

Yan Cui
I help clients go faster for less using serverless technologies.

The Serverless Framework [1] is still the most popular deployment framework for serverless applications. It gives you a convenient abstraction over CloudFormation and some best practices out of the box:
- Filters out dev dependencies for Node.js function.
- Update deployment packages to S3, which lets you work around the default 50MB limit on deployment packages.
- Enforces a consistent naming convention for functions and APIs.
But our serverless applications are not just about Lambda functions. We often have to deal with shared resources such as VPCs, SQS queues and RDS databases. For example, you might have a centralised EventBridge bus to capture all application events in the system. In this case, the event bus doesn’t belong to any one service and shouldn’t be tied to their deployment cycles.
You still need to follow the principle of Infrastructure as Code:
- version control changes to these shared resources
- ensure they can be deployed in a consistent way to different environments
You can still use the Serverless Framework to manage these shared resources. It is an abstraction layer over CloudFormation, after all. You can configure AWS resources using normal CloudFormation syntax in YAML.
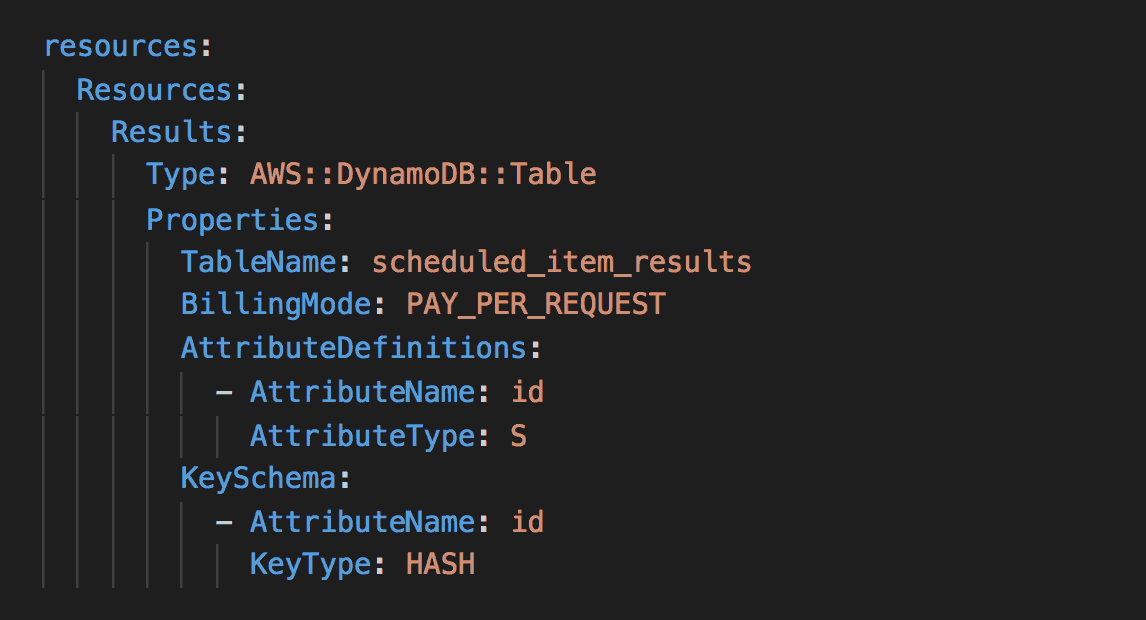
Reference Terraform resources in Serverless Framework
However, DevOps/infrastructure teams often frown upon this. Perhaps the name “Serverless” makes one assume it’s only for deploying serverless applications. On the other hand, Terraform is immensely popular in the DevOps space and enjoys a cult-like following.
I see many teams use both Terraform and Serverless Framework in their stack:
- The Serverless Framework deploys Lambda functions and their event sources (API Gateway, etc.).
- Terraform deploys shared dependencies such as VPCs and RDS databases.
The Serverless Framework translates your serverless.yml into a CloudFormation stack during deployment. It also lets you reference variables from elsewhere, such as CloudFormation outputs or SSM parameters [2]. But there’s no built-in support to reference Terraform state.
Instead, you can do this:
- Create SSM parameters to capture information that should be shared. e.g. ARNs, IDs, names.
- Agree on a structure for the parameter names. e.g. /{env}/{resource}/{param} => /dev/vpc/arn
- Reference these parameters in the
serverless.ymlusing the ${ssm:/path/to/param} syntax.
Alternatives
The Serverless Framework also lets you reference variables from several AWS services, including:
- Another CloudFormation stack’s output
- A JSON file in S3
- SSM Parameter Store
- Secrets Manager
Assuming we’re not talking about application secrets (which is a whole different topic), you should consider outputting them to SSM. It’s the easiest way for you to share information between Terraform and Serverless Framework.
Links
[2] How to reference SSM parameters in the Serverless Framework
Related posts
You should use SSM Parameter Store over Lambda env variables
The Old Faithful: Why SSM Parameter Store still reigns over Secrets Manager
Running and debugging AWS Lambda functions locally with the Serverless framework and VS Code
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.