

Yan Cui
I help clients go faster for less using serverless technologies.

So that’s it for this year’s re:Invent. Werner delivered his usual insightful keynote and shared some key lessons in dealing with complexity and warning signs to look out for.

As Werner said, the number of moving parts is not a good measure of complexity on its own. And that’s something so many people get wrong about serverless – that they judge complexity by the no. of components on an architecture diagram.

Ok, on with the serverless announcements.
Aurora DSQL (pronounced “dee-sequel”) (Preview)
This is, by far, the biggest announcement of re:Invent 2024.
Aurora DSQL is a new serverless, distributed, PostgreSQL-compatible database. You can offload the complexity of ensuring your data is in sync across multiple regions. It’s built upon globally synchronized clocks that are precise to within a few microseconds.
It combines a high level of consistency guarantee with strong performance by allowing each region to operate independently without contention for most operations (except upon commit of a transaction).

The engineering behind Aurora DSQL is seriously impressive. You can get a glimpse of its inner workings during Werner’s keynote here.
Session DAT424 by Marc Brooker, the brains behind Aurora DSQL, is available on YouTube. Watch out for the recording for session DAT427, where Marc gave a deep dive on Aurora DSQL internals.
Marc has also shared a 4 part series on Aurora DSQL on his personal blog. Highly recommended!
However, Aurora DSQL is still in preview. At the time of writing, many PostgreSQL features are not supported, including, notably, foreign key constraints. There is also a long list of known issues, and the pricing structure has not yet been published.
Aurora DSQL is designed for multi-region, active-active workloads, but you can also use it in a single-region mode. Making it a potential drop-in replacement for Aurora Serverless v2.
However, now that Aurora Serverless v2 can scale to zero (covered in our pre:Invent post), is there really an argument for Aurora DSQL for single-region workloads? This is not clear to me yet, but I will update you once I have a clearer mental model of where Aurora DSQL fits in.
DynamoDB global table multi-region strong consistency (Preview)
Aurora DSQL’s cross-region replication technology is also available for DynamoDB global tables.
It’s not a free lunch. Strongly consistent global tables have higher write and strongly-consistent read latencies. It’s a trade-off between latency and consistency.
If an item is simultaneously updated in two regions, then one of the write operations will fail with a “ReplicatedWriteConflictException” exception.
S3 Tables
S3 Tables is a new type of S3 bucket with native support for Apache Iceberg. It’s specifically optimized for analytics workloads and lets you query tabular data (e.g. Parquet files) up to 3x faster, with 10x higher throughput compared to self-managed tables.
If you use Athena, Redshift, EMR, or QuickSight to query tabular data in S3, you should move your data to S3 Tables.
Here’s how it compares to S3 standard on price:
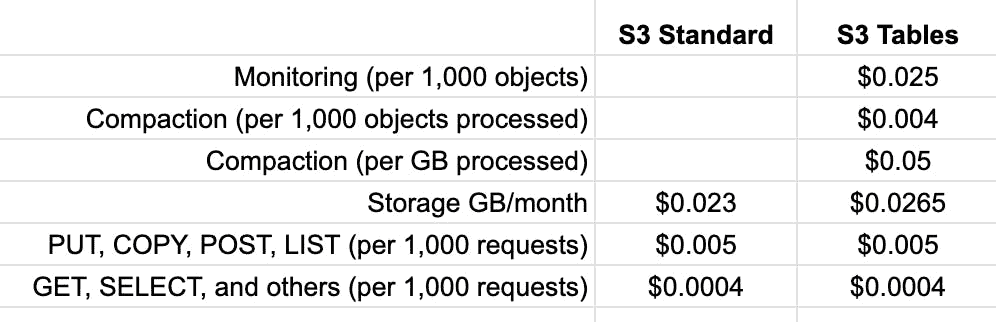
Notice that there is additional data monitoring and compaction costs. These are inline with the likes of S3 intelligent tiering. For the query performance improvements, the pricing makes sense.
S3 Metadata (Preview)
When enabled, S3 will collect system-defined metadata and user-defined metadata about your objects and make them queriable through the likes of Athena, Redshift, EMR and Apache Spark.
It makes easy to find objects by tag, created date, size, content type, storage class and so on.
There is a cost of $0.45 per million object updates.
OpenSearch can query CloudWatch Logs directly
I haven’t tried this myself, but this is a big deal for a lot of companies. You no longer need to duplicate log data to OpenSearch in order to query them. You just need to set up a data source in OpenSearch Discover and can start querying the logs in-place. Pretty sweet!
EventBridge and Step Functions can access private APIs through PrivateLink and VPC Lattice
Many AI updates
New multi-modal Nova foundational models
Bedrock supports multi-agent collaboration
Guardrails for Amazon Bedrock can now detect hallucinations
Guardrails supports multi-modal detection of image content
Bedrock intelligent prompt routing
Bedrock model evaluation now includes a LLM-as-a-judge
Related Posts

Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.