
Yan Cui
I help clients go faster for less using serverless technologies.

Lean manufacturing focuses on minimizing waste while simultaneously maximizing productivity.
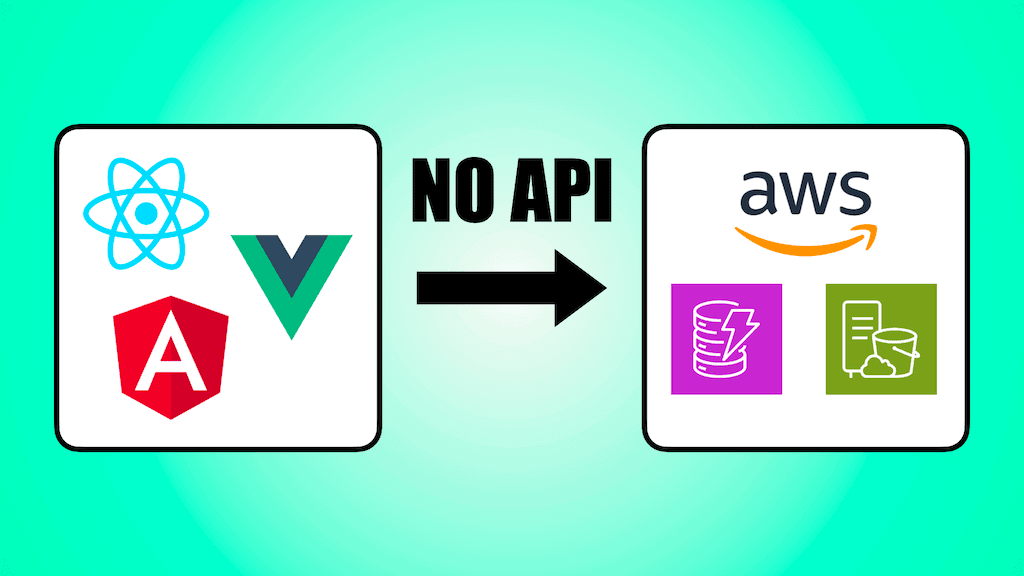
If you apply the same mindset and look at our applications today, you will find many CRUD APIs that add little value beyond authentication and authorization. That is, they provide authorised access to a database and ensure a user can’t access someone else’s data.
However, AWS services such as DynamoDB and S3 already have authorization control through AWS IAM. So what if we remove the API layer altogether and let the frontend application talk to AWS services directly?
This is not only possible but can be cost-effective and secure, thanks to AWS Cognito Identity Pools and DynamoDB’s leading key condition [1].
In this post, I will show you how. And I will explain when you should consider this radical approach.
You can try out our live demo app here [2] and see the code here [3].
What are Cognito Identity Pools?
Cognito Identity Pools lets you federate identity authentication to an identity provider such as Cognito User Pool and issue AWS credentials to your users so they can access AWS services directly.
It will validate the token. Make sure it’s valid, hasn’t expired and that the user hasn’t been signed out globally. And issue temporary AWS credentials for a pre-configured IAM role.
