
Yan Cui
I help clients go faster for less using serverless technologies.

With serverless, you delegate the responsibility of running your infrastructure to a platform provider as much as possible. This frees your engineers to focus on building what your customers want from you—the features that differentiate your business from your competitors’. For this philosophy to work, however, the platform needs to not only give you the tools to build those features, but also deliver the performance that will keep engineers satisfied.
Yes, services such as AWS Lambda are powerful, but they have a number of well-documented limitations that make them unsuitable for some workloads. These include:
- Cold starts and high latency make them unsuitable for real-time applications that require consistent and millisecond-level response times.
- The pay-per-invocation model makes them costly in high throughput scenarios.
- The event-driven model, coupled with a max execution time or data size restrictions, makes them unsuitable for long-running tasks or heavy data or AI processing.
- They are limited to triggers and event sources that are specific to the cloud provider.
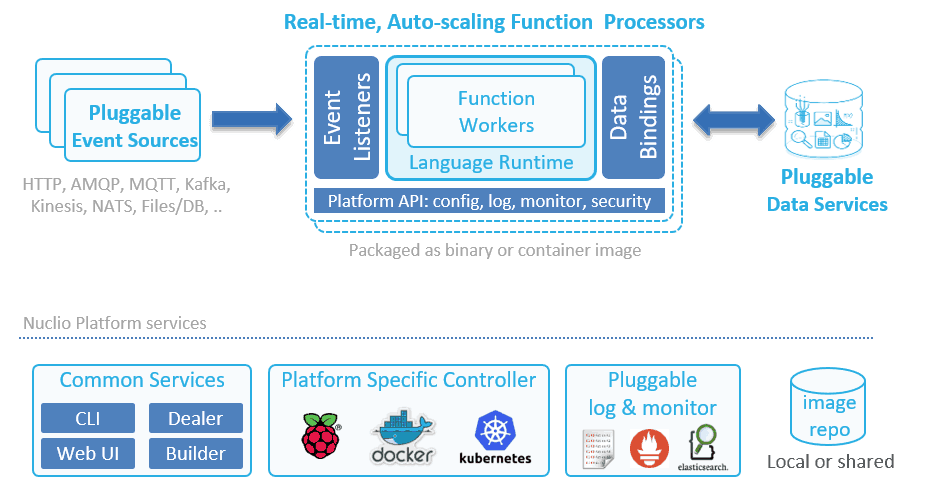
Enter Nuclio, an open source serverless platform that is built on top of Kubernetes and comes in both managed platform-as-a-service (PaaS) and self-hosted flavors. In this post, we will compare Nuclio with AWS Lambda, see how Nuclio addresses the above limitations and explore the new use cases Nuclio is unlocking, such as:
- High throughput data processing pipelines or ETL.
- Serving machine learning models in real time.
- Real-time applications such as multiplayer games.
- Long-running jobs and services.
Nuclio vs. AWS Lambda
Concurrency
One of the biggest shifts from traditional application development to AWS Lambda is how concurrency is managed. An Express.js web application running in a container/VM can handle multiple requests concurrently. In other words, your application manages its own concurrency. You scale the application by increasing the number of concurrent requests it can handle (scaling up) and then increasing the number of containers (scaling out).
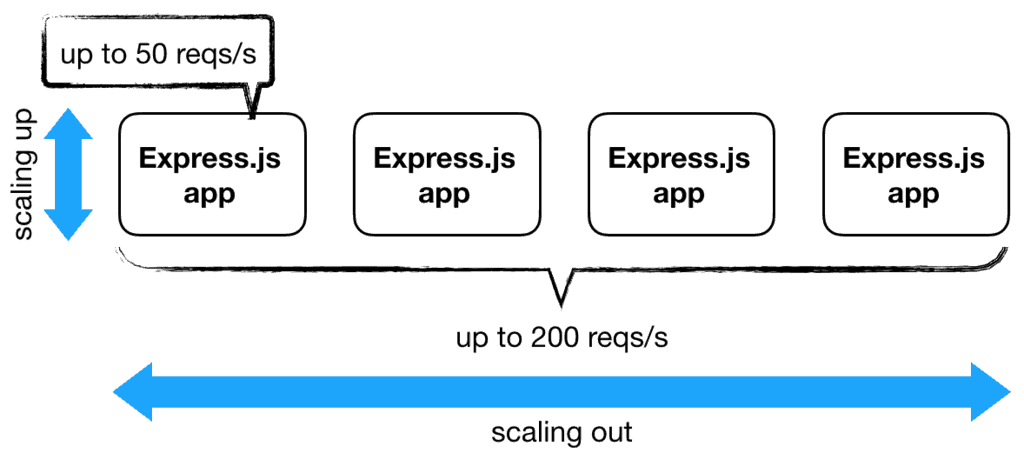
With AWS Lambda, concurrency is managed by the platform, and a concurrent execution would process only one request at a time—much like an actor in the actor model, which would process one message at a time. The application can scale out by increasing the number of concurrent executions of the function.
