
Yan Cui
I help clients go faster for less using serverless technologies.

DISCLAIMER : as always, you should benchmark against your payload and use case, the benchmark numbers I have produced here is unlikely to be representative of your use cases and neither is anybody else’s benchmark numbers.
You can use the simple test harness I created and see these example code to benchmark against your particular payload.
I updated my binary and JSON serializers benchmark earlier this week, and got some feedbacks on new serializers that I have missed, namely Chiron and Microsoft’s Bond. Here, we’ll have a look how the two fared in the benchmark.
MS Bond
Microsoft announced their answer to Google’s Protocol Buffer with Bond this time last year (Jan 2015). Finally I’ve got around to actually test it out (after an ex-Gamesys colleague commented on the last update – thanks Rob!).
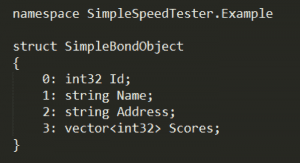
First, you define you contract with a .bond file (see tutorial here), for example…
Now you run the Bond compiler tool, gbc, against this file to generate a C# class that looks like this…
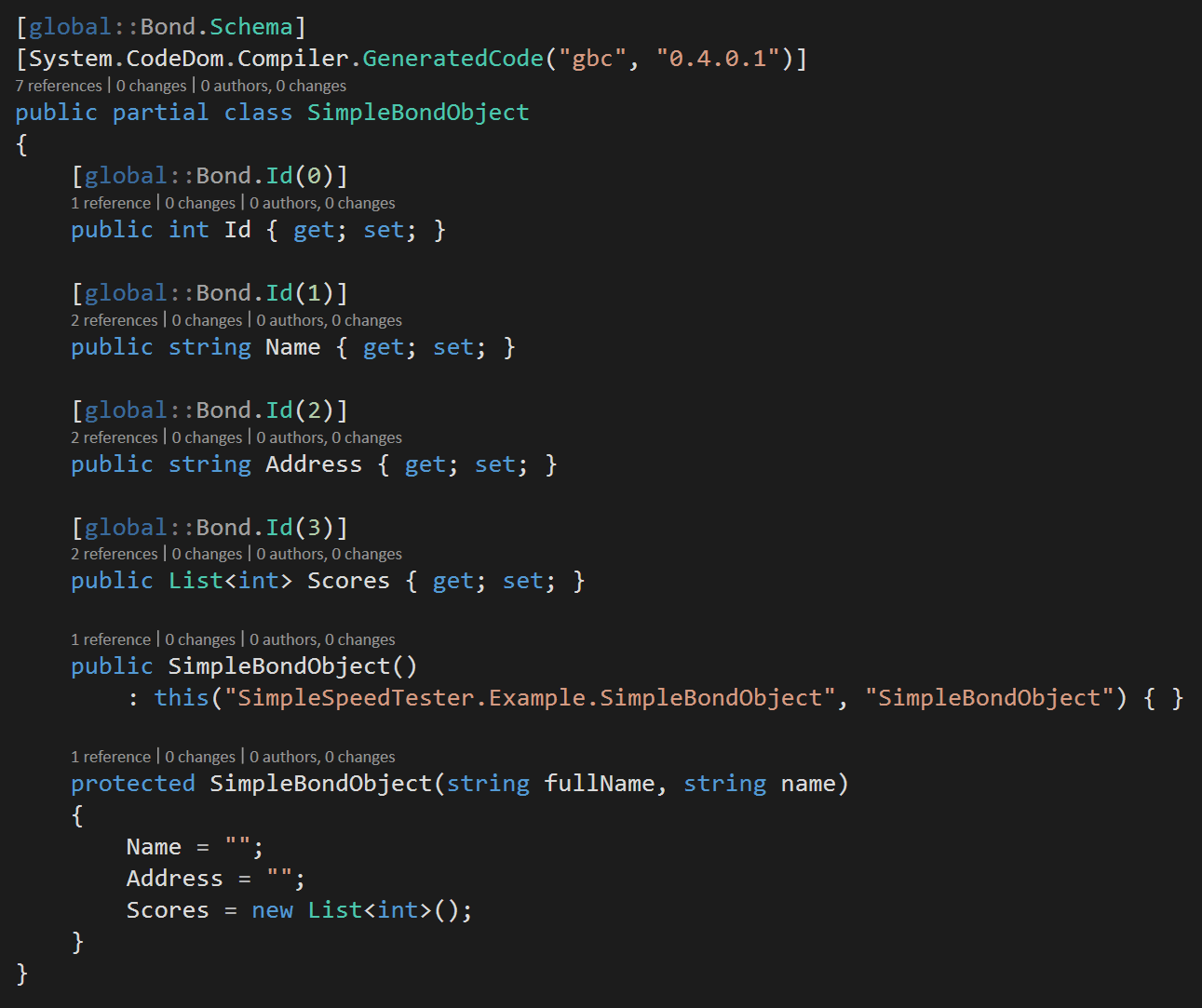
To serialize and deserialize data, you also need to add the Bond C# nuget package to your project and follow the examples in the aforementioned tutorial.