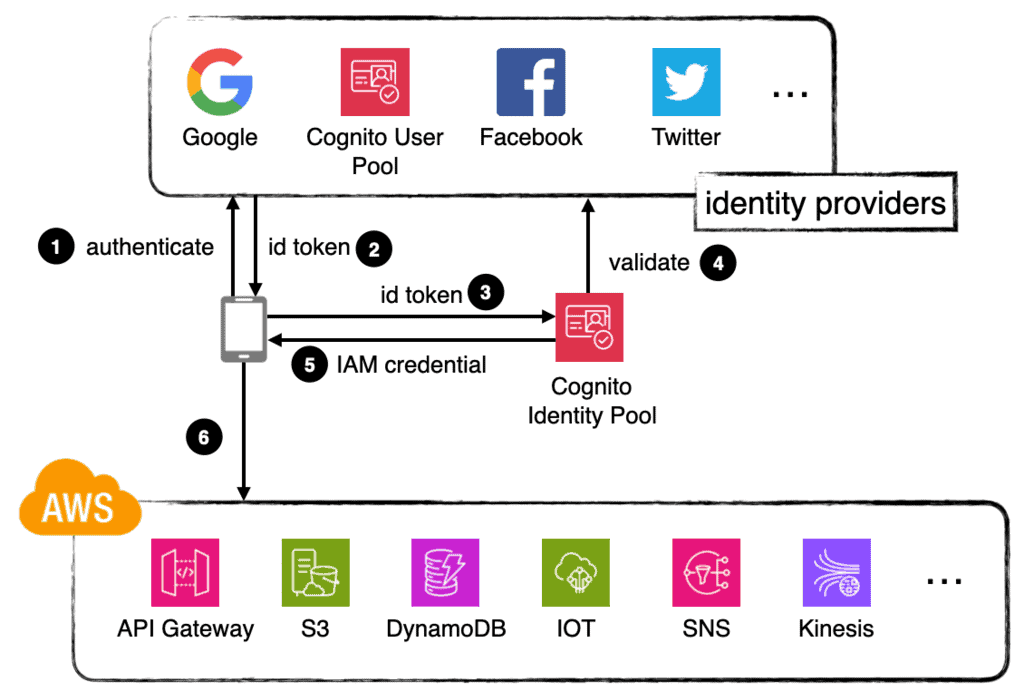
Cognito Identity Pools can also issue temporary AWS credentials for unauthenticated users. This is often used for:
- Allow IOT devices to publish data to IOT Core.
- Allow frontend applications to publish click-stream events to Kinesis Firehose or AWS Pinpoint.
However, for this blog post, we are only interested in the authenticated use case.
Fine-grained access control with IAM
For the demo app, we will use Cognito User Pool as the identity provider. The frontend would:
- Authenticate the user against the Cognito User Pool.
- Exchange the ID token with the Cognito Identity Pool and receive a set of temporary AWS credentials.
- Use the AWS credentials to talk to DynamoDB and S3.
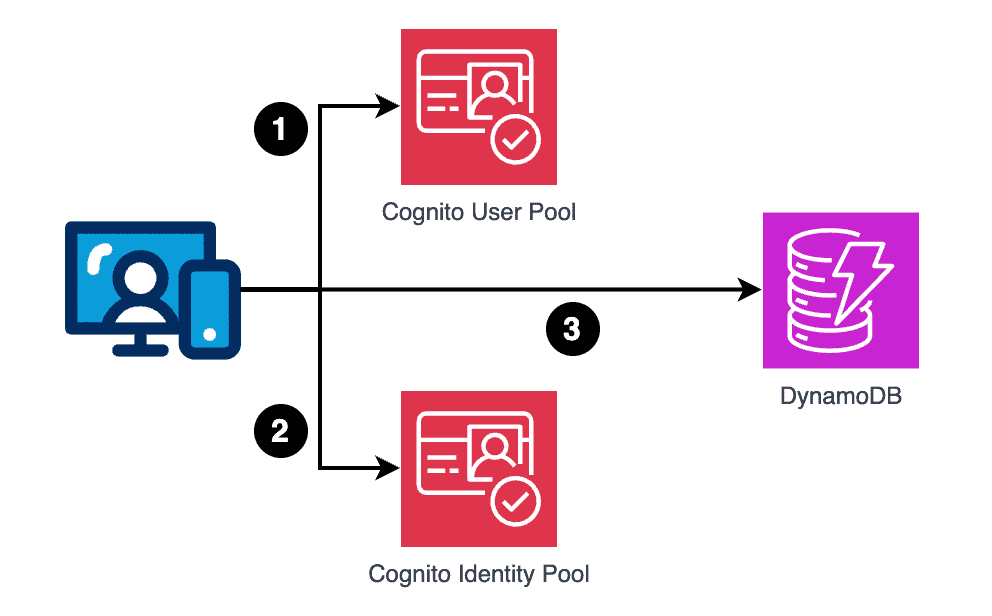
The Cognito Identity Pool uses the Cognito User Pool as the identity provider. A default authenticated IAM role is used for all authenticated users.
