

Yan Cui
I help clients go faster for less using serverless technologies.

This is another good talk on micro-services at CraftConf, where Tammer Saleh talks about common antipatterns with micro-services and some of the ways you can avoid them.
Personally I think it’s great that both Tammer and Adrian have spent a lot of time talking about challenges with micro-services at CraftConf. There has been so much hype around micro-services that many people forget that like most things in technology, micro-service is an architectural style that comes with its own set of trade-offs and not a free lunch.
Why Micro-Services?
Monolithic applications are hard to scale, and it’s impossible to scale the engineering team around it. Because everybody has to work on the same codebase and the whole application is deployed and updated as one big unit.
Then came SOA, which had the right intentions but was too focused on horizontal middleware instead of functional verticals. It was also beset by greedy consultants and middleware vendors.
And finally we have arrived at the age of micro-services, which embraces openness, modularity and maintainability. And most importantly, it’s about the teams and gives you a way to scale your engineering organization.
Within a micro-service architecture you can have many small, focused teams (e.g. Amazon’s 2 pizza rule) that have autonomy over technologies, languages, deployment processes and be able to practice devops and own their services in production.
Anti-Patterns
But, there are plenty of ways for things to go wrong. And here are some common mistakes.
Overzealous Services
The most common mistake is to go straight into micro-services (following the hype perhaps?) rather than starting with the simplest thing possible.
Remember, boring is good.
Microservices are complex and it adds a constant tax to your development teams. It allows you to scale your development team very large, but it slows each of the teams down, and increases communication overhead.
Instead, you should start by doing the simplest thing possible, identify the hotspots as they become apparent and then extract them into micro-services (this is also how Google does it).
Schemas Everywhere
Another common mistake is to have a shared database between different services. This creates tight coupling between the services and means you can’t deploy the micro-services independently if it breaks the shared schema. Any schema updates will force you to update other micro-services too.
Instead, every service should have its own database, and when you want data from another service you go through its API rather than reaching into its database and help yourself.
But then, services still have to talk to one another and there’s still a schema in play here at the communication layer. If you introduce a new version of your API with breaking changes then you’ll break all the services that depend on you.
A solution here would be to use semantic versioning and deploy breaking changes side by side. You can then give your consumers a deprecation period, and get rid of the old version when no one is using it.
BUT, as anyone who’s ever had to deprecate anything would tell you, doesn’t matter how much notice you give someone they’ll always wait till the last possible moment.
Facebook has (or had, not sure if this is still the case) an ingenious solution to this problem. As the deadline for deprecation nears they’ll occasionally route some percentage of your calls to the new API. This raises sufficient no. of errors in your application to get your attention without severely compromising your business. It could start off with 10% of calls in a 5 minute window once every other day, then once a day, then a 10 minute window, and so on.
The idea is simple, to give you the push you need and a glimpse of what would happen if you miss the deadline!
Spiky Load between Services
You often get spiky traffic between services, and a common solution is to amortise the load by using queues between the services.
Hardcoded IPs and Ports
A common sin that most of us have committed. It gets us going quickly but then makes our lives hell when we need to configure/manage multiple environments and deployments.
