
Yan Cui
I help clients go faster for less using serverless technologies.

AWS Lambda announced native support for environment variables at the end of 2016. But even before that, the Serverless framework had supported environment variables and I was using them happily as me and my team at the time migrated our monolithic Node.js backend to serverless.
However, as our architecture expanded we found several drawbacks with managing configurations with environment variables.
The biggest problem for us was the inability to share configurations across projects since environment variables are function specific at runtime.
The Serverless framework has the notion of services, which is just a way of grouping related functions together. You can specify service-wide environment variables as well as function-specific ones.
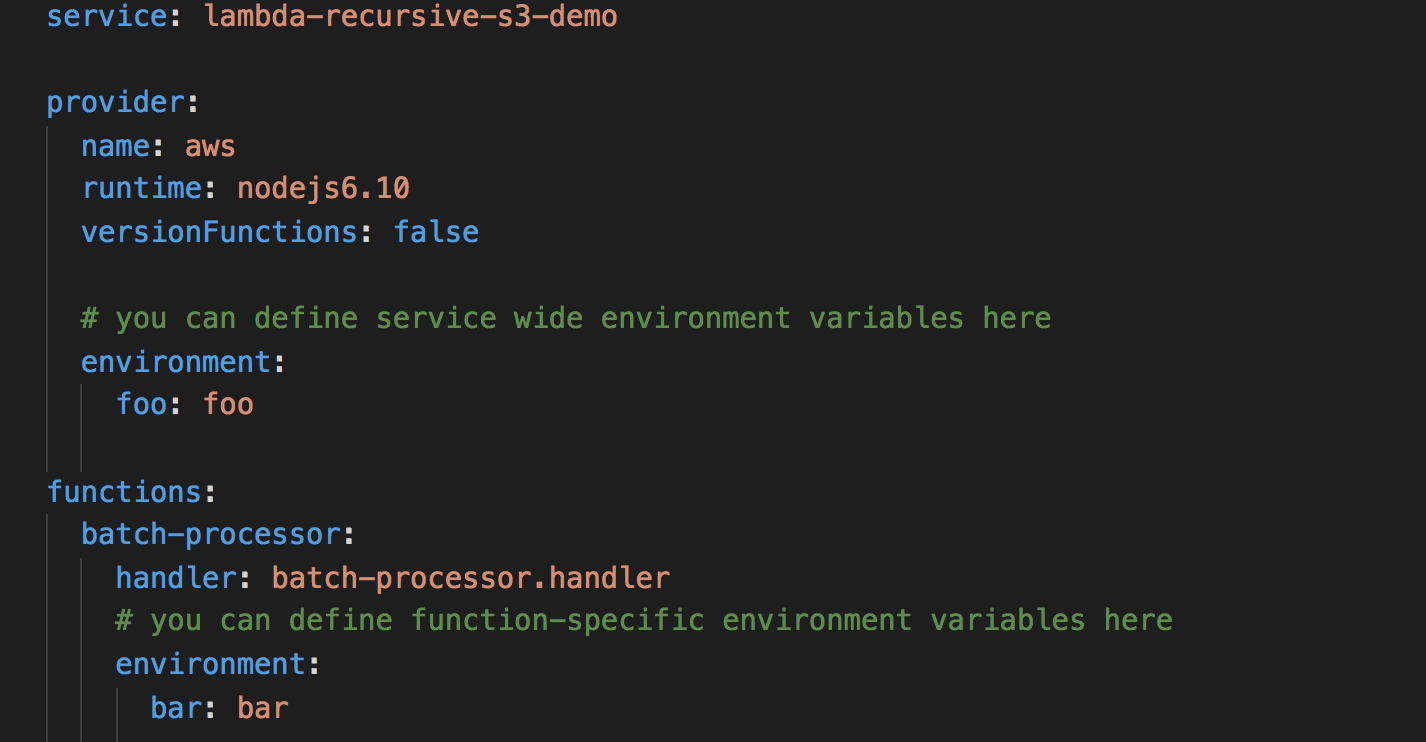
However, we often found that configurations need to be shared across multiple services. When these configurations change we had to update and redeploy all functions that depend on them – which in itself was becoming a challenge to track these dependencies across many Github repos that are maintained by different members of the team.
