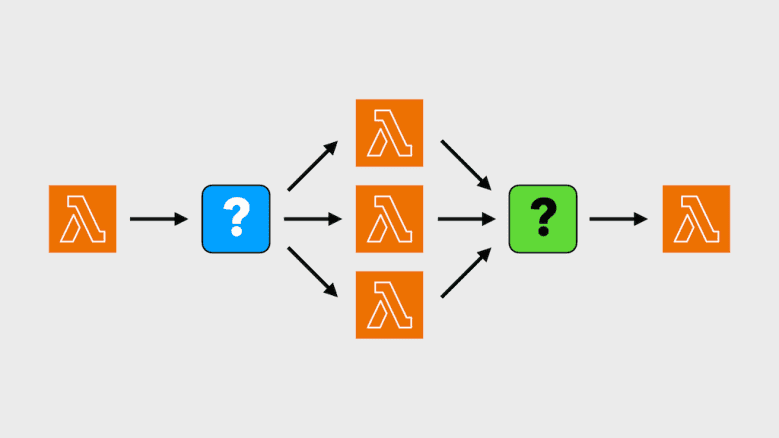
Back in 2018, I shared [1] several ways to implement fan-out/fan-in with Lambda. A lot has changed since, so let’s explore the solution space in 2024.
Remember, what’s “best” depends on your context. I will do my best to outline the trade-offs you should consider.
Also, I will only consider AWS services in this post. But there is a wealth of OpenSource/3rd-party services that you can use too, such as Restate.
If you’re not sure whether you need fan-out/fan-in or map-reduce, then you should my previous post first [2]. I explained the difference between the two and when to use which.
Ok, let’s go!
Step Functions
Fan-out has always been easy on AWS. You can use SQS to distribute tasks across many workers for parallel processing.
But fan-in makes you work! You need to keep track of the individual results so you can act on them when all the results are in.
Luckily for us, Step Function has productized the fan-out/fan-in pattern with its Map state.
You provide an input array and specify how to process each item in the array. The Map state will process the items with as much parallelism as possible. It handles collating the results into the correct order and returns them as an array.
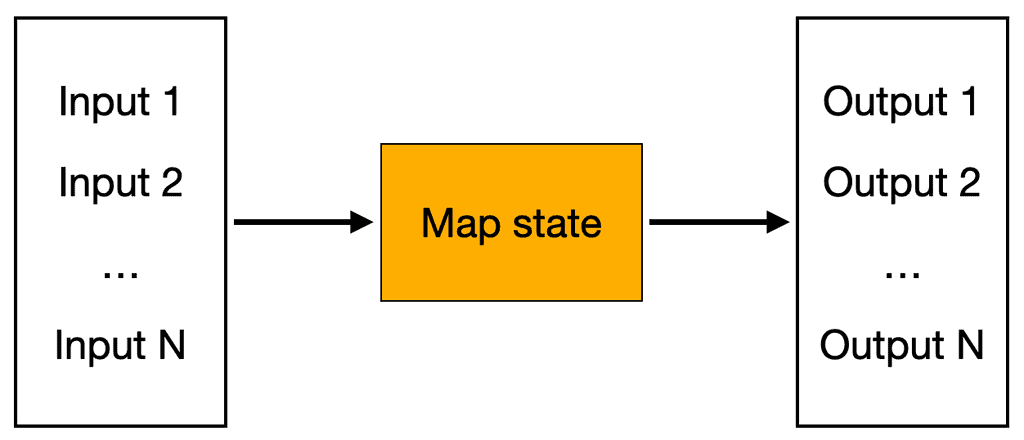
You can take this output array as input to another Task state to act on the results.
Importantly, the Map state has two modes:
Inline modetakes the input array from the state input and allows up to 40 concurrent iterations. This is good enough for most use cases. But it falls short when you have a large input array or require higher concurrency.Distributed modecan use a JSON/CSV file in S3 as input and allows up to 10,000 concurrent iterations! This is referred to as the “distributed Map” state and is priced differently.
With these two modes, you can use the Map state for fan-out/fan-in at practically any scale.
The main consideration here is the ease of configuration and cost.
Ease of configuration
Inline mode is easier to configure than Distributed mode. Both modes need an ItemProcessor to tell the state machine how to process the array items.
The Distributed mode also needs an ItemReader and optionally (but likely) a ResultWriter. This is so the state machine knows how to read the input from S3 and potentially write the results to S3 too.

In addition, you have to decide what ExecutionType to use for the distributed map.
This is an important decision.
Each iteration of the map state is executed as a child workflow. The ExecutionType setting determines if the child workflow is executed as a standard workflow or an express workflow.
Standard workflows can run for up to a year. But an express workflow can only run for five minutes. See this article [3] for a more detailed comparison of these two workflow types.
Perhaps most importantly, this decision affects how the iterations are charged.
Cost
In Inline mode, the states in the ItemProcessor are executed as part of the state machine. For a Standard Workflow, they are charged at $25 / million state transitions. For an Express Workflow, they are charged based on memory used and duration.
The Distributed mode executes each iteration as a child workflow. The ExecutionType setting dictates whether the iterations are executed as Standard Workflows or Express Workflows.