Lambda’s concurrency model has its advantages:
- It simplifies application development. Concurrency is a constant source of bugs and performance issues, as developers struggle with writing highly concurrent applications.
- It allows you to price each invocation individually because you don’t have resource contention from handling concurrent requests. This enables the pay-per-use pricing model and is one of the cornerstones of findev.
Still, Lambda also has some disadvantages:
- You can’t make use of idle CPU cycles when a function is waiting on IO. Since most functions are IO-heavy, this results in significant inefficiencies.
- It requires more scaling, which means more cold starts. To handle X concurrent requests, you need X concurrent executions, which equates to X cold starts. This makes it nearly impossible to achieve predictable performance.
Nuclio, on the other hand, can scale up as well as out. A function processor (analogous to a container) can host multiple function workers. Each worker is then able to process one message at a time. This system supports concurrency within the same processor, and then autoscales the number of replicas of the processor based on load.
Another interesting difference between Lambda and Nuclio is that Nuclio lets you specify both the minimum and maximum number of replicas. And as an aside, Nuclio also supports GPUs.
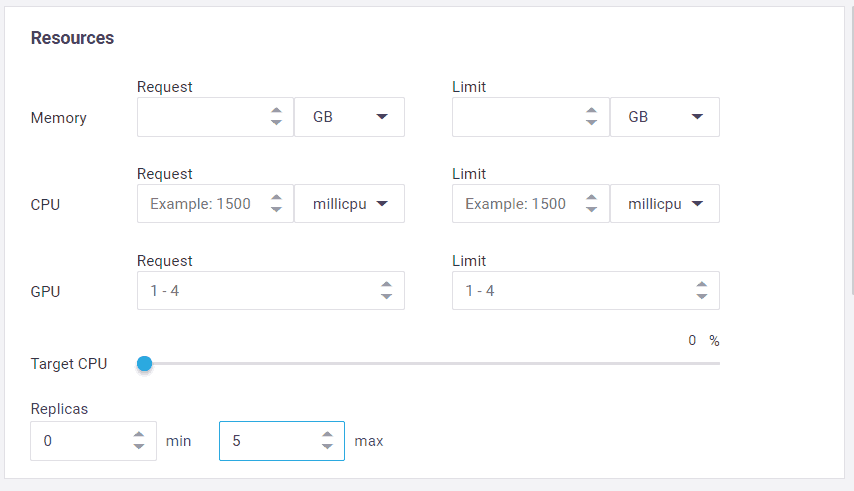
With Lambda, you can configure a reserved concurrency for a function, which (counterintuitively) sets its max concurrent executions. But there is no way to tell the system to always keep a certain number of concurrent executions running at all times. The system always scales to zero when there is no traffic—behavior that is highly undesirable for systems that experience regular spikes in traffic.
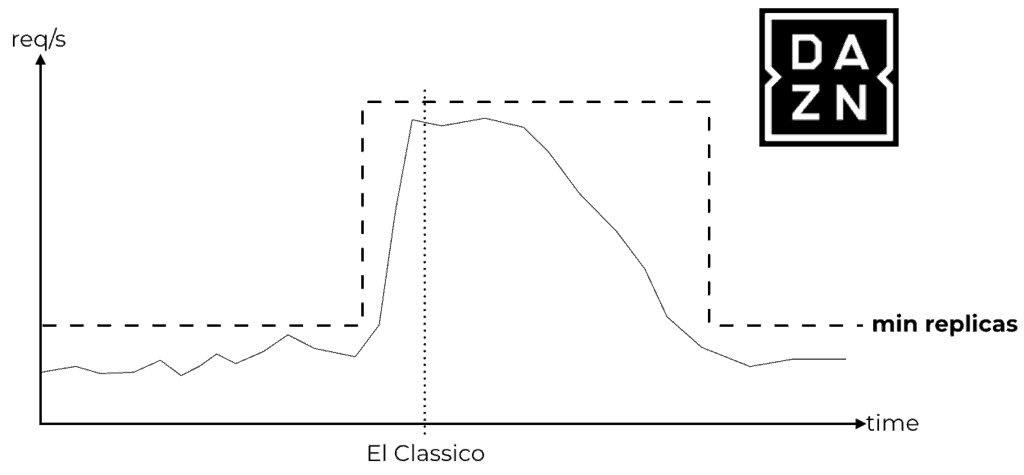
For example, my employer, DAZN, is in the sports streaming business. We see huge spikes in traffic all the time, as millions of users flood in seconds before a sporting event starts.