For example, as we were migrating from a monolithic system piece by piece whilst delivering new features, we weren’t able to move away from the monolithic MongoDB database in one go. It meant that lots of functions shared MongoDB connection strings. When one of these connection strings changed – and it did several times – pain and suffering followed.
Another configurable value we often share are the root URL of intermediate services. Being a social network, many of our user-initiated operations depend on relationship data, so many of our microservices depend on the Relationship API. Instead of hardcoding the URL to the Relationship API in every service (one of the deadly microservice anti-patterns), it should be stored in a central configuration service.
Hard to implement fine-grained access control
When you need to configure sensitive data such as credentials, API keys or DB connection strings, the rule of thumb are:
- data should be encrypted at rest (includes not checking them into source control in plain text)
- data should be encrypted in-transit
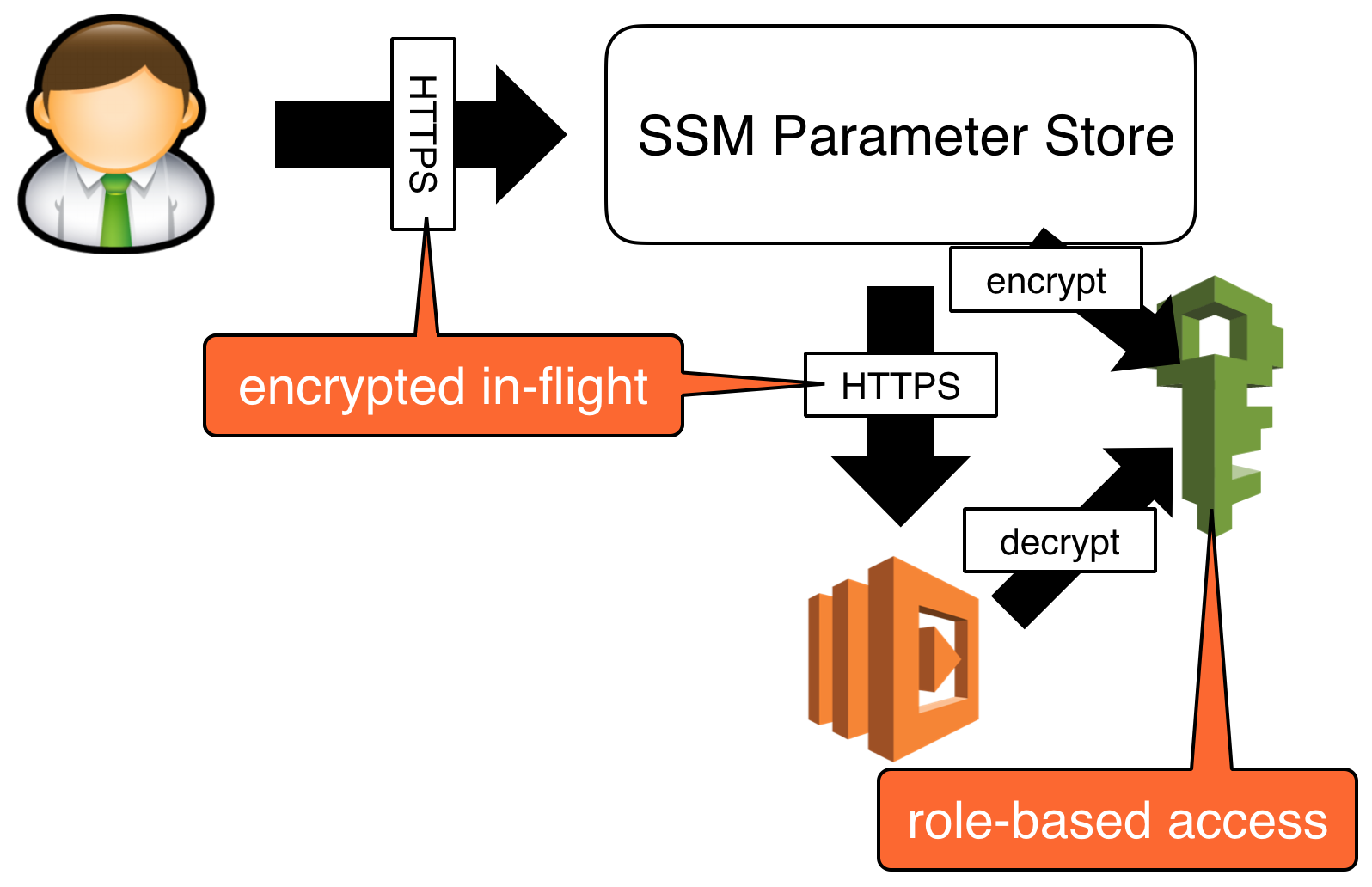
- apply the principle of least privilege to function’s and personnel’s access to data
If you’re operating in a heavily regulated environment then point 3. might be more than a good practice but a regulatory requirement. I know of many fintech companies and financial juggernauts where access to production credentials are tightly controlled and available only to a handful of people in the company.
