

Yan Cui
I help clients go faster for less using serverless technologies.

Recently, I have been helping a client implement an event-sourced system. In the process, I put together a very simple demo app to illustrate how one could build such a system using Lambda and DynamoDB. The source code is available on GitHub here.
Before you go ahead and read all about the demo app, I want to give the client in question, InDebted, a quick shout out. They are disrupting the debt collection industry which has been riddled with malpractices and horror stories, and looking to protect the most vulnerable of us in society. They are also doing it by leveraging modern technologies and building with a serverless-first mentality. I have been working with the team for about 4 months and I have nothing but good things to say about them. If you’re looking for opportunities in the Sydney area, or are looking to relocate there, then please get in touch with Wagner. They’re looking for good people.
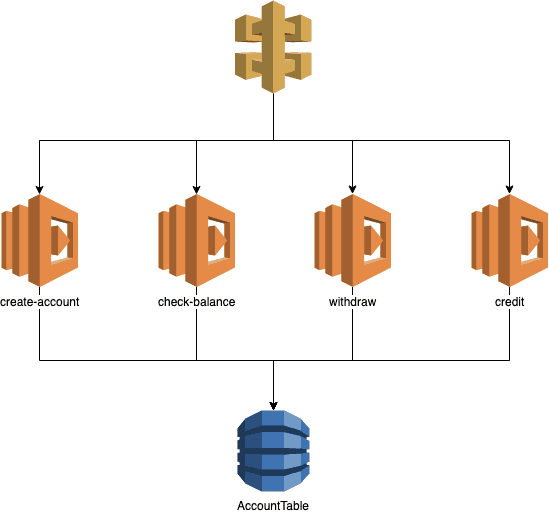
This demo app uses the banking example where a user can:
- create an account
- check his/her balance
- withdraw money
- credit the account
DynamoDB is the datastore.
Events
Every time the account holder withdraws from or credits the account, I will record an event.

