

Yan Cui
I help clients go faster for less using serverless technologies.

I recently helped a client launch an AI code reviewer called Evolua [1]. Evolua is built entirely with serverless technologies and leverages Bedrock. Through Bedrock, we can access the Claude models and take advantage of its cross-region inference support, among other things.
In this post, I want to share some lessons from building Evolua and offer a high level overview of our system.
But first, here’s some context on what we’ve built.
Here [2] is a quick demo of Evolua:
Architecture
This is a high-level view of our architecture.
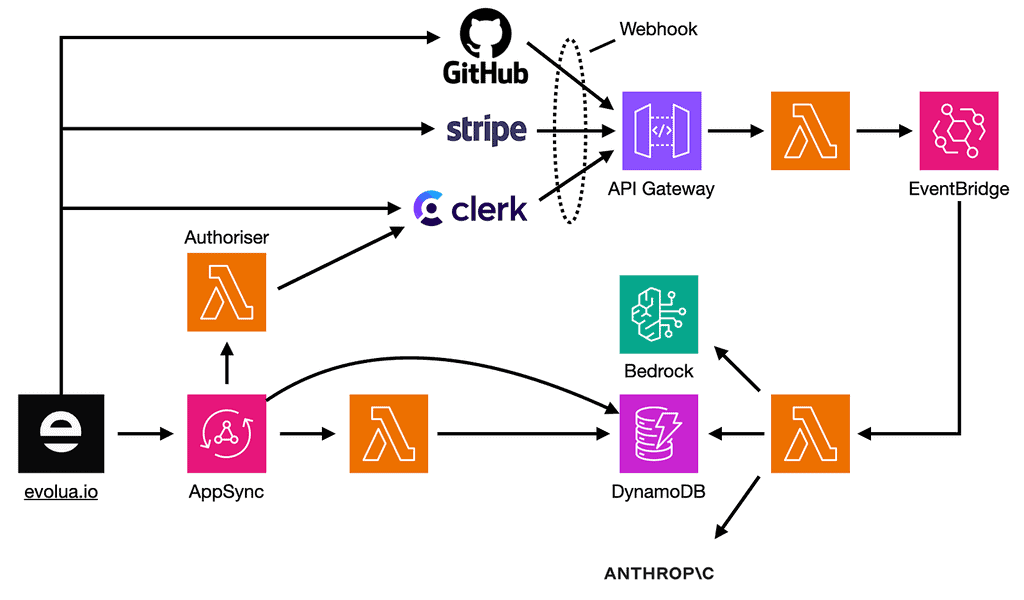
Here are some noteworthy points:
- AppSync as the BFF (Backend-for-Frontend): We chose AppSync for the Evolua frontend application. However, we still need an API Gateway for handling various webhooks.
- EventBridge for Webhooks events: Webhook events are published to an EventBridge bus. The events are wrapped in a custom envelope [3] to simplify creating subscription rules.
- Consistent Event Schema: We opted against EventBridge’s 3rd party event integration (which can handle webhook ingestion for us) to maintain a consistent event schema and gain more visibility into incoming events.
- Clerk for Authentication: Clerk was chosen over Cognito because it offers better coverage of Git providers and supports organizational workflows like inviting users. Its built-in UI components also allowed us to move from idea to production quickly.
- Claude 3.5 Sonnet for Code Reviews: We use Claude 3.5 Sonnet through Bedrock for code reviews but also set up a fallback with Anthropic’s API for resilience (more on this below).
Why Bedrock?
We chose Bedrock over alternatives (like self-hosting models) primarily for security reasons.
Bedrock gives a written guarantee that:
- Your data is encrypted at rest.
- Your input and outputs are not shared with model providers.
- Your input and outputs are not used to train other models.
See the official FAQ page here [4].

These guarantees are critical because we process customer source code files, which may contain sensitive information and trade secrets.
Other reasons we chose Bedrock include:
- Cost-effective at any scale: Pay-per-use pricing is ideal for starting out, and provisioned throughput mode offers a path to scale cost-effectively.
- Wide range of capabilities: Beyond hosting LLMs, Bedrock supports cross-region inference, knowledge bases, guardrails, RAG and agents.
However, Bedrock is not without issues.
For instance, we were affected by a widely-reported issue [5] where AWS reset many customer’s Bedrock quotas to 0, rendering Bedrock unavailable.

