
Yan Cui
I help clients go faster for less using serverless technologies.


With AWS Lambda and the Serverless framework, deploying your code has become so simple and frictionless.
As you move more and more of your architecture to run on Lambda, you might find that, in addition to getting things done faster you are also deploying your code more frequently.
That’s awesome!
But, as you rejoice in this new found superpower to make your users and stakeholders happy, you need to keep an eye out for that regional limit of 75GB for all the uploaded deployment packages.

At Yubl, me and a small team of 6 server engineers managed to rack up nearly 20GB of deployment packages in 3 months.
We wrote all of our Lambda functions in Nodejs, and deployment packages were typically less than 2MB. But the frequency of deployments made sure that the overall size of deployment packages went up steadily.
Now that I’m writing most of my Lambda functions in Scala (it’s the weapon of choice for the Space Ape Games server team), I’m dealing with deployment packages that are significantly bigger!
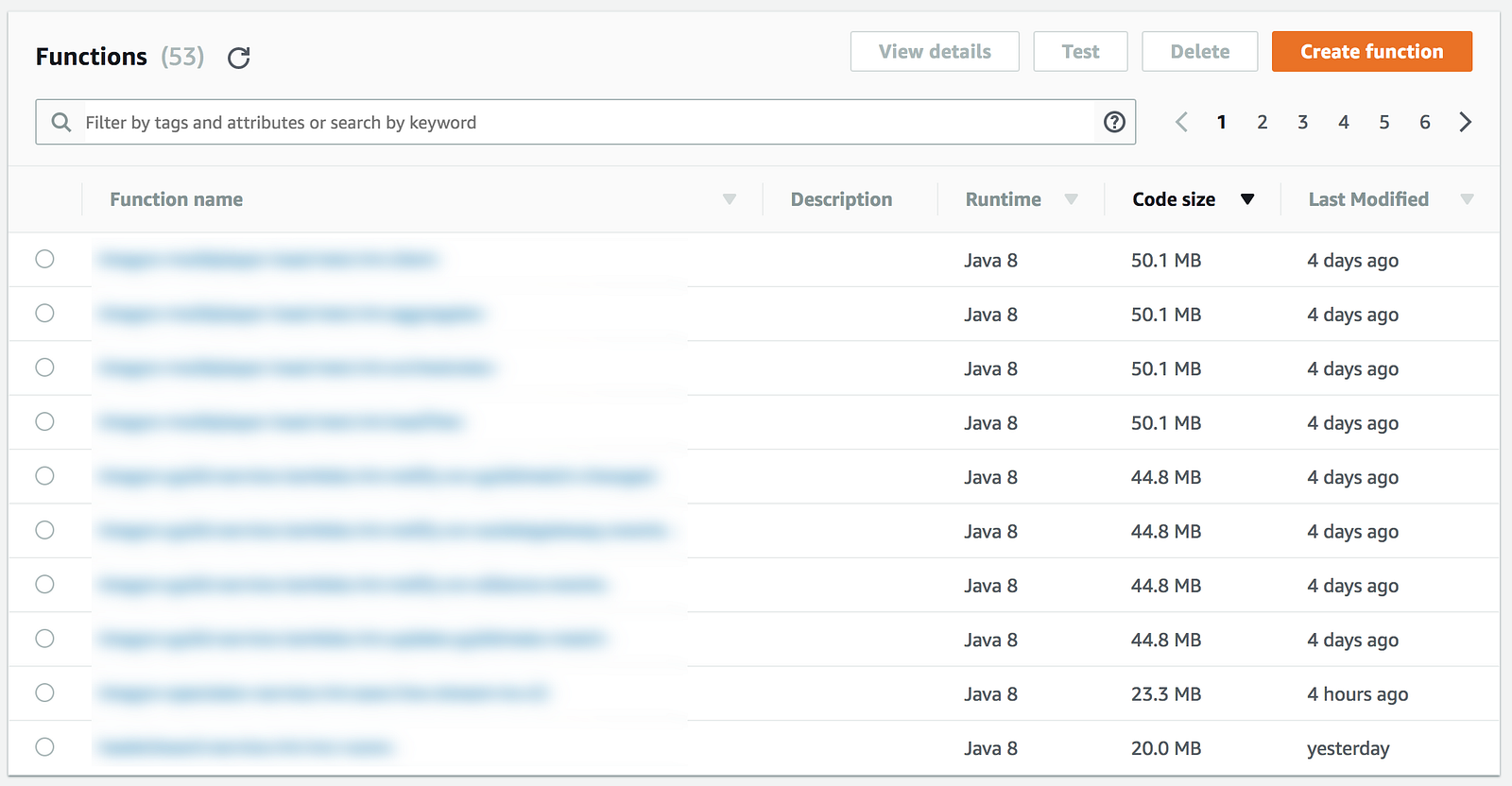
Serverless framework: disable versionFunctions
By default, the Serverless framework would create a new version of your function every time you deploy.
In Serverless 0.X, this is (kinda) needed because it used function alias. For example, I can have multiple deployment stages for the same function?—?dev, staging and production. But in the Lambda console there is only one function, and each stage is simply an alias pointing to a different version of the same function.
Unfortunately this behaviour also made it difficult to manage the IAM permissions because multiple versions of the same function share the same IAM role. Since you can’t version the IAM role with the function, this makes it hard for you to add or remove permissions without breaking older versions.
