

Yan Cui
I help clients go faster for less using serverless technologies.

When it comes to building event-driven architectures on AWS, EventBridge has become the de facto service for ingesting, filtering, transforming and distributing events to their desired destinations. It provides a standard envelope encapsulating each event, including metadata like the source, detail type, and timestamp.
{
"version": "0",
"id": "fe8d3c65-xmpl-c5c3-2c87-81584709a377",
"detail-type": "event-type",
"source": "your-service-name",
"account": "123456789012",
"time": "2020-04-28T07:20:20Z",
"region": "us-east-1",
"resources": ["arn of event bus"],
"detail": {
// your payload
}
}
These fields are useful, but I’m gonna give you several reasons why you should wrap your event payload in its own envelope.
For example, like this:
{
// detail-type, source, etc.
"detail": {
"metadata": {
"id": "01HXHMF28A94NS7NSHC5GM80F4",
"version": "1",
"timestamp": "2020-04-28T07:20:20Z",
"domain": "order",
"service": "order-service",
"type": "order-placed"
},
"data": {
"user_id": "123456",
"order_id": "1234567890123",
"restaurant_id": "123456789",
"currency": "USD",
"total": "42.42"
}
}
}
1. Clear separation between metadata and business data
Adding a custom envelope lets you organize the structure of your events to create better separation between metadata and your business data.
You should have a standard set of metadata fields across all your events, while the payload contains only business-relevant and event-specific data. That way, when you look at the events, there is less clutter in the way.
2. Interoperability between different services
This consistent structure is especially important if you work with other messaging services, such as SNS and Kinesis as well. Having a consistent and predictable structure makes it easier to understand and parse events, especially when multiple teams or systems are involved.
It also makes it easier to write reusable code that can process events that are delivered through different messaging services.
When EventBridge forwards an event to another event bus (e.g. when you have a multi-account environment), the forwarded event has a different ID. Having adding your own event ID in the envelope, you have a consistent identifier for the event, no matter where the subscriber gets the event from.
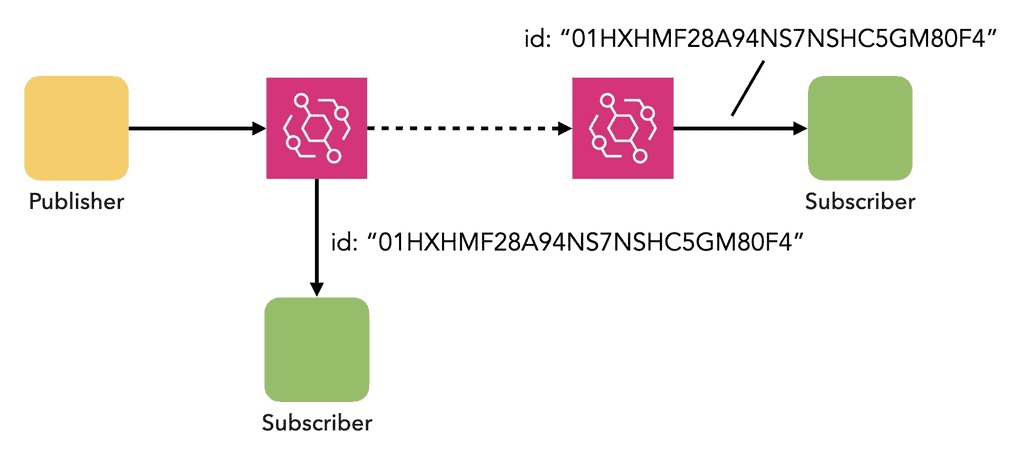
3. Better event filters
Having a standardized set of metadata fields in your envelope (like the one I showed above) means you can more easily filter events and receive only the events you want.
Yes, you can include additional fields for filtering in the event data itself. However, doing so on an event-by-event basis lacks consistency, especially across multiple teams.
Imagine you can filter events by “domain” for some teams’ events but not others. You’d have to ask the event publishing team to add those same fields so you can use the same filter across multiple teams’ events.
4. Versioning
Systems change over time, and so do the structures of your events.
Wrapping events in a custom envelope provides a better way to handle versioning and backward compatibility.
By adding a “version” field in your envelope, you can evolve your event structures without breaking existing consumers. (There’s more to this than simply adding a version attribute! But more on this in another post.)
Each consumer can check the event version and process it accordingly.
5. Idempotency
EventBridge gives you a unique ID for each event, but you should have a unique event ID in your envelope.
Because there are many ways the same domain event might be duplicated in EventBridge.
For example, when a previously failed event is reprocessed from a DLQ [1].
Or maybe the sender retries a timed-out request because it didn’t receive EventBridge’s response in time. The AWS SDK has built-in retries, so this might have happened without you realising.
If EventBridge receives the same domain event twice, it will deliver them as two separate events to the target, each with its own unique event ID.
If you forward events from EventBridge to, say, SQS, then EventBridge’s at-least-once delivery semantic can also create duplicates further downstream.
Having your own event ID helps you identify these duplicates and implement idempotency control in your processing logic.
6. Observability
You can add a correlation-id field in the envelope to help you trace through a chain of events. The field is initialized by the first publisher in the chain and reused by subsequent consumers and publishers.
That way, you can trace a user transaction through the follow-up events, too. For example, in a choreography, a microservice receives an event, does its thing and creates a follow-up event. If the initial event includes a correlation-id metadata field, the microservice will include this in its own events.
7. Audit
You should also add “createdBy” or “updatedBy” fields in the envelope as well.
This improves traceability for regulatory or debugging purposes.
What metadata fields should you have?
Here are some metadata fields that I typically include:
- id: This is the unique ID for the event.
- version
- timestamp: When you published the event, not when EventBridge received it.
- domain: Not to be confused with “service”. A domain represents a problem space that your system is supposed to address. Within a domain, you might have many services working together to solve the problem.
- service
- type: Event type.
This is a good starting point, but don’t limit yourself to these. As mentioned before, for audit purposes, you might also have fields such as “createdBy” or “updatedBy”.
What to put in the event body itself?
Ok, so that’s the metadata fields.
What about the event body itself?
Do you put a bunch of entity IDs like I did in the example above?
Or do you expand them into complete entities like this?
{
"user": { ... },
"order": { ... },
"restaurant": { ... },
"currency": "USD",
"total": "42.42"
}
Each approach has its merits and is best suited to different situations.
So, in the next post, let’s look at when you should use light events vs. rich events.
Links
[1] How to reprocess Lambda dead-letter queue messages on-demand
Related Posts





Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.