The incident delayed our launch and prompted us to implement a fallback mechanism.
Lessons from building an AI-powered code reviewer
We often have to pass along large text files to the LLM for code reviews. Sometimes processing many of them as part of a single pull request (PR).
This differs from the typical chatbot use cases. The size and quantity of the files impacts both costs and limits.
LLMs are still quite expensive.
Reviewing PRs with thousands of lines can become expensive quickly, especially with models like Sonnet. While batching mode reduces costs, it adds complexity and can affect performance.
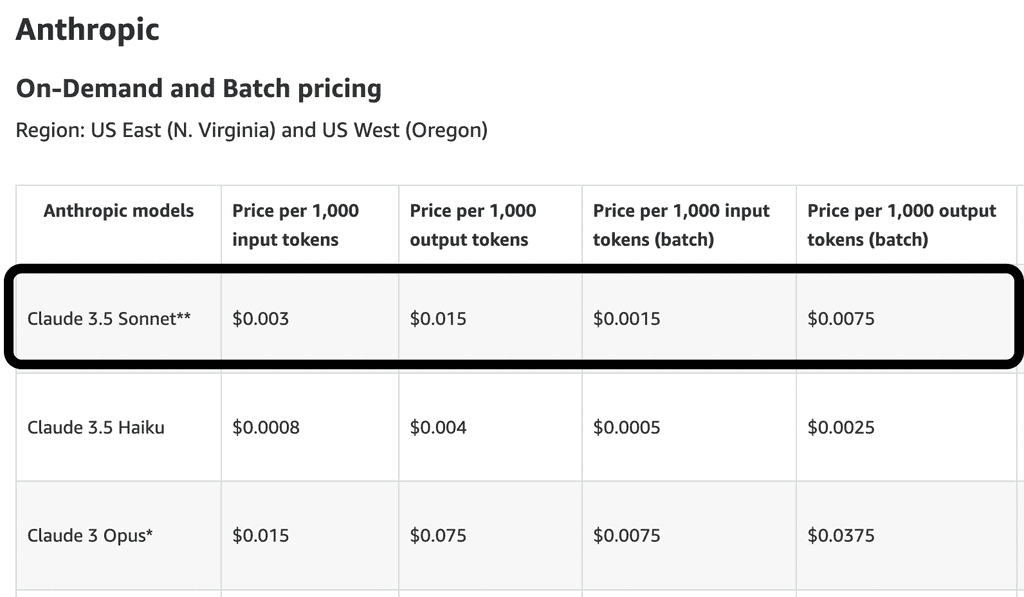
This makes it difficult to build a sustainable and competitive business model. Without VCs funding to absorb the cost of growth, it’s a tough balancing act between:
- building differentiating features with the latest AI capabilities, and
- offering a competitive pricing
Mind the model limits.
For example, Claude 3.5 Sonnet has a context window of 200k and a maximum output of 8192 tokens.
These are sufficient in most cases, still present challenges. For example,
- A large source file with thousands of lines of code can exceed the context window limit.
- A source file with so many issues may generate outputs exceeding 8192 tokens.
Furthermore, for Claude 3.5 Sonnet, both Bedrock and Anthropic have a default throughput limit of a measly 50 inferences per minute.
You can improve this throughput limit with cross-region inference [6] and request an account-level limit raise. You can also fall back to a less powerful model, such as Claude 3 Sonnet or Claude 3.5 Haiku, with higher throughput limits.
Latency challenges.
As you can see from the following trace in Lumigo [7], Bedrock takes 20 to 30s to review one file.
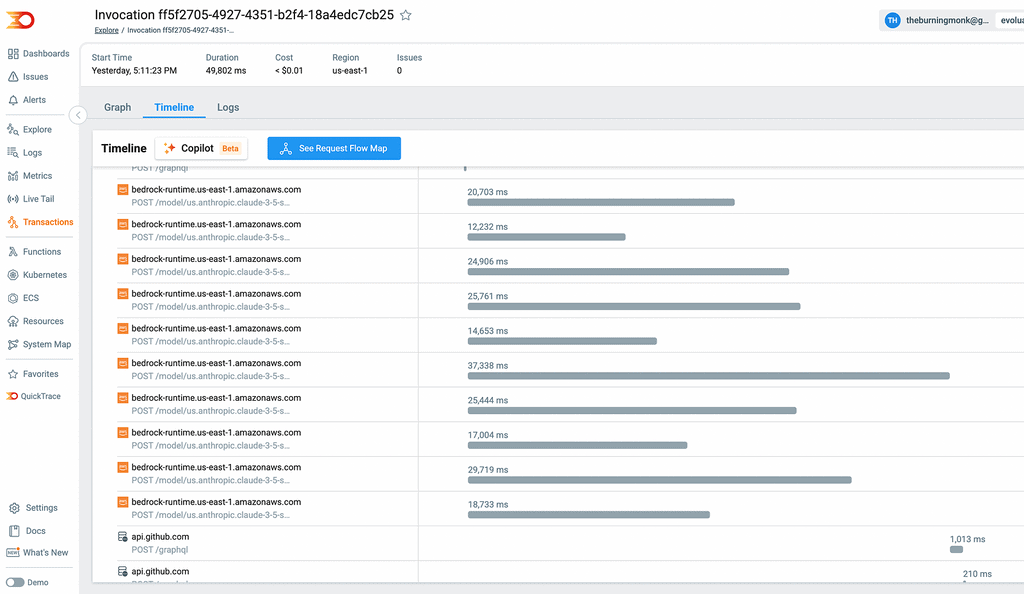
Given the limited throughput and to avoid having one user exhaust all available throughput, we limit the number of concurrent requests to Bedrock per user.
As such, large PRs can take several minutes to process. This presents a problem for user experience.
