
Yan Cui
I help clients go faster for less using serverless technologies.

In the last post I compared the coldstart time for Lambda functions with different language, memory and code size. One of the things I learnt was that idle functions are no longer terminated after 5 minutes of inactivity.
/2017/06/aws-lambda-compare-coldstart-time-with-different-languages-memory-and-code-sizes/
It is a fantastic news and something that Amazon has quietly changed behind the scene. However, it lead me to ask some follow up questions:
- what’s the new idle time that would trigger a coldstart?
- does it differ by memory allocation?
- are functions still recycled 4 hours from the creation of host VM?
To answer the first 2 questions, I devised an experiment.
First, here are my hypotheses going into the experiment.
WARNING: this experiment is intended to help us glimpse into implementation details of the AWS Lambda platform, they are fun and satisfy my curiosity but you shouldn’t build your application with the results in mind as AWS can change these implementation details without notice!
Hypotheses
Hypothesis 1 : there is an upper bound to how long Lambda allows your function to stay idle before reclaiming the associated resources
This should be a given. Idle functions occupy resources that can be used to help other AWS customers scale up to meet their needs (and not to mention the first customer is not paying for his idle functions!), it simply wouldn’t make any sense for AWS to keep idle functions around forever.
Hypothesis 2 : the idle timeout is not a constant
From an implementor’s point-of-view, it might be simpler to keep this timeout a constant?—?ie. functions are always terminated after X mins of inactivity. However, I’m sure AWS will vary this timeout to optimise for higher utilisation and keep the utilisation levels more evenly distributed across its fleet of physical servers.
For example, if there’s an elevated level of resource contention in a region, why not terminate idle functions earlier to free up space?
Hypothesis 3 : the upper bound for inactivity varies by memory allocation
An idle function with 1536 MB of memory allocation is wasting a lot more resource than an idle function with 128 MB of memory, so it makes sense for AWS to terminate idle functions with higher memory allocation earlier.
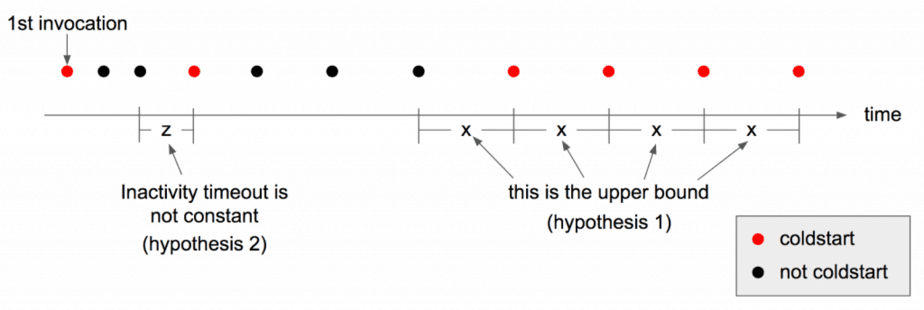
Experiment : find the upper bound for inactivity
To find the upper bound for inactivity, we need a Lambda function to act as the system-under-test and report when it has experienced a coldstart. We also need a mechanism to progressively increase the interval between invocations until we arrive at an interval where each invocation is guaranteed to be a coldstart?—?the upper bound. We will determine the upper bound when we see 10 consecutive coldstarts when invoked X minutes apart.
To answer hypothesis 3 we will also replicate the system-under-test function with different memory allocations.
This experiment is a time consuming process, it requires discipline and a degree of precision in timing. Suffice to say I won’t be doing this by hand!
My first approach was to use a CloudWatch Schedule to trigger the system-under-test function, and let the function dynamically adjust the schedule based on whether it’s experienced a coldstart. It failed miserably?—?whenever the system-under-test updates the schedule the schedule will fire shortly after rather than wait for the newly specified interval…
Instead, I turned to Step Functions for help.
AWS Step Functions allows you to create a state machine where you can invoke Lambda functions, wait for a specified amount of time, execute parallel tasks, retry, catch errors, etc.