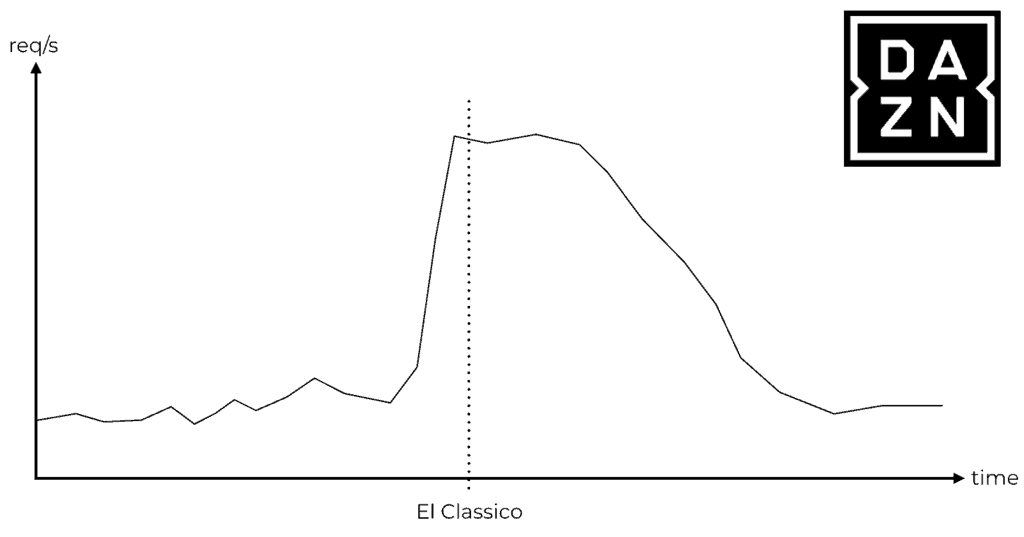
Without the ability to configure the minimum number of concurrent executions, these spikes result in large numbers of cold starts. Also, in these cases, Lambda has to scale out the number of concurrent executions quickly to meet the surge in demand. Here, we also run into the 500/minute limit on how quickly Lambda is able to scale out. As such, we are currently not able to use Lambda on the critical path of our system, which has to shoulder these spikes.
With Nuclio, you can programmatically update the minimum replica count prior to the event so that when the spikes come, you don’t have to worry about hitting scaling limits or enduring the performance hit from cold starts. You can also tell Nuclio to scale to zero immediately via API calls, which saves resources.
Timeout
Another major difference between Lambda and Nuclio is how timeout is handled. With Lambda, an invocation can run for up to 15 minutes. While it’s possible for you to use recursive functions or step functions to extend this limit, both approaches have their own problems. As such, Lambda functions are great for event-driven architectures and performing short, ephemeral tasks.
With Nuclio, there is no max execution time. The containers can keep on running, which in turn allows you to go beyond the constraints of the event-driven model. You can now turn a function into a long-running service, which unlocks some interesting use cases such as long-running ETL jobs and training machine learning (ML) models.
Caching State Between Invocations
Both Lambda and Nuclio functions accept an event and context during an invocation.

With Lambda, the context object is ephemeral and does not persist between invocations. If you want to persist data between invocations (e.g. static configurations, database connections), then you need to declare them as global variables outside of the function handler.
With Nuclio, the execution context itself is persisted between invocations and can be used to cache state. The context object also includes a built-in logger, which supports structured logging with JSON and four log levels: DEBUG, INFO, WARN and ERROR.
