

Yan Cui
I help clients go faster for less using serverless technologies.

The Register published an article right before Christmas 2018. It talks about inflated serverless costs, but it largely misses the point and focuses on the wrong workloads.
The whitepaper the article refers to provides some interesting analysis. However, the case studies it used to make its point are not representative of what most developers do. Model Training and Low-Latency Prediction Serving via Batching might represent what the researchers themselves do. But they are not typical of the industry at large. It’s easy to blow the limitations out of proportion when you only look at workloads that highlight Lambda’s weaknesses.
I have written many articles [2] on the limitations of AWS Lambda myself and shared many of my workarounds. Indeed, plenty of developers who have worked with serverless in production would tell you that it has many limitations. Serverless is not a good fit for some workloads, but it works great for many other workloads. When used correctly, serverless puts a lot of power in the hands of developers.
Think TCO, not just Lambda cost
I’d like to focus on one of the points the article and whitepaper touched on – cost.
Again, the paper looked at the AWS Lambda service cost with workloads that don’t go well with the pay-per-invocation model. It’s no surprise that they arrived at the conclusion they did.

But when AWS Lambda is used to solve the right problems, others have found cost savings of up to 90% [3] in the real world!

If I wear my shoes on my hands, should I really be surprised that my feet are cold?
Furthermore, for the workloads discussed in the paper, there are other more pressing costs to consider. Most companies would hit these issues long before seeing the inflated Lambda costs. The cost of hiring people with ML experience has gone crazy [4]. Big tech companies are paying PhD Machine Learning graduates (!) hundreds of thousands of dollars a year in salary and stocks.