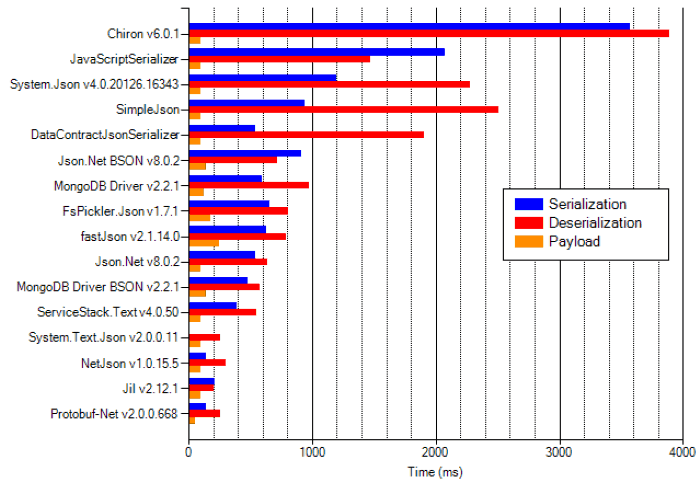
Here’s how Bond fared against other binary serializers on my list.
NOTE: there’s an updated benchmark test that uses a different initial buffer size which makes a huge difference in performance for Bond. Please read the linked post for more info.
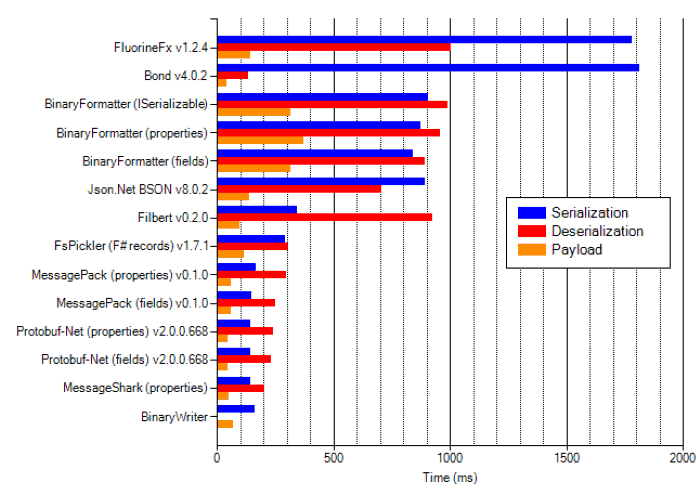
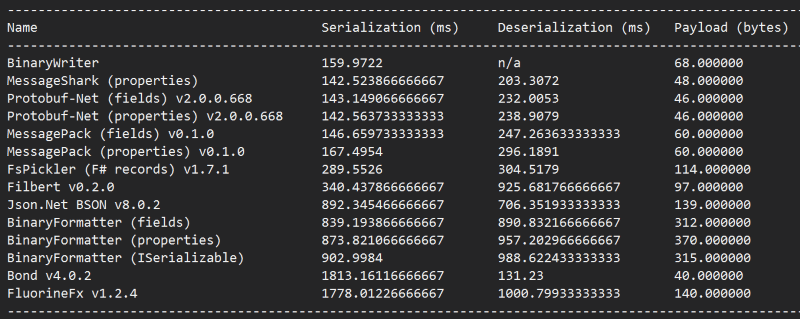
The result makes for an interesting reading…
- Bond produced the smallest payload, and is the fastest at deserializing the payload by some distance.