Whilst efforts such as the serverless-secrets-plugin delivers on point 1. it couples one’s ability to deploy Lambda functions with one’s access to sensitive data – ie. he who deploys the function must have access to the sensitive data too. This might be OK for many startups, as everyone has access to everything, ideally your process for managing access to data can evolve with the company’s needs as it grows up.
SSM Parameter Store
My team outgrew environment variables, and I started looking at other popular solutions in this space – etcd, consul, etc. But I really didn’t fancy these solutions because:
- they’re costly to run: you need to run several EC2 instances in multi-AZ setting for HA
- you have to manage these servers
- they each have a learning curve with regards to both configuring the service as well as the CLI tools
- we needed a fraction of the features they offer
This was 5 months before Amazon announced SSM Parameter Store at re:invent 2016, so at the time we built our own Configuration API with API Gateway and Lambda.
Nowadays, you should just use the SSM Parameter Store because:
- it’s a fully managed service
- sharing configurations is easy, as it’s a centralised service
- it integrates with KMS out-of-the-box
- it offers fine-grained control via IAM
- it records a history of changes
- you can use it via the console, AWS CLI as well as via its HTTPS API
In short, it ticks all our boxes.
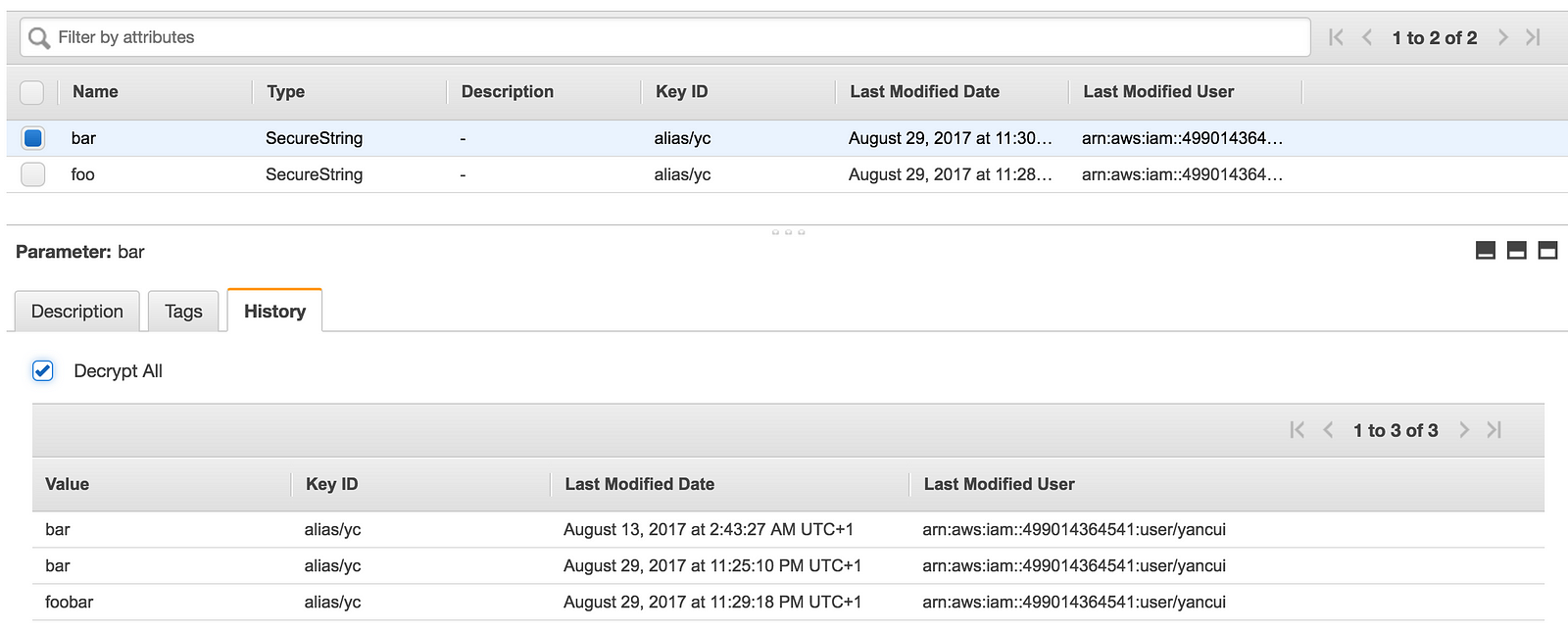
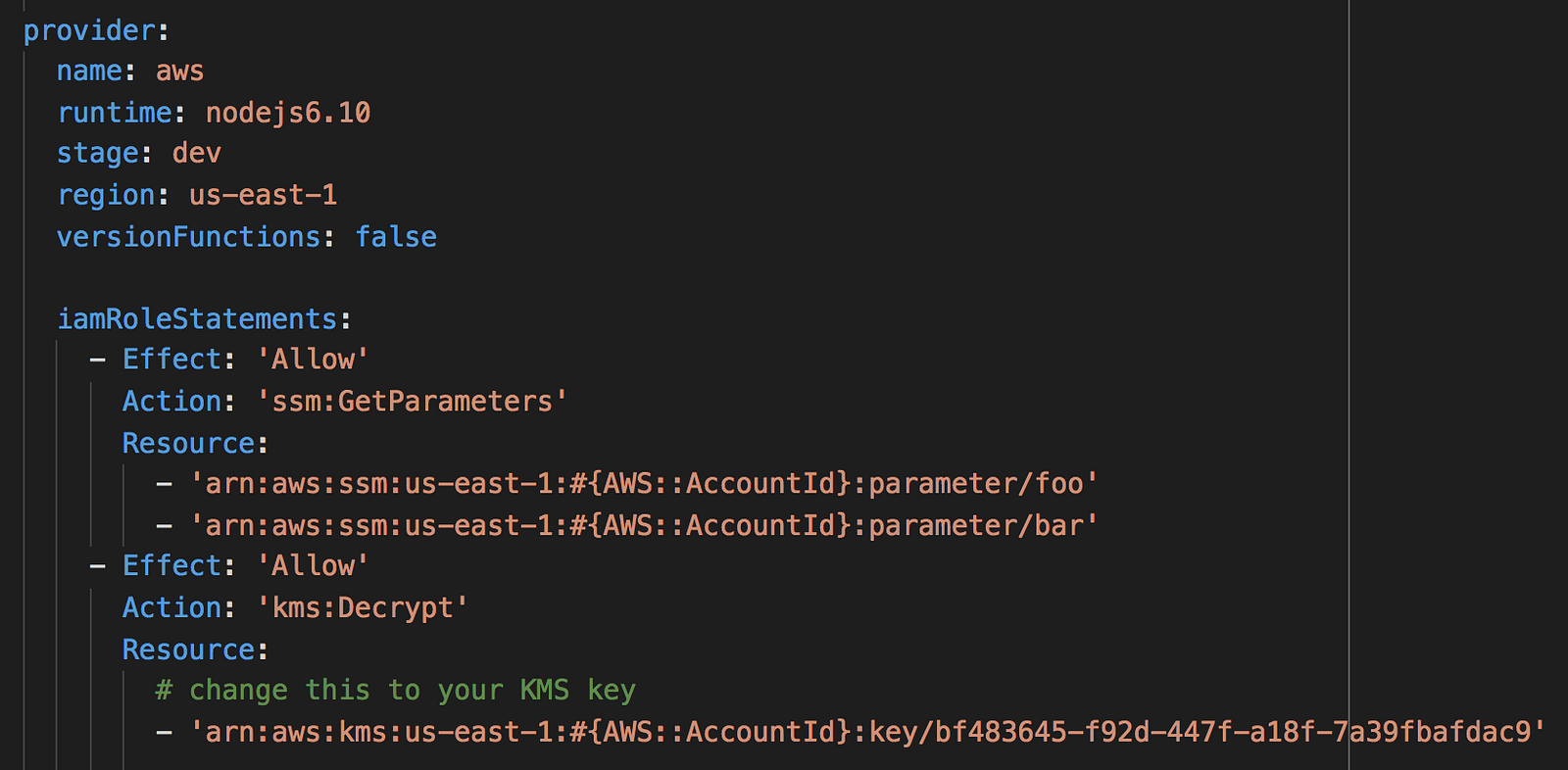
There are couple of service limits to be aware of:
- max 10,000 parameters per account