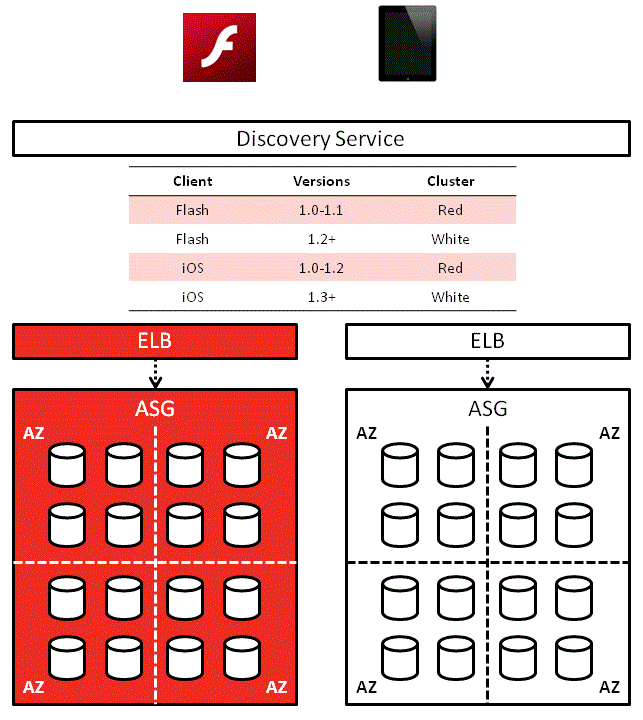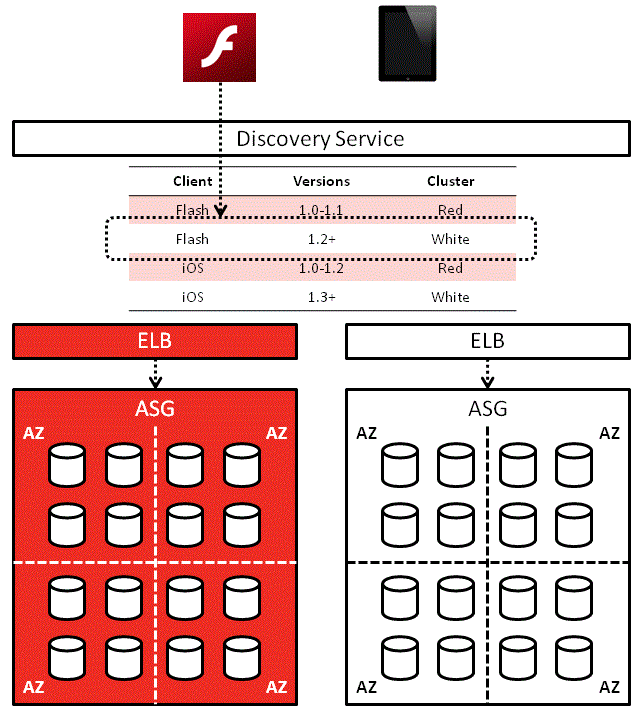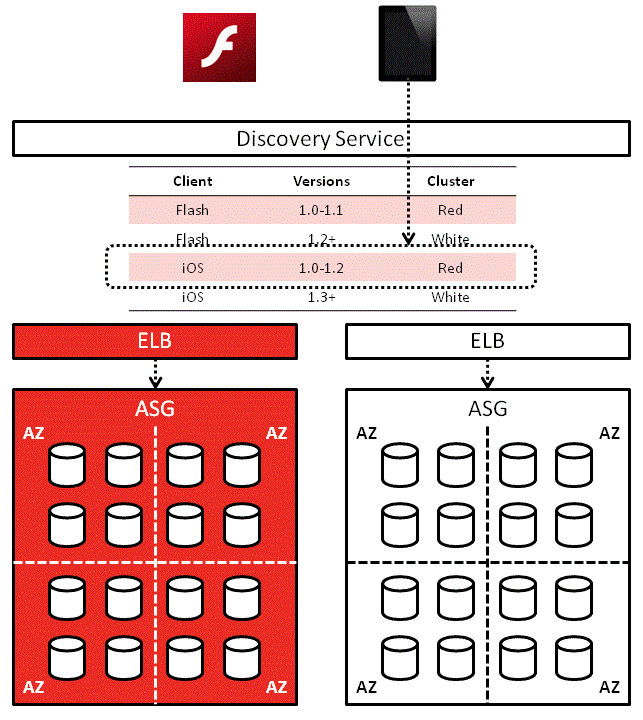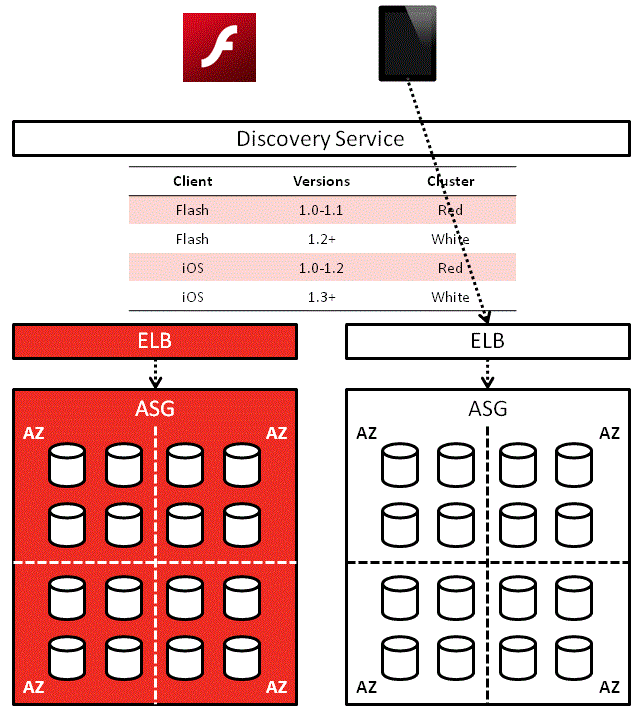
One solution would be to use a discovery service such as consul or etcd, and there’s also Netflix’s eureka.