Express Workflows are priced exactly as before.
However, Standard Workflows are priced as one state transition per iteration. That is, even if an iteration executes 10 state transitions, they are priced as one state transition.

With this in mind, the Step Functions cost for processing large input arrays will not be astronomical.
However, you also need to take into account other associated costs, such as the cost of Lambda invocations. If you need to process a large array of inputs, consider processing them in batches.
Summary
Step Function’s Map state is the simplest solution for implementing fan-in/fan-out serverlessly.
It can handle workloads at any scale.
Even if you need to fan out to millions of tasks, the distributed map state can offer a cost-effective solution.
If you want a balanced solution that offers good developer productivity and cost efficiency, you should choose Step Functions.
But if cost is your primary concern, maybe because you need to produce millions of tasks frequently, then you should implement a custom solution.
Custom build solutions
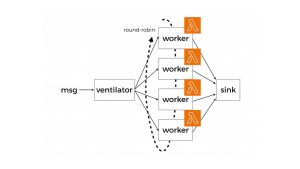
Here’s a common pattern for building a custom fan-out/fan-in solution:
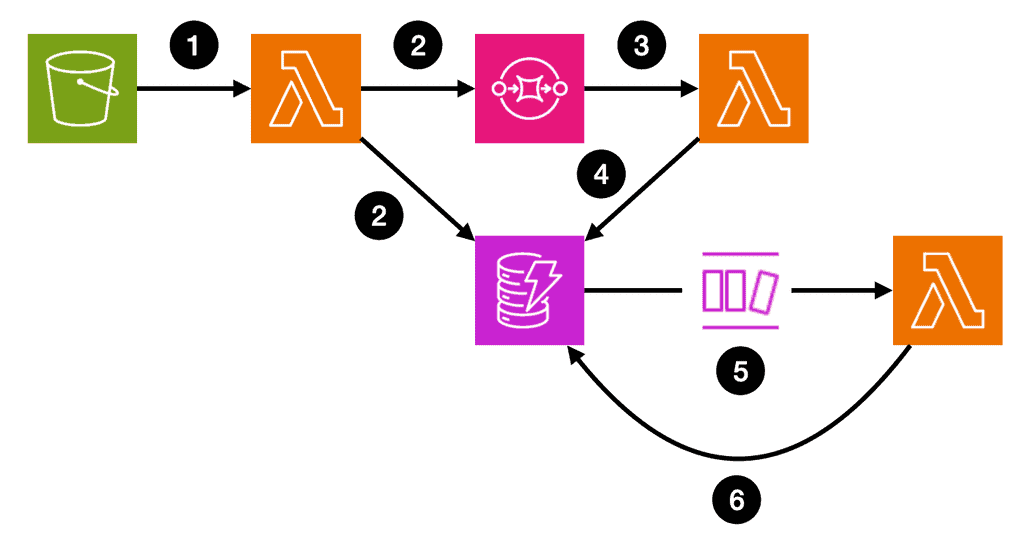
- When an input file is dropped in S3, it triggers a Lambda function to process the input file.
- The Lambda function parses the input file and fans out the items to a SQS queue. It also saves the no. of tasks in DynamoDB.
- A Lambda function processes the tasks from SQS in batches. To handle partial failures, it should implement partial batch responses [4].
- As the SQS function processes each task, it writes the intermediate result to DynamoDB.
- The data change events from step 4. are captured in a DynamoDB stream and used to trigger another Lambda function.
- This function counts the no. of newly completed tasks and updates the total no. of completed tasks in DynamoDB. When it sees all the tasks are completed, it will iterate over all the results and produce a final output.
This is likely a more cost-efficient solution than Step Functions.
There are built-in batching for the SQS and DynamoDB stream functions, courtesy of Lambda’s EventSourceMapping. So the Lambda-related processing costs will be lower.
Furthermore, here is a rough estimate for other costs (assuming one million items):
- 1 million SQS
SendMessagecalls (for fan-out): $0.40 - 1 million DynamoDB
PutItemcalls (assuming each intermediate result is smaller than 1kb): $1.25 - Assuming the DynamoDB Stream function uses a batch size of 100, we need to make 10,000 DynamoDB
GetItem&PutItemcalls to update the count (not using atomic increments because they are not reliable). $0.015 - Once all the results are in, we need to query the table to fetch all results. Assuming each result is 1kb in size, we can fetch 4 results per Read Request Unit (RRU). It will take 250,000 RRUs in total, or $0.0625.
As you can see, these estimated costs are much lower than those for Step Functions. However, this solution has many moving parts, and you have to own the uptime.
If you frequently process millions of items then a custom solution like this can make sense.
Summary
When choosing a solution, it’s not just about finding the cheapest option. It’s about getting the most value for your investment.
Remember, you get what you paid for.
Think of it like buying tools for a job. You don’t always buy the cheapest tools because they might not last. But you also don’t need the most expensive ones if they offer more than you need. You aim for the right balance – reliable enough to get the job done efficiently without overspending.
In the same way, when building your serverless architecture, choose the solution that offers the best trade-off between cost, complexity, and capability for your specific needs.
Links
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.