Fortunately, the developers listened to the community and since the 1.0 release each stage is deployed as a separate function.
Essentially, this allows you to “version” IAM roles with deployment stages since each stage gets a separate IAM role. So there’s technically no need for you to create a new version for every deployment anymore. But, that is still the default behaviour, unless you explicitly disable it in your serverless.ymlby setting versionFunctions to false.
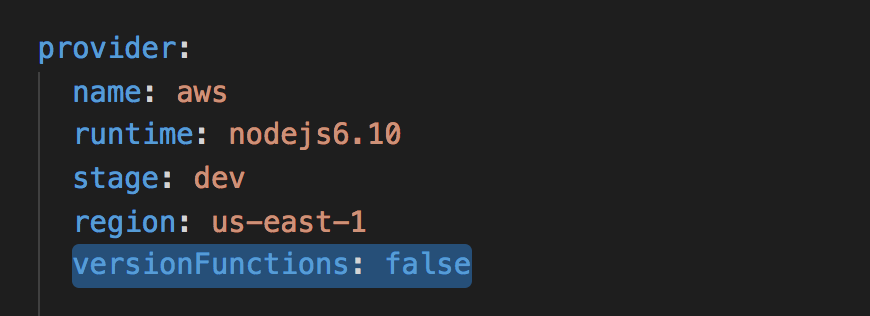
You might argue that having old versions of the function in production makes it quicker to rollback.
In that case, enable it for the production stage only. To do that, here’s a handy trick to allow a default configuration in your serverless.yml to be overridable by deployment stage.
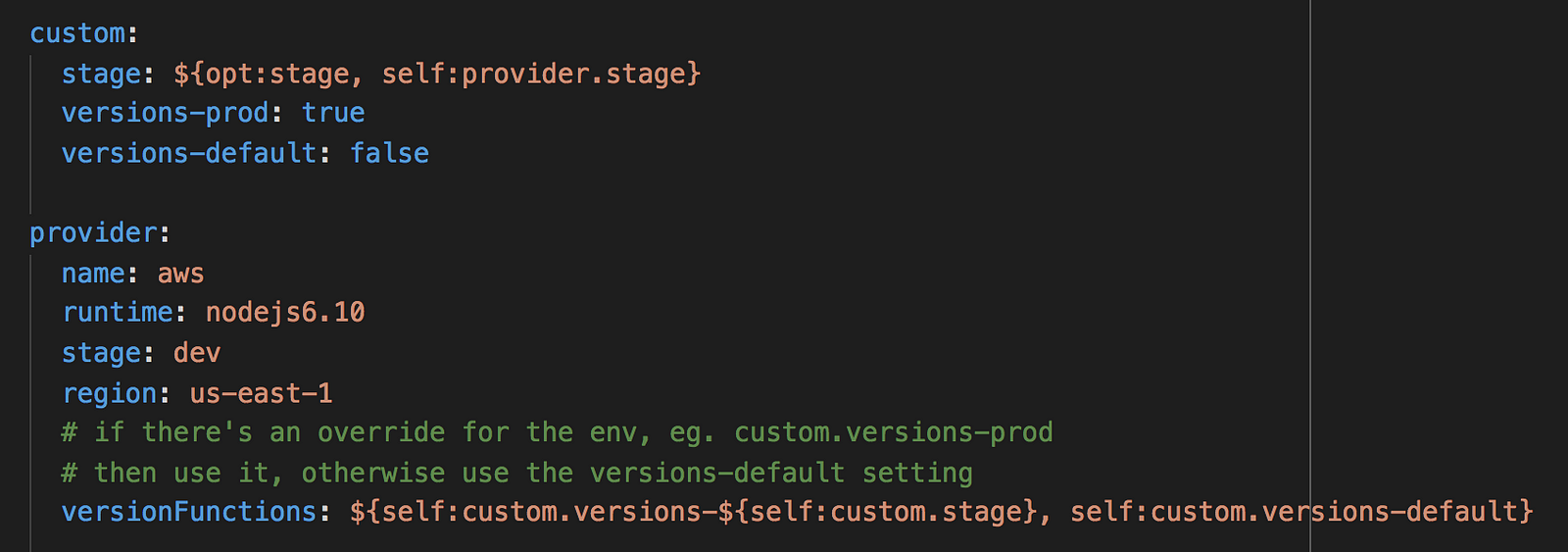
In my personal experience though, unless you have taken great care and used aliases to tag the production releases it’s actually quite hard to know which version correlates to what. Assuming that you have reproducible builds, I would have much more confidence if we rollback by deploying from a hotfixor support branch of our code.
Clean up old versions with janitor-lambda
If disabling versionFunctions in the serverless.yml for all of your projects is hard to enforce, another approach would be to retroactively delete old versions of functions that are no longer referenced by an alias.
To do that, you can create a cron job (ie. scheduled CloudWatch event + Lambda) that will scan through your functions and look for versions that are not referenced and delete them.
I took some inspiration from Netflix’s Janitor Monkey and created a Janitor Lambda function that you can deploy to your AWS environment to clean unused versions of your functions.
After we employed this Janitor Lambda function, our total deployment package went from 20GB to ~1GB (we had a lot of functions…).
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Is there a way we can get the total size of deployment packages used by my account on one region?
Nevermind. I saw it now.