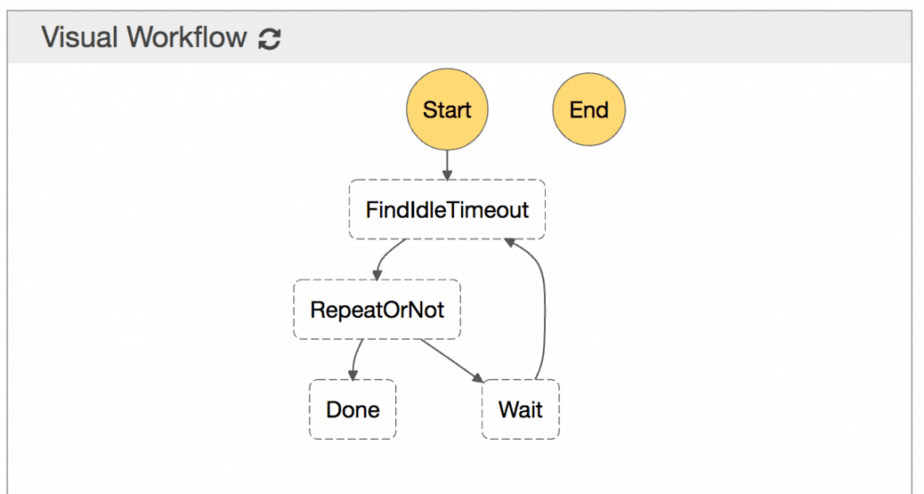
A Wait state allows you to drive the no. of seconds to wait using data (see SecondsPath param in the documentation). Which means I can start the state machine with an input like this:
{
“target”: “when-will-i-coldstart-dev-system-under-test-128”,
“interval”: 600,
“coldstarts”: 0
}The input is passed to another find-idle-timeout function as invocation event. The function will invoke the target (which is one of the variants of the system-under-test function with different memory allocations) and increase the interval if the system-under-test function doesn’t report a coldstart. The find-idle-timeout function will return a new piece of data for the Step Function execution:
{
“target”: “when-will-i-coldstart-dev-system-under-test-128”,
“interval”: 660,
“coldstarts”: 0
}Now, the Wait state will use the interval value and wait 660 seconds before switching back to the FindIdleTimeout state where it’ll invoke our system-under-test function again (with the previous output as input).
"Wait": {
"Type": "Wait",
"SecondsPath": "$.interval",
"Next": "FindIdleTimeout"
},
With this setup I’m able to kick off multiple executions?—?one for each memory setting.
{
"Comment": "How long AWS Lambda keeps idle functions around?",
"StartAt": "FindIdleTimeout",
"States": {
"FindIdleTimeout": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:{account_id}:function:when-will-i-coldstart-dev-find-idle-timeout",
"Next": "RepeatOrNot"
},
"RepeatOrNot": {
"Type" : "Choice",
"Choices": [
{
"Variable": "$.coldstarts",
"NumericEquals": 10,
"Next": "Done"
}
],
"Default": "Wait"
},
"Wait": {
"Type": "Wait",
"SecondsPath": "$.interval",
"Next": "FindIdleTimeout"
},
"Done": {
"Type" : "Succeed"
}
}
}
Along the way I have plenty of visibility into what’s happening, all from the comfort of the Step Functions management console.
Here are the results of the experiment:
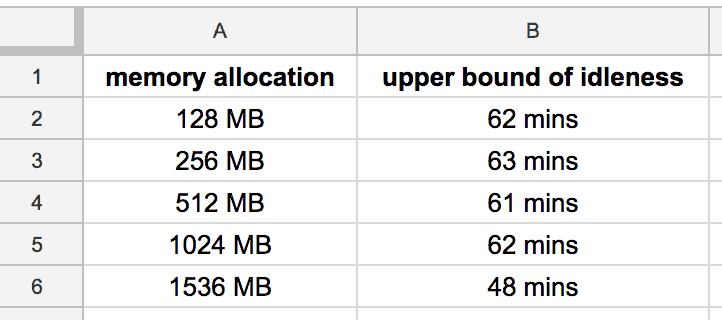
From the data, it’s clear that AWS Lambda shuts down idle functions around the hour mark. It’s also interesting to note that the function with 1536 MB memory is terminate over 10 mins earlier, this supports hypothesis 3.