CognitoIdentityPool:
Type: AWS::Cognito::IdentityPool
Properties:
IdentityPoolName: FeToDDBDemoIdentityPool
AllowUnauthenticatedIdentities: false
CognitoIdentityProviders:
- ClientId: !Ref CognitoUserPoolClient
ProviderName: !GetAtt CognitoUserPool.ProviderName
ServerSideTokenCheck: true
CognitoIdentityPoolRoleAttachment:
Type: AWS::Cognito::IdentityPoolRoleAttachment
Properties:
IdentityPoolId: !Ref CognitoIdentityPool
Roles:
authenticated: !GetAtt CognitoIdentityPoolRole.Arn
The key to ensuring the user can not access other people’s data is in this IAM role’s policy.
CognitoIdentityPoolRole:
Type: AWS::IAM::Role
Properties:
RoleName: FeToDDBDemoAuthenticatedRole
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Federated: cognito-identity.amazonaws.com
Action:
- sts:AssumeRoleWithWebIdentity
Condition:
StringEquals:
cognito-identity.amazonaws.com:aud:
Ref: CognitoIdentityPool
Policies:
- PolicyName: FeToDDBDemoAuthenticatedRolePolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
- dynamodb:Query
Resource: !GetAtt DynamoDBTable.Arn
Condition:
ForAllValues:StringEquals:
dynamodb:LeadingKeys:
- "${cognito-identity.amazonaws.com:sub}"
- Effect: Allow
Action:
- s3:PutObject
- s3:GetObject*
Resource:
- !Sub ${S3Bucket.Arn}/${cognito-identity.amazonaws.com:sub}/test.json
There are several things worth noting here:
1. The IAM role’s assume role policy. This policy only allows the aforementioned Cognito Identity Pool to assume this role.
2. The dynamodb:LeadingKeys condition associated with the DynamoDB actions. This condition allows users to access only the items where the partition key matches their Identity ID.
The Identity ID can be retrieved by calling Cognito Identity Pool’s GetId API [4]. It looks like this: us-east-1:310d28ad-a894–4ce1-b787-b3023ca2094c.
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:UpdateItem
- dynamodb:DeleteItem
- dynamodb:Query
Resource: !GetAtt DynamoDBTable.Arn
Condition:
ForAllValues:StringEquals:
dynamodb:LeadingKeys:
- "${cognito-identity.amazonaws.com:sub}"
3. The Resource associated with the S3 actions. This allows the users to access only the object with the key:
${cognito-identity.amazonaws.com:sub}/test.json
Where ${cognito-identity.amazonaws.com:sub} is their Identity ID.
- Effect: Allow
Action:
- s3:PutObject
- s3:GetObject*
Resource:
- !Sub ${S3Bucket.Arn}/${cognito-identity.amazonaws.com:sub}/test.json
You can relax this to allow the users to access any objects in their dedicated folder.
Resource:
- !Sub ${S3Bucket.Arn}/${cognito-identity.amazonaws.com:sub}/*
We can securely allow the frontend application to access AWS resources directly using these fine-grained access controls.
The frontend application
In the frontend application, we need to first authenticate the user against the Cognito User Pool.
const signInResult = await Auth.signIn({
username: email.value,
password: password.value
})
Once the user is signed in, we can fetch the user’s ID token from their auth session.
const session = await Auth.fetchAuthSession()
As mentioned above, the user is only allowed to act on his or her data in DynamoDB and S3.
To find the user’s Identity ID, we need to call the GetId API [4] with the user’s ID token.
const getIdResp = await cognitoClient.send(new GetIdCommand({
IdentityPoolId: import.meta.env.VITE_COGNITO_IDENTITY_POOL_ID,
Logins: {
[import.meta.env.VITE_COGNITO_PROVIDER_NAME]: session.tokens.idToken.toString()
}
}))
Next, we get the temporary AWS credentials from Cognito’s GetCredentialsForIdentity API [5]. We need the user’s Identity ID as well as the ID token.
const getCredResp = await cognitoClient.send(new GetCredentialsForIdentityCommand({
IdentityId: getIdResp.IdentityId,
Logins: {
[import.meta.env.VITE_COGNITO_PROVIDER_NAME]: session.tokens.idToken.toString()
}
}))
Finally, we can use these credentials to initialize the DynamoDB and S3 clients.