It may take so long that the Lambda function times out (Lambda has a max timeout of 15 minutes), and the user doesn’t receive any results.
You may also need to add heartbeat comments to the PR to inform the user that you’re still working on the review.
Hallucinations is still a problem.
Occasionally, the LLM identifies issues with non-existent line numbers or unrelated problems.
These hallucinations happen rarely, but they do still happen.
As a mitigation, you can use another LLM (perhaps a cheaper one) to verify the output (at the cost of latency and expense).
The LLM is the easy part.
One of my biggest takeaways is that the LLM is the easy part.
While selecting the right model and crafting an effective prompt is important, it’s a small piece of the overall system.
Most of our effort went into building the developer experience around the LLM. This includes:
- Optimizing workflows for user experience.
- Ensuring system reliability.
- Improving system performance and response time.
The overall developer experience is the true differentiation for the product, not the LLM or the prompts.
With so much hype around AI, it’s easy to overlook the importance of the “app” in an “AI-powered app.”
Why AI code reviewers matter
Both Sam and I use AI tools heavily in our development workflow, including ChatGPT, Claude, Cursor, CodePilot and Amazon Q.
While these tools are incredibly useful, they often produce suboptimal or insecure code. Luckily, Evolua will identify these coding issues as soon as we open the PR!
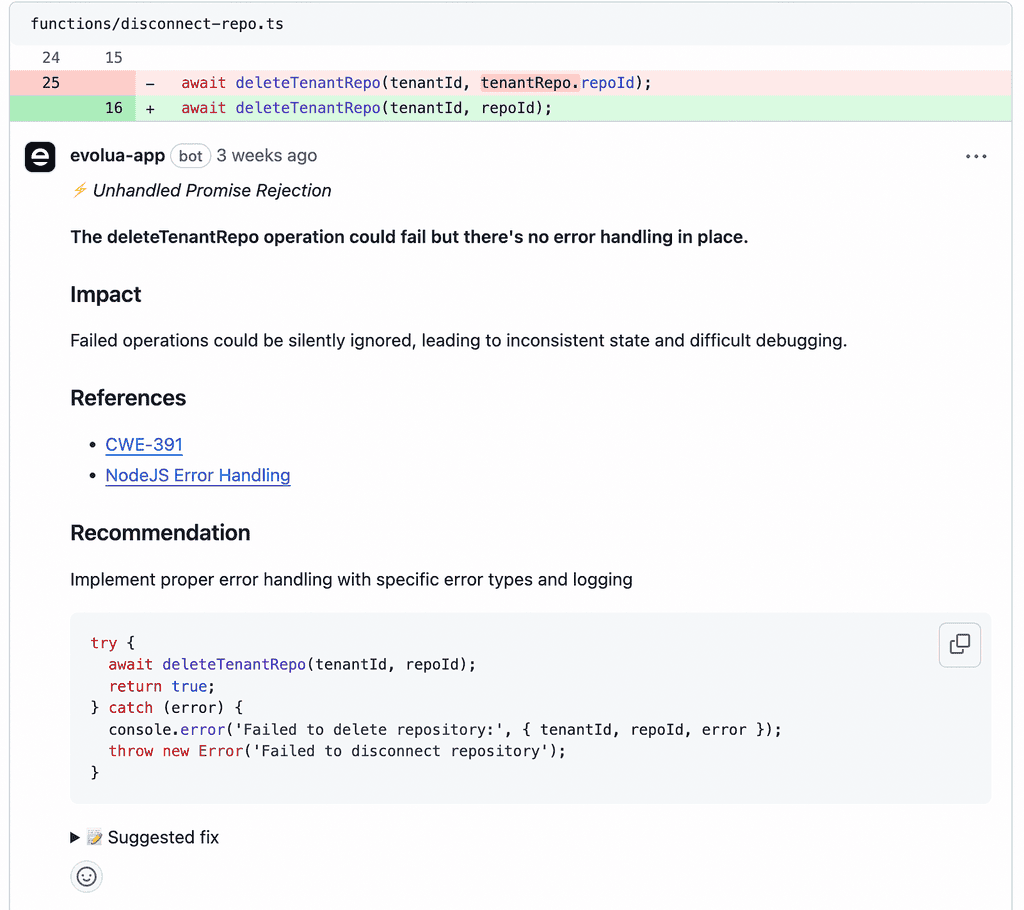
If you’ve been using AI to write code, you should try Evolua today to catch bad code before it reaches production. ;-)
Links
[2] Demo of Evolua
[3] EventBridge best practice: why you should wrap events in event envelopes
[4] Bedrock FAQs
[5] Reddit: Why did AWS reset everyone’s Bedrock Quota to 0? All production apps are down
[6] Improve throughput with cross-region inference
[7] Lumigo, the best observability platform for serverless architectures
Related Posts



Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.