
Yan Cui
I help clients go faster for less using serverless technologies.

Hi, welcome to another weekly update!
Welcome Binaris as our sponsor for April!
It is my pleasure to welcome Binaris back as the sponsor for this month. Here’s a message from Binaris.
In Binaris we deeply believe in the power of serverless and the power of functions. We envision a future where applications are built entirely out of serverless functions. To enable this, we started out by focusing on invocation latency. We built a cloud serverless platform that fires up functions in single-digit milliseconds. Binaris is almost 40x faster than AWS Lambda (and similar serverless platforms) at the 99th percentile, and also faster than most self-managed container or instance based services:
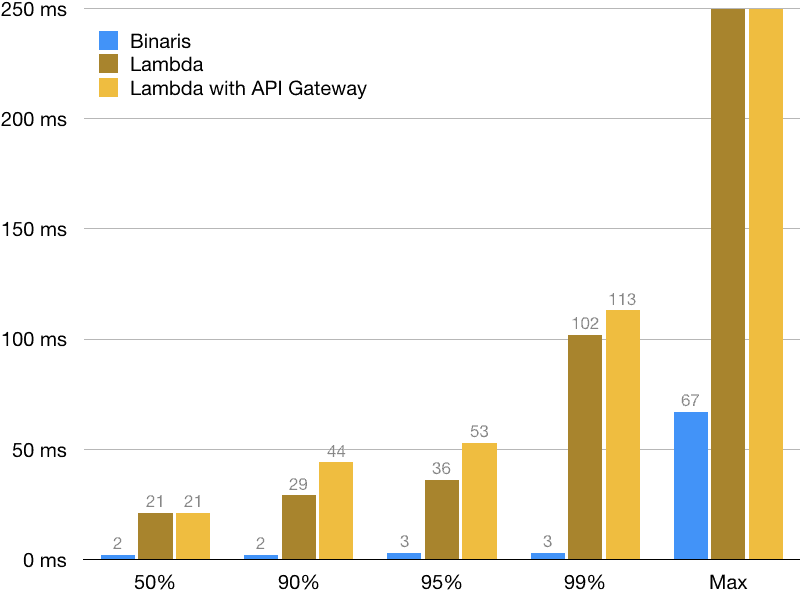
Binaris is designed from the ground up with functions in mind. We have implemented a function optimized container provisioning system, built our own instance provisioning layer and manage networking and load balancing using latency optimized algorithms. As a result, we have no cold starts and can provide predictable low latency, even for extremely bursty workloads. Binaris is a serverless platform designed to support responsive and interactive use cases and provide developers with the freedom to build entire applications out of serverless functions. You can read more and sign up for free at www.binaris.com.
New posts
Just how expensive is the full AWS SDK. In this post, I invested the effect requiring the full AWS SDK has on Lambda cold start time. I found that if you require the specific AWS SDK client (e.g. DynamoDB) rather than the full AWS SDK then you can shave some 200ms from your cold start. If you use webpack to bundle your function then you can make further savings.
Comparing Nuclio and AWS Lambda. In this post, I compared Nuclio’s managed functions with AWS Lambda. I looked at how the two differs in terms of concurrency model, statefulness, runtime supports and more. Nuclio is a really powerful platform and offers some really different trade-offs from AWS Lambda. It supports a number of use cases that are ill-suited to Lambda, such as high through data pipelines or APIs, or real-time applications.
How should you organize your functions in production? I wrote a guest post for Epsagon, where I discussed how you should organize your functions. The bottom line is you should prefer to keep functions single-purposed, but there are special cases where this would be hard to apply. Such as when you implement a GraphQL router or processing Kinesis events.
New Serverless applications
I worked in collaboration with Lumigo and published three Serverless applications to the Serverless Application Repository.
lambda-janitor
Deployment packages for old versions of functions tend to linger around. They cost you money and increases your chance of reaching the 75GB soft limit on deployment packages (per region). This handy serverless application creates a cron job to delete old versions of your functions. Once installed, it’ll act on all functions in your region so you only have to install and configure it once. To prevent accidental deletion, it also has some safeguards in place:
- Never delete the $LATEST version.
- Never delete a version that is still referenced by an alias.
- Keeping the most recent N versions (where N is configurable).
You can deploy the application to your account here and read our launch blog post here.
auto-subscribe-log-group-to-arn
Once installed, this serverless application would subscribe all new and existing CloudWatch log groups to Lambda, Kinesis, or Firehose by ARN. It makes it easy for you to implement log aggregation, as I describe in previous posts here and here.
You can deploy the application to your account here and read our launch blog post here.
auto-set-log-group-retention
Once installed, this serverless application would update all new and existing CloudWatch log groups so it’s retention policy is changed to your configured number of days. By default, CloudWatch logs never expire any logs. This has a cost implication as you pay $0.03 per GB per month. If you’re shipping your logs elsewhere (perhaps using the above serverless application) then it really doesn’t make sense for you to keep paying more and more for those same logs in CloudWatch too.
You can deploy the application to your account here and read our launch blog post here.
Open source
serverless-step-functions
We published a number of updates to this pluging, including:
- Gives you the ability to configure a custom IAM role for scheduled events, see here.
- Support custom tags, more details here.
- Support global tags (merged with custom tags), more details here.
LaunchDarkly-relay-fargate
I spent some time with one of my clients, Solve, this week. Among other things, we set up the LaunchDarkly relay in Fargate. It makes it easy for us to use Lambda with LaunchDarkly without worrying about the server connection limits when our functions scale up. With this setup, our functions are able to read feature toggles from DynamoDB instead, without having to talk to LaunchDarkly directly.
We decided to open source it. You can check it out here, the example folder also includes a Serverless project that shows you how to use the DynamoDB cache from Lambda.
As a side note, Solve is doing some really interesting things with serverless technologies. They’re building a new mobile game that will likely to millions of users once they’re launched, and working with some top-notch tools such as Honeycomb and LaunchDarkly. They’re looking for a senior backend engineer to join their small team in London, if you’d like the chance to work on an exciting project using serverless technologies, then check out their job spec.
Conference talks
It’s been a busy couple of weeks on the conference fronts too. Since the last update, I have spoken at CloudConf, OpenInfraDays, AWS Community Summit and CodeMotion Amsterdam! Here are the slides from my talks at these events.
Special shoutouts
One of my clients, SimplyBusiness, did some excellent analysis on the effect VPC has on Lambda cold starts recently – bottom line is don’t use VPC unless you have to access VPC-protected resources (RDS, Elasticache, etc.). It’s also worth reading part 1 of their analysis, which looked at how memory size affects the cold start time of Ruby functions.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.