- It is also the slowest at serializing the payload!
Chiron
I read about Chiron in Marcus Griep‘s F# advent post but then forgot about it (totally my bad… too many hours on Bloodborne over xmas, such an awesome game ![]() ).
).
Anyways, Chiron has a F#-friendly API but because it uses statically resolved type parameters you can’t use it from C#.
In order to serialize/deserialize a type, the type needs to define the static methods ToJson and FromJson. The inlined serialize and deserialize functions can then constraint your type to have those static members and invoke them in the corresponding function. I used the same technique in MBrace.AWS and honestly, I’m not happy with the amount of work this pushes onto the user, especially when they end up having to write uninteresting plumbing code…
On the API front, I’m not thrilled with the custom operators either, even though there are only 3 of them so I’m probably just over-reacting. In general I find custom operators get in the way of discovery.
Reading through the post, this paragraph suggests a lot of intermediate JsonResult<‘a> and Json objects are created during the serialization process. Whilst this might be an idiomatic functional approach, it’s also likely to hurt our performance..
The
*>operator that we used inToJsondiscards theJsonResult<'a>(which is only used when writing), but continues to build upon theJsonobject from the previous operation. By chaining these operations together, we build up the members of aJson.Object.
Unsurprisingly, the cost of immutability proved really costly under the benchmark.
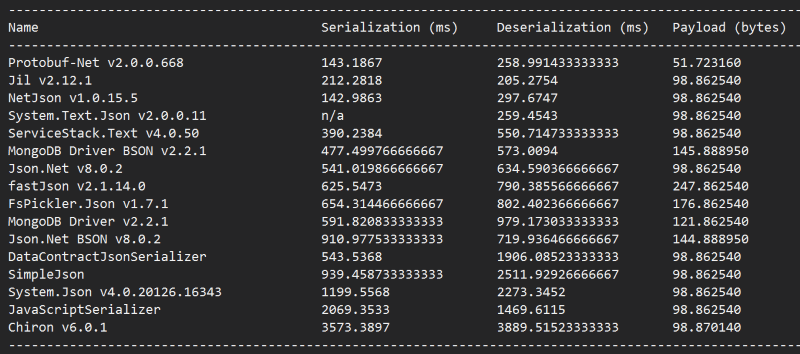
So that’s it folks, another 2 serializers added to our stable. If there any other serializers that you think I should include here, please give me a shout and I’ll do my best to accommodate.
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.
Hi Yan, Can you use Bond.IO.Unsafe.OutputBuffer in your benchmark code instead of Bond.IO.Safe.OutputBuffer?
Based on bond doc: http://microsoft.github.io/bond/manual/bond_cs.html, “The OutputBuffer class implements IOutputStream interface on top of a memory buffer. It comes in two variants. Bond.IO.Safe.OutputBuffer uses only safe managed code and is included in Bond.dll assembly which is compatible with Portable Class Library. Bond.IO.Unsafe.OutputBuffer uses unsafe code to optimize for performance. It is included in Bond.IO.dll assembly which requires full .NET runtime. Both implementations have identical class names and APIs, the only difference is the namespace in which they are defined.”
Pingback: MS Bond benchmark updated | theburningmonk.com
Hi Yue, have a look at this updated post – https://theburningmonk.com/2016/01/ms-bond-benchmark-updated/ which includes some benchmark results having tuned the initial buffer size to better fit the payload, makes a huge difference.
I can include a few other tests to see the difference with the various tuning options turned on/off too.
Yan, thanks for your interest in Bond and for reaching out to us. Pleased to see that we are now performing well since performance matters for us. Given the update, would you mind updating this statement in the text above? “It is also the slowest at serializing the payload!” should now be “fastest”, I think. Also, it would be great to add the updated benchmark to your Benchmark summary page too. Please feel free to reach out for any other Bond-related questions.
Yan, there seems to be a new JSON parser for .NET, called Revenj. You may want to include it in the benchmarks:
https://github.com/ngs-doo/json-benchmark/