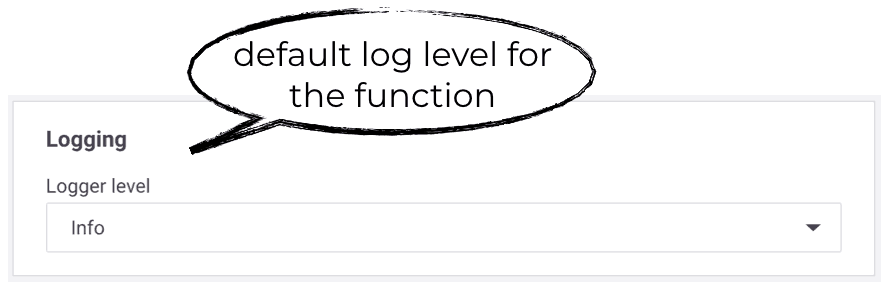
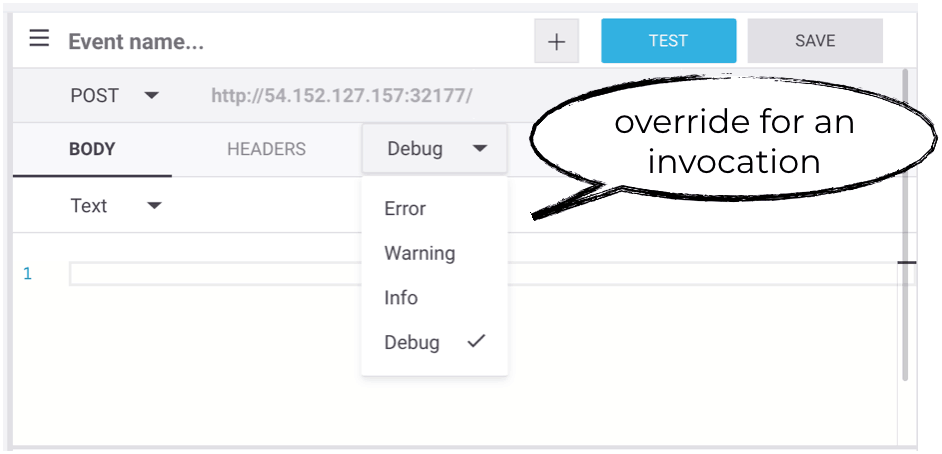
You can configure the default log level for a function and can even override this default log level per invocation—which is very useful for debugging. You also have the ability to export your logs to external services such as Elasticsearch.
In addition, there are hooks for performing context initialization, which is called before the first invocation on the function. This allows you to perform initialization logic before the container is put into active use and removes the dreaded cold start problem that Lambda suffers from.
Data Volumes and Persistent Data Connections
With Lambda, functions only run when they are triggered by events. Furthermore, concurrent executions are garbage-collected when they have been idle for a few minutes. This behavior makes life difficult when you are working with relational database management systems (RDBMS) and other systems that require persistent connections. Indeed, a set of guidelines has been developed to help you avoid the many pitfalls of using Lambda with RDBMS. Furthermore, Lambda doesn’t allow you to use persistent data in standard file system mounts, which forces you to copy to/from object storage before working on large files such as images, logs, ML models, etc.
With Nuclio, however, you can use the context object to maintain persistent connections to databases. Since the context is maintained at the processor level, you get better reuse, as they are shared across invocations. You can also take care of other aspects of data-fetching with data bindings, including batching and caching, which helps improve IO performance of the application. Additionally, you can mount volumes to functions, which is useful for working with ML models or Tensorflow, and you can mount Kubernetes secrets as volumes. Indeed, Nuclio supports all of the volume types that Kubernetes supports.
Runtimes
Both Lambda and Nuclio support popular languages such as Go, Node.js, Python, .Net Core, Java and Ruby. Also, both platforms offer a way for you to customize the execution runtime.
With Lambda, you can create a custom runtime and distribute it through AWS Lambda Layers. This lets you introduce additional language runtimes that are not natively supported by the Lambda platform. Several vendors have published runtimes for PHP, Rust, Erlang and Elixir, to name a few.
With Nuclio, you can run functions on your own Docker image (see Figure 9), which can come from a private image repository. This allows you to tailor the execution environment itself.
You can also support additional language runtimes through a Shell function, which allows you to handle invocation events with any executable binary. See this example for more details.
Triggers
Lambda is supported by a wide range of event sources.
Nuclio ships with 13 triggers, including cron, HTTP, Kafka, Kinesis and RabbitMQ. Since Nuclio is open source, you can also write your own trigger for services that you want to integrate with and leverage other people’s contributions. The HTTP trigger gives you an easy way to integrate Nuclio with other event sources that support HTTP as target, such as SNS. Also, since Nuclio supports the CNCF CloudEvents standard, it can arguably support many more event sources that are CloudEvents-compliant.
Nuclio triggers are all normalized to the same Event object. This removes the need to understand the specific event signature for each event source, which is often confusing when working with Lambda. It also makes it easy to switch a function between different triggers.