- max length of parameter value is 4096 characters
- max 100 past values for a parameter
Client library
Having a centralised place to store parameters is just one side of the coin. You should still invest effort into making a robust client library that is easy to use, and supports:
- caching & cache expiration
- hot-swapping configurations when source config value has changed
Here is one such client library that I put together for a demo:
'use strict';
const co = require('co');
const EventEmitter = require('events');
const Promise = require('bluebird');
const AWS = require('aws-sdk');
const ssm = Promise.promisifyAll(new AWS.SSM());
const DEFAULT_EXPIRY = 3 * 60 * 1000; // default expiry is 3 mins
function loadConfigs (keys, expiryMs) {
expiryMs = expiryMs || DEFAULT_EXPIRY; // defaults to 3 mins
if (!keys || !Array.isArray(keys) || keys.length === 0) {
throw new Error('you need to provide a non-empty array of config keys');
}
if (expiryMs <= 0) {
throw new Error('you need to specify an expiry (ms) greater than 0, or leave it undefined');
}
// the below uses the captured closure to return an object with a gettable
// property per config key that on invoke:
// * fetch the config values and cache them the first time
// * thereafter, use cached values until they expire
// * otherwise, try fetching from SSM parameter store again and cache them
let cache = {
expiration : new Date(0),
items : {}
};
let eventEmitter = new EventEmitter();
let validate = (keys, params) => {
let missing = keys.filter(k => params[k] === undefined);
if (missing.length > 0) {
throw new Error(`missing keys: ${missing}`);