Most companies won’t have the luxury of worrying about the cost of using AWS Lambda to train their ML models. They can’t even hope to compete for the engineering talents they need to design these workloads in the first place. This brings me to the biggest cost savings from serverless that has been barely talked about: the saving in personnel costs.
Do more with fewer people
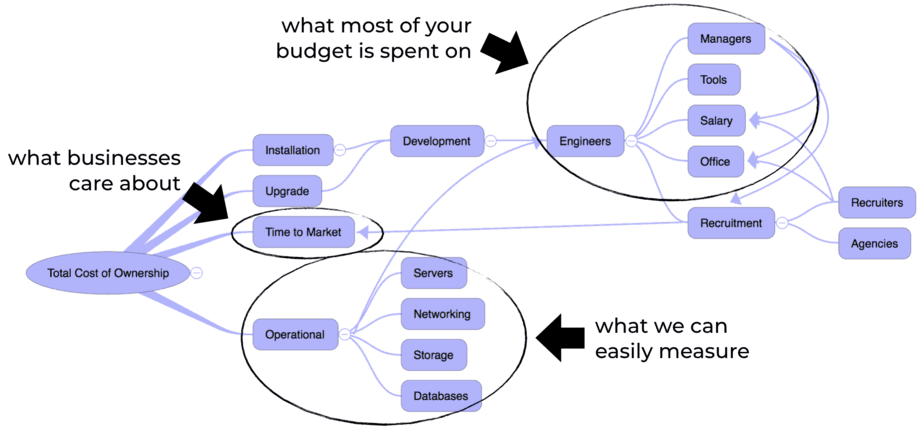
Let’s take a moment to consider our Total Cost of Ownership (TCO).
There are the charges that go into your monthly AWS bill: service costs, data transfers, etc. These costs are easy to measure and are too often the only thing we measure when it comes to cost.
Yet, it often pales in comparison with engineer salaries. On average, a software engineer in London can earn around £80,000 a year, which is roughly $100,000. You might even have to tap into the contractor market for sought-after skills such as AWS and DevOps. A contractor with AWS and DevOps experience can set you back anything between £550 and £800 per day.
With serverless, you can delegate even more ops responsibilities to your cloud provider. Patching OS, provisioning and scaling servers, setting up load balancers, etc. This frees your developers from many undifferentiated heavy lifting. It allows them to better focus on building the things that matter to your customers.
In general, you don’t need as many specialised tools. Deployment and CI/CD become simpler, and you get basic monitoring and logging support out of the box. When you outgrow the native tools, such as CloudWatch Logs, it’s easy to integrate with external solutions.
While a learning curve is still involved, it’s much shallower than the alternative. Mastering Docker, Kubernetes, Istio/Linkerd, and related DevOps tools, is no small feat. Many startups won’t have DevOps expertise from day 1. Having the cloud provider take care of most of the plumbing means they can defer hiring a DevOps specialist. As mentioned earlier, that is a huge cost saving, in the order of $100,000+ per year per engineer!
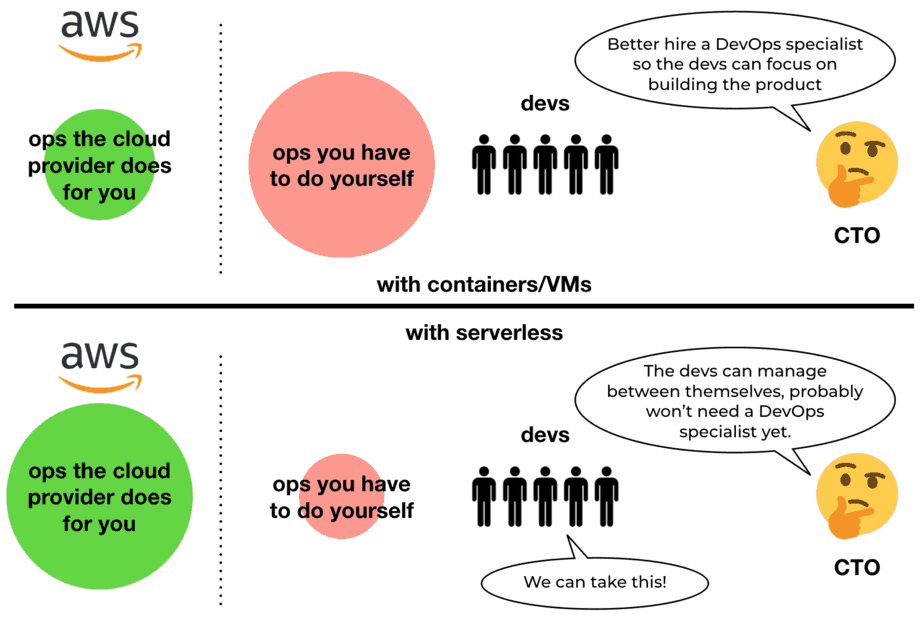
At Yubl, as we migrated most of our services to serverless [5], we were able to disband the DevOps team. The developers were more than capable of taking on the remaining ops responsibilities.
As the paper discussed, the pay-per-invocation model doesn’t fit some workloads. In these cases, you can pay a lot more with Lambda than with containers or VMs. However, when you calculate the true cost of a solution, you need to factor in the cost of engineers you need to support the solution. At the risk of generalising, I would wager that for 90% of companies, the balance is heavily tipped towards the cost of engineers.

Then there’s the matter of opportunity costs.
Consider opportunity costs
While the first-mover advantage is not guaranteed market success, the ability to iterate faster than your competitors is certainly a business advantage. Freeing your developers of the undifferentiated heavy lifting of managing the underlying compute infrastructure lets them move faster, which in turn means you, as a business, can test your ideas against the market quicker and iterate faster.
It also means you can get more done with fewer developers. This means less organizational communication overhead. And it means less time and money spent on recruitment, and more time spent on the product.
In startups, and perhaps in life in general, time is the most scarce resource.
– Yevgeniy Brikman, co-founder of Gruntwork
(source)
Conclusions
The pay-per-invocation model is new to many, and it’s right that we talk about its potential. But I can’t help but feel that we are only thinking about it in a limited way – how much money it can save us when our code is not running.
Understanding the true cost of our decisions is complex. With this post/rant I want to make you think about less obvious elements that contribute towards our TCO. Elements that are usually far more significant than the headline number we see in our AWS bill each month. Elements that we, as developers, are not accustomed to think about.
And we haven’t even touched on the idea of FinDev, which was coined by Simon Wardley. The pay-per-invocation model allows cost to be allocated on each user transaction. It gives you true visibility into the return-on-investment (ROI) of different features, and allow businesses to make informed decisions based on that. But that’s another post for another time.
Links
[1] Serverless Computing: One Step Forward, Two Steps Back
[2] All my articles on serverless
[3] Edelman Financial Engines cuts cost by 90% using Lambda and serverless compute
[4] AI researchers are making more than $1 million a year
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.