Built-In HTTP Trigger
With Lambda, you need to use API Gateway to create an HTTP endpoint for your functions. API Gateway is a feature-rich service, but it’s also complicated and often costs more to run than the Lambda invocations themselves. It also adds another source of latency to your API, which, at the minimum, is around 5ms to 10ms, and it can overhead spike to more than 100ms. This cost and latency overhead make it unsuitable for applications with high throughput or hard real-time requirements.
With Nuclio, every function gets a private HTTP interface by default. To expose the endpoint publicly, you need to specify an HTTP trigger similar to API Gateway. However, unlike API Gateway, this HTTP trigger does not incur extra costs and has minimal latency overhead.
Unlocking New Use Cases with Nuclio
As you can see from our comparison, Nuclio differs from Lambda in a number of important areas, such as its concurrency model and that it has no max execution time. This opens the door to a whole range of use cases. Let’s take a moment to look at a few.
High-Throughput Data Processing Pipelines or APIs
For a high-throughput API, the cost of both API Gateway and Lambda is drastically higher than an equivalent application running in containers. This cost discrepancy has lead many to rewrite their applications.
Nuclio’s concurrency model makes more efficient use of available resources, which significantly reduces operational cost when running at scale. Functions have built-in HTTP interfaces so you also don’t need to pay for an expensive API Gateway service.
The ability to mount a volume to your function also lets you read and write data to/from a mounted volume at high speed and enables building stateful applications. Again, you can’t do this with Lambda today, as it doesn’t allow you to attach Amazon Elastic File System (Amazon EFS) volumes to functions.
These features make it economically feasible to run high-throughput and high-performance APIs on Nuclio functions. The same can also be said about high-throughput data processing pipelines that have to process multiple terabytes of data per hour.
APIs with Predictable Spikes in Traffic
Nuclio gives you the ability to configure a minimum number of replicas. This allows systems that experience predictable spikes in traffic to reserve sufficient resources ahead of time and avoid degrading the user experience when the spikes happen. Examples include food ordering services such as Just Eat or Deliveroo or sports streaming services such as DAZN.
At the same time, Nuclio still lets you scale to zero by setting the minimum number of replicas to zero. It gives you the control to optimize for resource usage or latency, depending on the situation.
Real-Time Applications
Nuclio does not suffer from cold starts and is able to deliver consistent and sub-millisecond response times on invocations. This makes it a suitable solution for applications with a hard, real-time requirement such as multiplayer games and real-time bots.
Serving Machine Learning Models in Real Time
To serve ML models in real time, you need to have both strong and predictable API latency and the ability to load and work with ML models that often are large in size (GBs).
Nuclio lets you attach Kubernetes volumes to your functions, and there are no size limits on these volumes. Combined with the performance characteristics, it’s possible to implement these demanding workloads with Nuclio functions.
Nuclio also has native integration with Jupyter, and lets you automatically deploy Jupyter notebooks and ML models as Nuclio functions.
Long-Running Jobs and Services
Nuclio does not impose a max execution timeout on function invocations. This allows you to turn your functions into long-running services and perform long-running ETL jobs.
Nuclio’s init_context() hook lets you create long-running services, such as an application that constantly reads off a Twitter feed (e.g. loads the TwythonStreamer with the context, which is polling an external service, versus becoming triggered by an event).
Conclusion
As we discussed, Nuclio is one of the few open source solutions that are also business-viable. It has key architectural advantages for higher performance or data-driven applications, including:
- Nuclio is cloud-agnostic. It can be used in multi-cloud/hybrid-cloud scenarios. You can also run Nuclio on a laptop using plain Docker, which makes debugging easier.
- Nuclio’s concurrency model and the ability to mount file volumes lets you build high-performance APIs and high-throughput data processing pipelines.
- Nuclio gives you greater control over the concurrency of your application, which makes it viable even for applications with very spiky traffic.
- Nuclio’s execution contexts are persisted between invocations, and it doesn’t impose a max execution time on invocations. This allows you to create long-running stateful applications such as ETL jobs.
- Nuclio lets you attach Kubernetes volumes to your functions and has no limitations on the size of the volume. This makes it possible for you to work with large ML models that often are GBs in size. Nuclio also has native integration with Jupyter and can automatically deploy your Jupyter notebooks and models as functions.
- Nuclio provides a good out-of-the-box developer experience. It has a built-in logger with structured logging support, and you can easily export your logs to an external log aggregation service.
If you are looking for a serverless platform that is not tied to a specific cloud provider, Nuclio is worth a look.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.