}
};
let reload = co.wrap(function* () {
console.log(`loading cache keys: ${keys}`);
let req = {
Names: keys,
WithDecryption: true
};
let resp = yield ssm.getParametersAsync(req);
let params = {};
for (let p of resp.Parameters) {
params[p.Name] = p.Value;
}
validate(keys, params);
console.log(`successfully loaded cache keys: ${keys}`);
let now = new Date();
cache.expiration = new Date(now.getTime() + expiryMs);
cache.items = params;
eventEmitter.emit('refresh');
});
let getValue = co.wrap(function* (key) {
let now = new Date();
if (now <= cache.expiration) {
return cache.items[key];
}
try {
yield reload();
return cache.items[key];
} catch (err) {
if (cache.items && cache.items.length > 0) {
// swallow exception if cache is stale, as we'll just try again next time
console.log('[WARN] swallowing error from SSM Parameter Store:\n', err);
eventEmitter.emit('refreshError', err);
return cache.items[key];
}
console.log(`[ERROR] couldn't fetch the initial configs : ${keys}`);
console.error(err);
throw err;
}
});
let config = {
onRefresh : listener => eventEmitter.addListener('refresh', listener),
onRefreshError : listener => eventEmitter.addListener('refreshError', listener)
};
for (let key of keys) {
Object.defineProperty(config, key, {
get: function() { return getValue(key); },
enumerable: true,
configurable: false
});
}
return config;
}
module.exports = {
loadConfigs
};
To use it, you can create config objects with the loadConfigs function. These objects will expose properties that return the config values as Promise (hence the yield, which is the magic power we get with co).