I also collected data on all the idle intervals where we saw a coldstart and categorised them into 5 minute brackets.

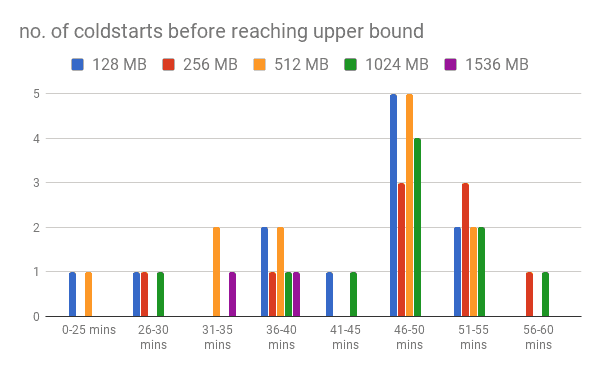
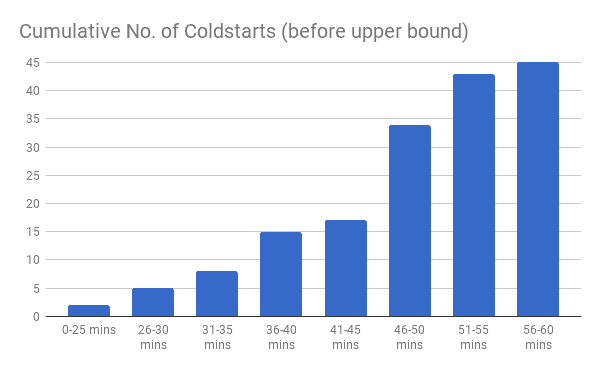
Even though the data is serious lacking, but from what little data I managed to collect you can still spot some high level trends:
- over 60% of coldstarts (prior to hitting the upper bound) happened after 45 mins of inactivity
- the function with 1536 MB memory sees significantly fewer no. of cold starts prior to hitting the upper bound (worth noting that it also has a lower upper bound (48 mins) than other functions in this test
The data supports hypothesis 2 though there’s no way for us to figure out the reason behind these coldstarts or if there’s significance to the 45 mins barrier.
Conclusions
To summary the findings from our little experiment in one line:
AWS Lambda will generally terminate functions after 45–60 mins of inactivity, although idle functions can sometimes be terminated a lot earlier to free up resources needed by other customers.
I hope you find this experiment interesting, but please do not build applications on the assumptions that:
a) these results are valid, and
b) they will remain valid for the foreseeable future
I cannot stress enough that this experiment is meant for fun and to satisfy a curious mind, and nothing more!
The results from this experiment also deserve further investigation. For instance, the 1536 MB function exhibited very different behaviour to other functions, but is it a special case or would functions with more than 1024 MB of memory all share these traits? I’d love to find out, maybe I’ll write a follow up to this experiment in the future.
Watch this space ;-)
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
I found that AWS kills nodejs lambdas after 30 minutes. It was accidental but if the code connects to an RDS database using pg-pool outside the handler but don’t have any schema the pool keeps trying to connect into the database even after the function invocation is done. The connection finally dropped after 30 minutes. I’ll try to put up a POC.
Hi Joe, is that 30 mins pretty consistent? Also, when was the last time you saw that?
I tried making a POC (outside of our internal code) and fell asleep. Doh. It’s on my mind but I might not have time for a while, family, work, life etc. Will try to make it when I can.
So I finally got the POC going the way I thought it would stoke the problem however I think when amazon fixed the other timeout issue (https://twitter.com/AWSSupport/status/880561732741103620), it fixed this as well.
I’m guessing the connection was being left open due to the error retry loop. No idea.
Here is the POC repo. I included the screenshot of the 30 minute connection (its a screenshot of the screenshot b/c I pasted it into a doc so the filename date is off). I swear it happened! :)
https://github.com/joekiller/cljs-rds-backpoller
Thank you for the great blog posts.