const dynamoDBClient = new DynamoDBClient({
region: import.meta.env.VITE_AWS_REGION,
credentials: {
accessKeyId: getCredResp.Credentials.AccessKeyId,
secretAccessKey: getCredResp.Credentials.SecretKey,
sessionToken: getCredResp.Credentials.SessionToken
}
})
const documentClient = DynamoDBDocument.from(dynamoDBClient)
const s3Client = new S3Client({
region: import.meta.env.VITE_AWS_REGION,
credentials: {
accessKeyId: getCredResp.Credentials.AccessKeyId,
secretAccessKey: getCredResp.Credentials.SecretKey,
sessionToken: getCredResp.Credentials.SessionToken
}
})
See it in action
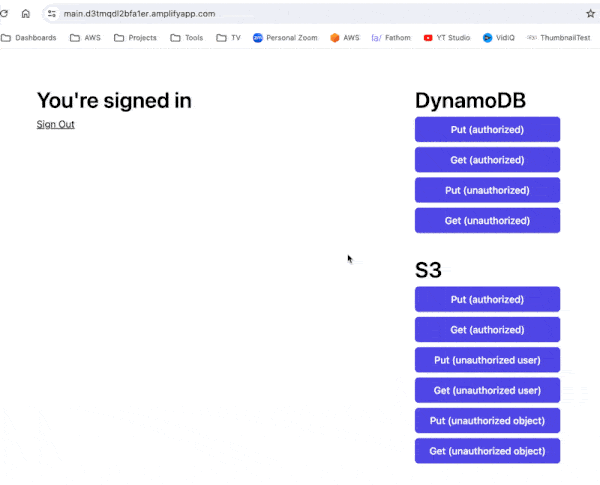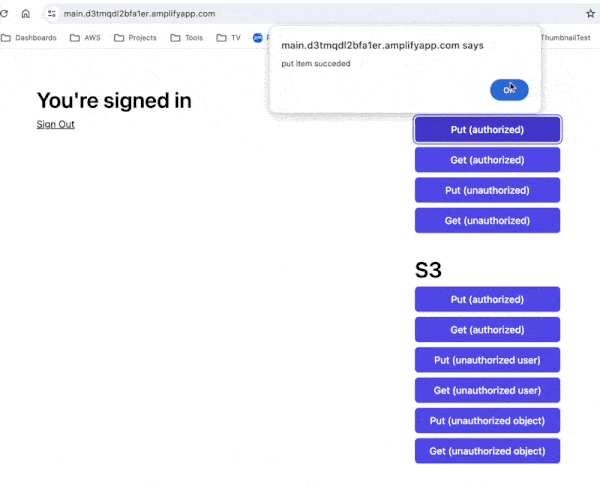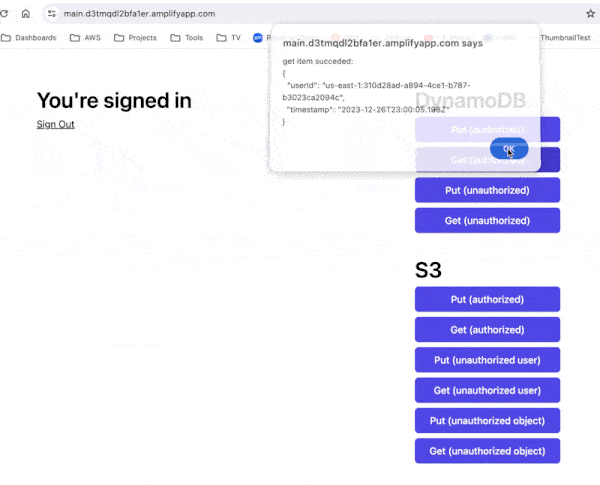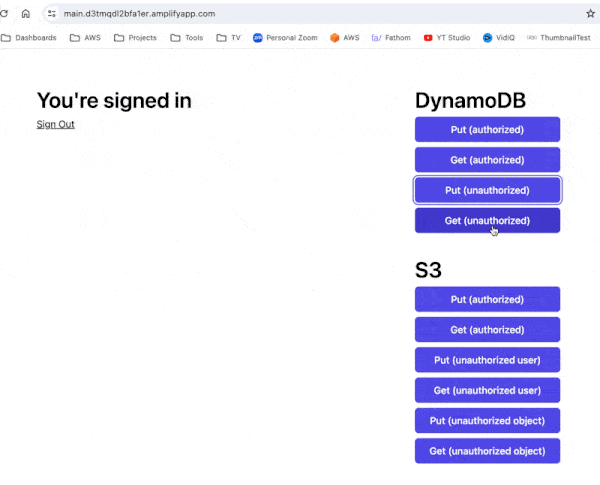
I have put together a live demo app [2] for you to try it out yourself.