In this solution, each service would first contact the discovery service to find out where other services are:

Service A’ll use that address until Service B can no longer be reached at the address or some timeout has occurred, in which case it’ll ask the discovery service for Service B’s location again.
On a side note, the Red-White Push mechanism I worked on a while back works along similar lines. It solves a different problem (routes client apps to corresponding service cluster based on version) but the idea behind it is the same.
Another solution is to use a centralised router.

In this solution, services access each other via a known URL via the router and you can easily change the routes programmatically.
Both solutions require registration and deregistration, and both require high availability and scalability.
A discovery service is simpler to build and scale, since it doesn’t need to route all traffic and so doesn’t need to scale as much. But an application needs to know about the discovery service in order to talk to it, so it requires more work to integrate with.
A router on the other hand, needs to handle all traffic in your system and it incurs an additional round-trip for every call. But it works transparently and is therefore easier to integrate and work with, and it can also be exposed externally too.
Dogpiles
If one of your services is under load or malfunctioning, and all your other services keep retrying their failed calls, then the problem would be compounded and magnified by the additional load from these retries.
Eventually, the faltering service will surfer a total outage, and potentially set off a cascading failure throughout your system.
The solution here is to have exponential backoff and implement the circuit breaker pattern.
Both patterns come high up the list of good patterns in Michael Nygard’s Release It! and adopted by many libraries such as Netflix’s Hystrix and Polly for .Net.

You can even use the service discovery layer to help propagate the message to all your services that a circuit has been tripped (i.e. a service is struggling).
This introduces an element of eventual consistency (local view of the service’s health vs what the discovery service is saying). Personally, I find it sufficient to let each service manage its own circuit breaker states so longer you have sensible settings for:
- timeout
- no. of timed out requests required to trip the circuit
- amount of time the circuit is broken for before allowing one attempt through
Using a discovery service does have the advantage of allowing you to manually trip the circuit, e.g. in anticipation to a release where you need some down time.
But, hopefully you won’t need that because you have already invested in automating your deployment and can deploy new versions of your service without down time ![]()
Debugging Hell
Debugging is always a huge issue in micro-service architectures. E.g., a nested service call fails and you can’t correlate it back to a request coming from the user.
One solution is to use correlation IDs.
When a request comes in, you assign the request with a correlation ID and pass it on to other services in the HTTP request header. Every service would do the same and pass the correlation ID it receives in the incoming HTTP header in any out-going requests. Whenever you log a message, be sure to include this correlation ID in the log line.
It’s a simple pattern, but it’s one that you’ll have to apply in every one of your services and difficult to transparently implement in the entire dev team.
I don’t know how it’d look but I imagine you might be to able to automate this using an AOP framework like PostSharp. Alternatively, if you’re using some form of scaffolding when you start work on a new service, maybe you can include some mechanism to capture and forward correlation IDs.
Missing Mock Servers
When you have a service that other teams depend on, each of these teams would have to mock and stub your service in order to test their own services.
A good step in the right direction is for you to own a mock service and provide it to consumers. To make integration easier, you can also provide the client to your service, and support using the mock service via configuration. This way, you make it easy for other teams to consume your service, and to test their own services they just need to configure the client to hit the mock service instead.
You can take it a step further, by building the mock service into the client so you don’t even have to maintain a mock service anymore. And since it’s all transparently done in the client, your consumers would be none the wiser.