You can have different config values with different cache expiration too.
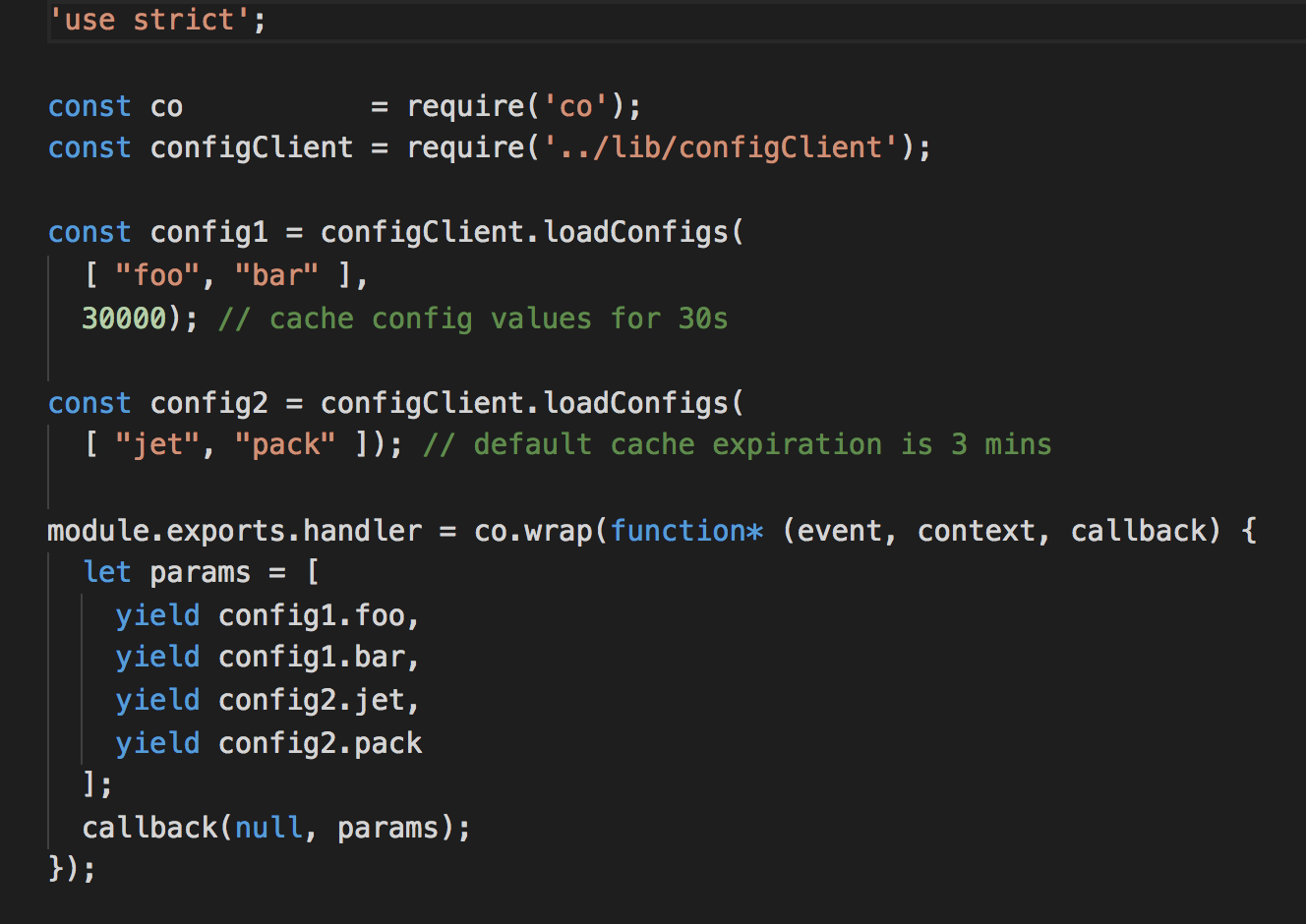
If you want to play around with using SSM Parameter Store from Lambda (or to see this cache client in action), then check out this repo and deploy it to your AWS environment. I haven’t included any HTTP events, so you’d have to invoke the functions from the console.
