
Yan Cui
I help clients go faster for less using serverless technologies.

The most common issue I have encountered in production are latency/performance related. They can be symptoms of a whole host of underlying causes ranging from AWS network issues (which can also manifest itself in latency/error-rate spikes in any of the AWS services), over-loaded servers to simple GC pauses.
Latency issues are inevitable – as much as you can improve the performance of your application, things will go wrong, eventually, and often they’re out of your control.
So you must design for them, and degrade the quality of your application gracefully to minimize the impact on your users’ experiences.
As backend developers, one of the fallacies that we often fall into is to allow our dev environments to be too lenient. Servers and databases are never under load during development, so we lure client developers into a false sense of comfort and set them up to fail when the application runs into a slow-responding server in production for the first time.
Latency Injection
To program my fellow client developers to always be mindful of latency spikes, we decided to inject random latency delays on every request:
- check if we should inject a random delay;
- if yes, then work out how much latency to inject and sleep the thread;
- and finally invoke the original method to process the request
This is an implementation pattern that can be automated. I wrote a simple PostSharp attribute to do this, whilst piggybacking existing configuration mechanisms to control its behaviour at runtime.
Then I multicast the attribute to all our service endpoints and my work was done!
We run latency injection in our dev environment and it helped identify numerous bugs in the client application as a result and proved to be a worthwhile exercise.
But we didn’t stop there.
Error Injection
We throttle user requests to all of our services to stop mischievous players from spamming our servers using proxy tools such as Charles and Fiddler, or handcrafted bots.
But, occasionally, legitimate requests can also be throttled as result of client bugs, over-zealous retry strategy or incorrectly configured throttling threshold.
Once again, we decided to make these errors much more visible in the dev environment so that client developers expect them and handle them gracefully.
To do that, we:
- set the threshold very low in dev
- used a PostSharp attribute to randomly inject throttling error on operations where it makes sense
The attribute that injects throttling error is very simple, and looks something along the lines of:
The same approach can be taken to include any service specific errors that the client should be able to gracefully recover from – session expiration, state out-of-sync, etc.
Design for Failure
Simulating latency issues and other errors fall under the practice of Design for Failure, which Simon Wardley identifies as one of the characteristics of a next-generation tech company.

p.s. you should check out Simon’s work on value chain mapping if you haven’t already, they’re inspiring.
Chaos Engines
Netflix’s use of Chaos Monkey and Chaos Gorilla is a shining example of Design for Failure at scale.
Chaos Monkey randomly terminates instances to simulate hardware failures and test your system’s ability to withstand such failures.
Chaos Gorilla takes this exercise to the next level and simulate outages to entire Amazon availability zones to test their system’s ability to automatically re-balance to other availability zones without user-visible impact or manual intervention.
Netflix has taken a lot of inspiration from Release It! by Michael Nygard and Drift into Failure by Sidney Dekker. Both books are awesome and I highly recommend them.


Global redundancy, or not
Based on reactions to AWS outages on social media, it’s clear to see that many (ourselves included) do not take full advantage of the cloud for global redundancy.
You might scoff at that but for many the decision to not have a globally redundant infrastructure is a conscious one because the cost of such redundancy is not always justifiable.
It’s possible to raise your single-point-of-failure (SPOF) from individual resources/instances, to AZs, to regions, all the way to cloud providers.
But you’re incurring additional costs at each turn:
- your infrastructure becomes more complex and difficult to reason with;
- you might need more engineers to manage that complexity;
- you will need to invest in better tooling for monitoring and automation;
- you might need more engineers to build those tools;
- you incur more wastage in CPU/memory/bandwidth/etc. (it is called redundancy for a reason);
- you have higher network latency for cross-AZ/region communications;
Global redundancy at Uber
On the other hand, for many organizations the cost of downtime outweighs the cost of global redundancy.
For instance, for Uber’s customers the cost of switching to a competitor is low, which means availability is of paramount importance for Uber.
Uber devised a rather simple, elegant mechanism for their client applications to failover seamlessly in the event of a datacentre outage. See this post for more details.
Latency Propagation
Finally, as more and more companies adopt a microservices approach a whole host of challenges will become evident (many of which have been discussed in Michael Nygard’s Release it!).
One of these challenges is the propagation of latency through inter-service communications.
If each of your services have a 99 percentile latency of 1s then only 1% of calls will take longer than 1s when you depend on only 1 service. But if you depend on 100 services then 63% of calls will take more than 1s!
In this regard, Google fellow Jeff Dean’s paper Achieving Rapid Response Times in Large Online Services presents an elegant solution to this problem.
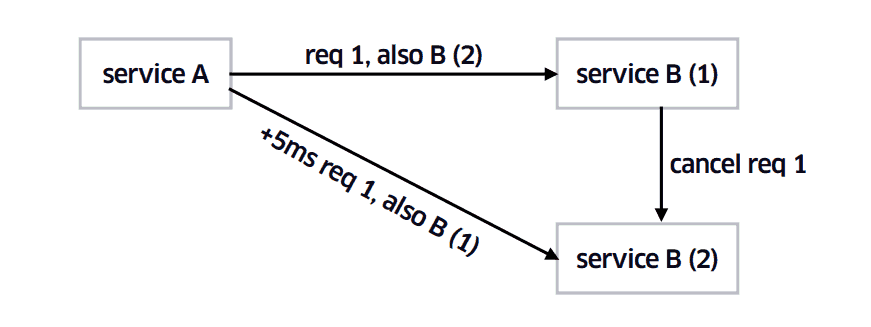
I haven’t put this into practice myself, but I imagine this can be easily implemented using Rx’s amb operator.
Links
- The Netflix Simian Army
- Simon Wardley – Introduction to value chain mapping
- Jeff Dean – Achieving rapid response time in large online services
- QCon London 15 – takeaways from “Scaling Uber’s realtime market platform”
- Hacking the brains of other people with API design
- Design Pattern Automation
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
I’m curious if PostSharp provides a Timeout attribute for methods.
That would be an awesome feature.
As far as I know there isn’t a built-in aspect for forcing a method to timeout, but it’s possible to build one yourself and it’d relatively easy to do I’d imagine. Maybe I’ll do a simple example later on.
But you have to be mindful of the context the timeout happens in, e.g. for operations that updates your state, would a forced timeout leave u with dirty writes? how would you handle failover, etc.
In my own opinion, I would handle your concern by implementing an Eventual Consistency pattern. Specifically, I would log all request timeouts for another process to resolve later.
I think timeouts can be used as a strategy to manage a failed operation so that it doesn’t create a chain reaction throughout the rest of the system.
As a result, I believe all IO operations could be candidates for timeouts.
What do you think?
Not sure how eventual consistency comes into play here, but sounds like you’ve already given it some thought and you’re the best judge of your particular scenario. If you’re gonna log failed/timed out operations to another service then remember that service itself could also fail/timeout.
Michael Nygard’s Release It! goes into a lot of details on prevention of cascading failures and chain reactions, timeouts are circuit breakers are both high up the list of good patterns. Ultimately failures are inevitable, it’s more important that we understand our failure modes and mitigate them the best we can. It’s usually the unknown unknown that’s really scary!
Definitely agree on all IO operations should be candidates for sensible timeouts as well as protected by circuit breakers. Just found out today that you can even report tripped circuit breakers to Consul so that info could be propagated quickly through your consumers, which can come in handy too.
Pingback: How can we apply the principles of chaos engineering to AWS Lambda? | theburningmonk.com