This is a good pattern to use if there is a small number of languages you need to support within your organization.
To help you get started quickly, I recommend looking at Mulesoft’s Anypoint Platform. It comes with an API designer which allows you to design your API using RAML and there’s a built-in mock service support that updates automatically as you save your RAML file.

It’s also a good way to document your API. There’s also a live API portal which is:
- interactive – you can try out the endpoints and make requests against the mock service
- live – it’s automatically updated as you update your API in RAML
- good for documenting your API and sharing it with other teams
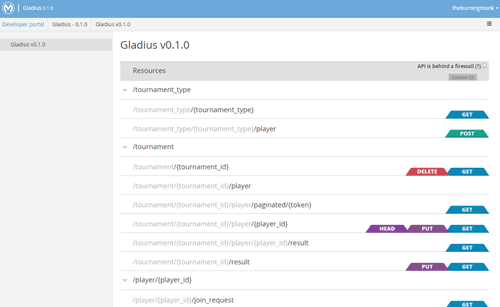
We have been using it for some time and it has proven to be a useful tool to allow us to collaborate and iteratively design our APIs before we put our heads down and code. We have been able to identify information needs not being met and impedance mismatches early and reduced the amount of back-and-forth required.
Flying Blind
With a micro-service architecture the need for on-going operational metrics is greater than ever before, without them you are just flying blind.
There are more than a handful of tools available in this space. There are commercial tools (some with free tiers) such as NewRelic and StackDriver (now integrated into Google AppEngin), AWS also offers CloudWatch as part of its ecosystem. In the open source space, Netflix has been leading the way with Hystrix and something even more exciting.
The granularity of the metrics is also important. When your metrics are measured in 1 minute intervals (e.g. CloudWatch) then your time to discovery of problems could be in the 10-15 minutes range, which pushes time to recover even further out. This is why Netflix built its own monitoring system called Atlas.
Also, you get this explosion of technologies from languages, runtimes and databases, which can be very painful from an operations point of view.
When you introduce containers, this problem is compounded even further because containers are so cheap and each VM can run 100s even 1000s of containers, each potentially running a different technology stack…
The organizational solution here would be to form a team to build tools that enable developers to manage the system in an entirely automated way. This is exactly what Netflix has done and a lot of amazing tools have come out of there and later open sourced.
Summary
- Start boring and extract to services
- Understand the hidden schemas
- Amortize traffic with queues
- Decouple through discovery tools
- Contain failures with circuit breakers
- Use mockable clients.
- Build in operational metrics from the beginning
Links
- CraftConf 15 takeaways
- CraftConf 15 – Takeaways from “Scaling micro-services at Gilt”
- A false choice : Microservices or Monoliths
- Microservices – not a free lunch!
- Dan McKinley – Choose Boring Technology
- Red-White Push – Continuous Delivery at Gamesys Social
- Hacking the brains of other people with API design
- QCon London 15 – Takeaways from”Service architecture at scale, lessons from Google and eBay”
- Adrian Cockcroft @ Monitorama PDX 2014
- [Slides] Why Netflix built its own Monitoring System (and you probably shouldn’t)
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Pingback: A consistent approach to track correlation IDs through microservices | theburningmonk.com
Pingback: CodeMotion 15–Takeaways from “Measuring micro-services” | theburningmonk.com
“Another common mistake is to have a shared database between different services. This creates tight coupling between the services and means you can’t deploy the micro-services independently if it breaks the shared schema. Any schema updates will force you to update other micro-services too.”
This is not entirely true. I hate to be someone nitpicking over something small, but there is something important to be said for shared databases. When an organization is transitioning from Monolithic to Micro based architecture, having shared kernel is acceptable if the dataset is too large. While many others (myself included), would rather see these large datasets broken up into bounded views of data based on the needs of the domain, this is not always possible (see: healthcare, government).
That’s a fair comment, and as with everything else, context is always important and (from the Zen of Python) practicality beats purity.
To that end, the micro-services architecture style itself is not always the best solution, and many folks will argue that it’s better to start with a monolith anyway, and then gradually split into micro-services when the boundaries in your application become clear.
Agree. At some point the relationship between shared databases and micro service would come a full circle anyway when people realise they need read models to efficiently query across services. That monolithic database would be a good candidate.