It means that when I need to work out the current balance of the account I will have to build up its current state from these events.
Snapshots
A common question people ask about event-sourced systems is “how do you avoiding reading lots of data on every request?”
The solution is to create snapshots from time to time. In this demo app, I ensure that there are regular snapshots of the current state. One snapshot for every 10 rows in the table, to be precise.
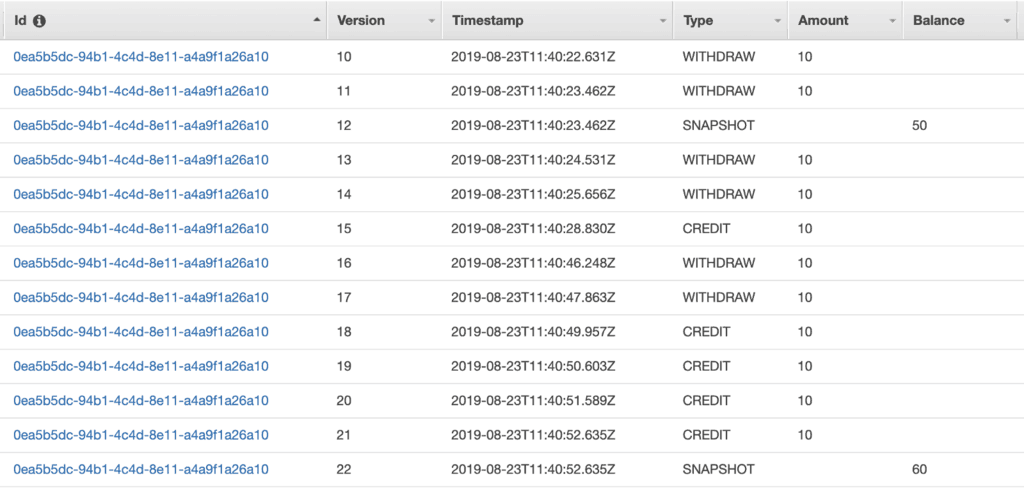
These snapshots allow me to limit the number of rows I need to fetch on every request. In this case, I have a constant cost of fetching 10 items every time.
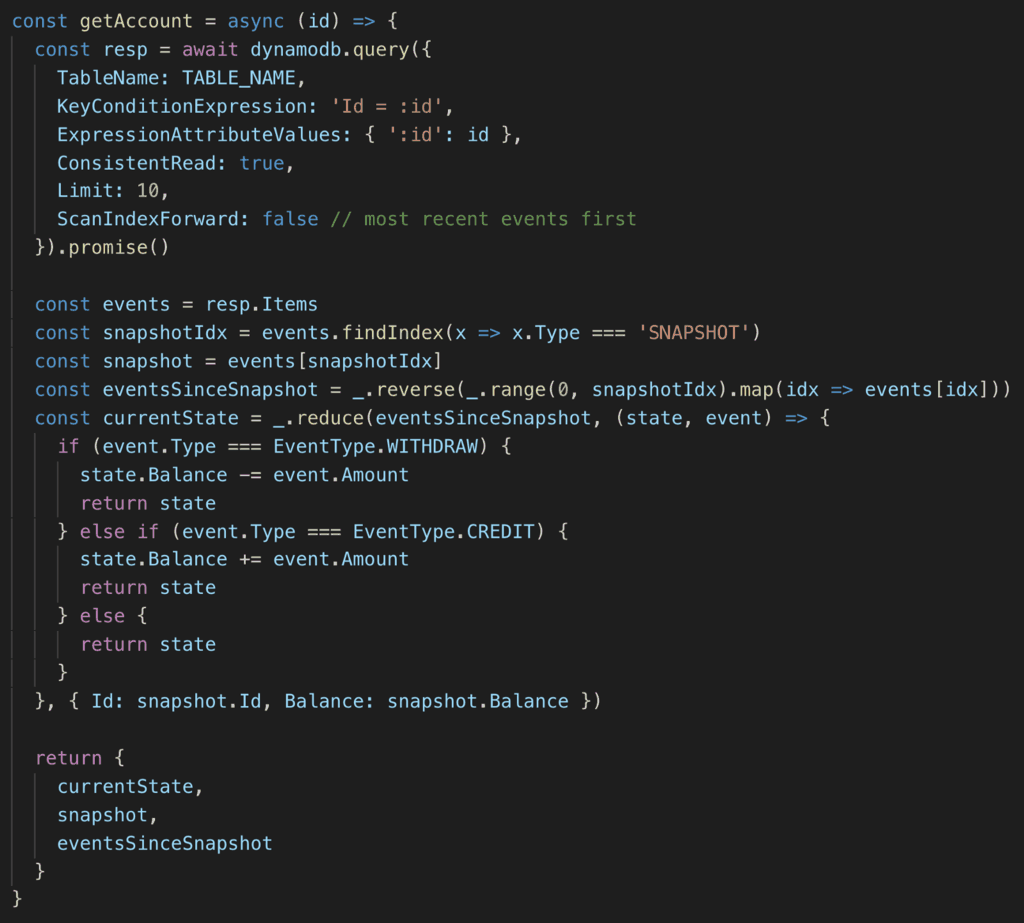
Rebuilding the current state
To rebuild the current state, I find the most recent snapshot and apply the events since the snapshot was taken.
For example, given the below:

The most recent snapshot is Version 22, with a Balance of 60. There have been 3 events since then. So the current balance is 60–10–10+10 = 50.
Here’s what it looks like in code:
Optimistic locking
To protect against concurrent updates to the account, the Version attribute is configured as the RANGE key. Whenever I add an event to the DynamoDB table, I will check that the version doesn’t exist already.

Optimizations
To bring down the cold start as well as warmed performance of the endpoints. I applied a number of basic optimization:
- enable HTTP keep-alive for the AWS SDK
- don’t reference the full AWS SDK
- use webpack to bundle the functions
Streaming events to other consumers
It wasn’t included in the demo app, but you can also stream these events to other systems by:
a) letting other services subscribe to the DynamoDB table’s stream
b) create another Kinesis stream, and convert these DynamoDB INSERT events into domain events such as AccountCreated and BalanceWithdrawn.

My personal preference would be option b. It lets other consumers work with domain events and decouples them from implementation details in your service.
From here, you can also connect the Kinesis stream to Kinesis Firehose to persist the data to S3 as the data lake. You can then use Athena to run complex, ad-hoc queries over ALL the historical data, or to generate daily reports, or to feed a BI dashboard hosted in QuickSight.
Further reading
If you want to learn more about event-sourcing in the real-world (and at scale!), I recommend following this series by Rob Gruhl. Part 2 has some delightful patterns that you can use. You should also check out their Hello-Retail demo app.
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.