Update 15/09/2017: the Serverless framework release 1.22.0 which introduced support for SSM parameters out of the box.
With this latest version of the Serverless framework, you can specify the value of environment variables to come from SSM parameter store directly.
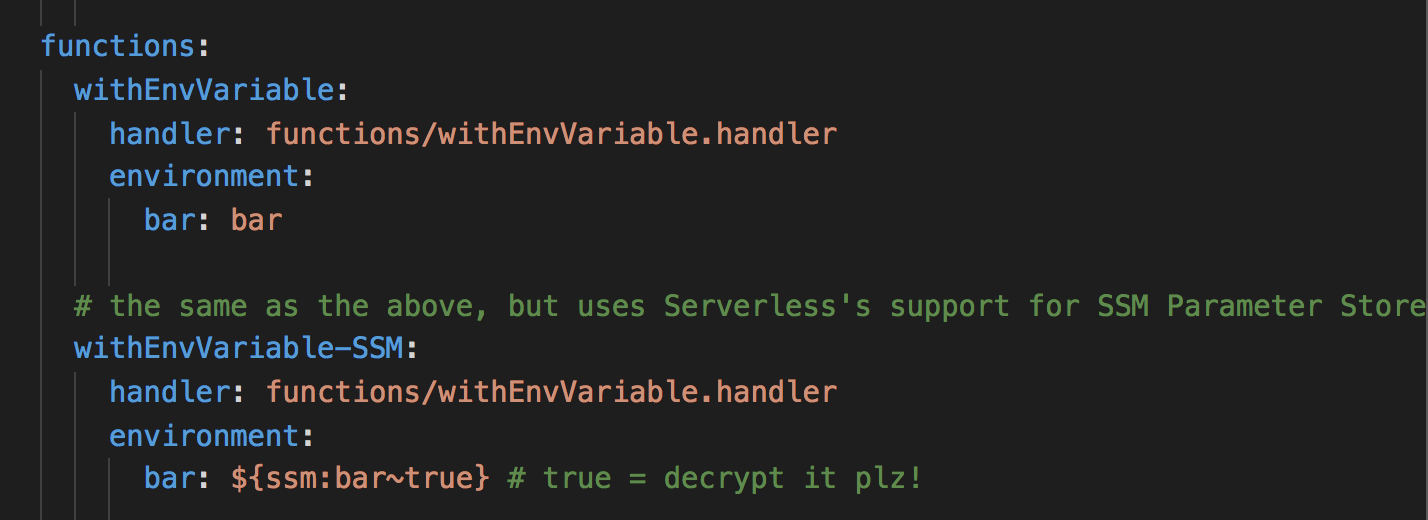
Compared to many of the existing approaches, it has some benefits:
- avoid checking in sensitive data in plain text in source control
- avoid duplicating the same config values in multiple services
However, it still falls short on many fronts (based on my own requirements):
- since it’s fetching the SSM parameter values at deployment time, it still couples your ability to deploy your function with access to sensitive configuration data
- the configuration values are stored in plain text as Lambda environment variables, which means you don’t need the KMS permissions to access them, you can see it the Lambda console in plain sight
- further to the above, if the function is compromised by an attacker (who would then have access to
process.env) then they’ll be able to easily find the decrypted values during the initial probe (go to 13:05 mark on this video where I gave a demo of how easily this can be done) - because the values are baked at deployment time, it doesn’t allow you to easily propagate config value changes. To make a config value change, you will need to a) identify all dependent functions; and b) re-deploying all these functions
Of course, your requirement might be very different from mine, and I certainly think it’s an improvement over many of the approaches I have seen. But, personally I still think you should:
- fetch SSM parameter values at runtime
- cache these values, and hot-swap when source values change
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Thank you!