Once logged in, you can use the buttons to read and write data in a DynamoDB table and S3.
The “authorized” buttons act on the user’s data, while the “unauthorized” buttons attempt to act on another user’s data.
As you can see, the IAM role only allows the frontend application to access data that belong to the logged-in user.
You are free to poke around in the source code as well. You can find both the backend and frontend code in this repo [3].
When to use this approach?
As you can see, it’s possible to securely let the frontend application talk to AWS resources directly.
This can be a very cost-effective solution for projects where reducing infrastructure costs is a top priority.
This approach eliminates the need for API Gateway and Lambda functions, thereby cutting down on costs associated with these services. It allows scalable and secure data access, where users can only access their data.
With this approach, you can also improve end-to-end latency. Because we have removed the overhead and potential bottlenecks (e.g. concurrency limits or cold start penalties) from API Gateway and Lambda.
When NOT to use this approach
While the benefits are significant, it’s crucial to be aware of the potential challenges and risks associated with this approach.
Here are some reasons why you shouldn’t use this approach:
- Regulatory requirements. Many regulations (e.g. HIPAA) require additional layers of logging, auditing, or data handling (e.g. encryption) that are impossible to enforce with this approach.
- Complex authorization requirements. If your application requires complex authorization logic that can’t be easily mapped to IAM roles and policies, then this approach is also not suitable.
- Rate limiting and Throttling. This approach doesn’t provide rate limiting or throttling. Which are often crucial in preventing abuse or simply protecting your application from denial-of-service attacks.
- Sensitive business logic. With this approach, all of your business logic would need to be implemented in the frontend application. For many organizations, this business logic is a trade secret and needs to be closely guarded.
- Global audience. Applications serving a global audience might face variable latencies when accessing AWS services directly from different regions. A well-configured CDN or intermediary API can offer more consistent performance globally.
- Complex transactions. If your application requires orchestrating multiple AWS services in a single request, managing this complexity on the client side can be challenging and might lead to inefficient code. An intermediary layer can abstract away this complexity.
In addition to the above, this approach also introduces many challenges to the development process. For example,
- You often have to deal with CORS issues, which can be difficult to debug.
- You have to bundle the AWS SDK into the frontend application. This can add bloat to the frontend application and negatively affect the performance and SEO score of the application.
- Debugging and handling errors can be more challenging on the client side, especially when dealing with AWS service nuances.
- Using the AWS SDK directly in the frontend can lead to security risks if not properly managed.
Conclusion
As we’ve explored in this post, directly accessing AWS services from frontend applications can offer significant benefits in terms of cost efficiency and performance. This approach eliminates the need for intermediaries like API Gateway and Lambda, thereby streamlining your architecture.
However, it’s crucial to balance these advantages against the many potential drawbacks we discussed above.
In my opinion, for 97% of applications out there, this approach is a premature optimization.
But for the other 3% of applications, this can be a good solution to minimize waste while simultaneously maximizing cost-efficiency and performance.
Remember, the best solutions are those tailored to specific challenges and goals. As you navigate the world of AWS and serverless, please don’t hesitate to reach out to me for support.
If you want to learn more about building serverless applications for the real world, then why not check out my next workshop [6]? The next cohort starts on January 8th, so there is still time to sign up and level up your serverless game in 2024!

Links
[1] Using IAM policy conditions for fine-grained access control
[2] Live demo app
[3] The demo project source code
[4] Cognito Identity Pool’s GetId API endpoint
[5] Cognito Identity Pool’s GetCredentialsForIdentity API endpoint
[6] Production-Ready Serverless workshop
Related Posts









Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.