

Yan Cui
I help clients go faster for less using serverless technologies.

I’m a long-time user of the Serverless framework and a big fan of its plugin system. It offers tremendous flexibility and there exists a rich ecosystem of community-driven plugins. It’s easily the Serverless framework’s greatest strength and the reason why I keep going back to it.
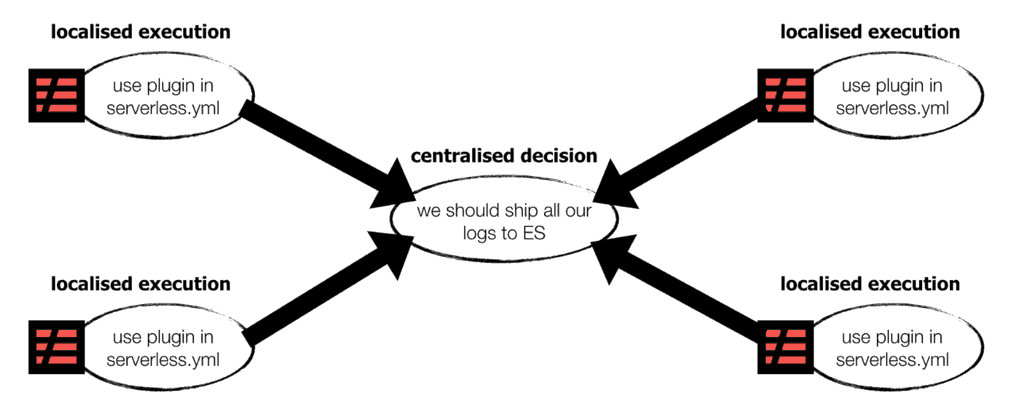
However, I have observed a common pattern where customers would overextend the use of plugins. A typical example is using plugins to manage log subscriptions for log aggregation.
Centralised logging is a “centralised decision” that applies to all your serverless projects. What logging service do you use? How do you ship the logs from CloudWatch to that service? Do you use Lambda directly or proxy through a Kinesis stream first?
Executing this decision at the project level has some problems:
- Copy-and-paste configuration in every
serverless.yml. It’s laborious and difficult to enforce consistency in a large organization. - It’s difficult and risky to change that decision later. You’d need to do a coordinated rollout of every project to every environment.
Instead, for decisions that apply to ALL projects, you should build them into your platform. And by “platform”, I mean a collection of capabilities that are implemented once per account or region.
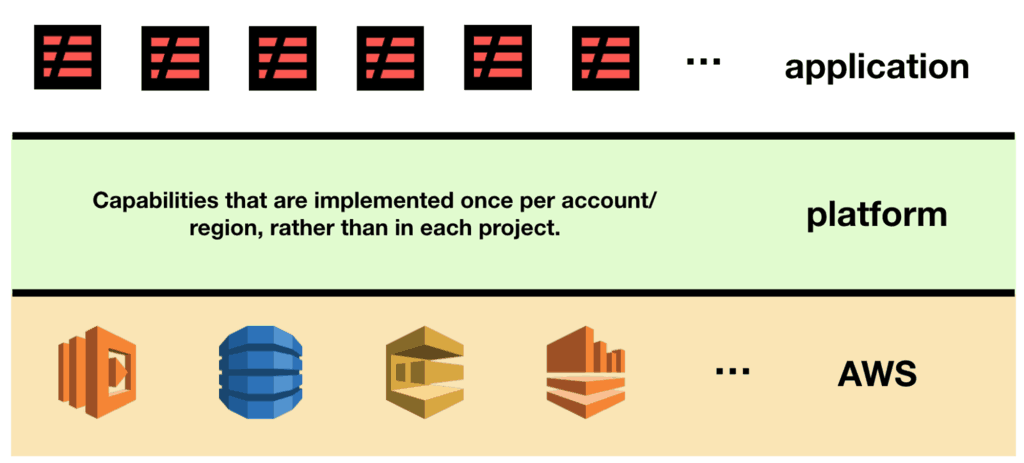
Capabilities such as:
- logs would be delivered to your chosen logging service, be it Elasticsearch, Logz.io, Loggly, NewRelic or whatever it might be.
- log retention policies are configured to X days to reduce storage cost.
- functions can record custom metrics with StatsD format log messages.
- CloudFormation tags are propagated to all resources to enable better cost tracking.
But not all decisions are applicable to all your projects. Decisions that are specific to one project, or need to be tailored for each project, should be implemented at the project level. Plugins are a good way to implement these decisions.
For instance, serverless-webpack makes it easy for you to use webpack to bundle and minimize your deployment artefact. It can have a big impact on reducing the cold start duration of your function too.
The decision to use webpack is specific to one project. It’s a decision based on the needs of that project. For example, you’re building a user-facing API using Node.js, so you care about cold start durations.
How do you implement such a platform?
In the simplest form, you can implement it using two CloudFormation templates:
- an account template for account level resources such as IAM roles, CloudTrail and S3 bucket, etc.
- a region template for regional resources such as VPCs, security groups, etc.
This approach is likely sufficient for a small startup. But it’s not going to scale for Enterprises, where you have many teams and complex security and compliance requirements. That’s where AWS Control Tower comes in.
Control Tower lets you template the baseline configuration for new accounts. You can then use the account factory to quickly provision them. If you’re new to Control Tower, then check out this session from re:inforce 2019.
The Serverless Application Repository (SAR) is a good way to make reusable components that can be plugged into your platform. Here are some SAR apps that I have published to implement platform-level capabilities:
- lambda-janitor: cron job to delete old, unused versions of all Lambda functions in the region to free up storage space.
- auto-subscribe-log-group-to-arn: subscribes new and existing CloudWatch log groups to a Lambda function, Kinesis stream, or Firehose delivery stream by ARN.
- auto-set-log-group-retention: updates the retention policy for new and existing CloudWatch log groups to a specified number of days to reduce CloudWatch Logs cost.
- async-custom-metrics: lets you record custom metrics by writing to stdout (which is recorded in CloudWatch Logs) which is then parsed and forwarded to CloudWatch metrics as custom metrics.
- propagate-cfn-tags: propagates CloudFormation tags to resources that are not automatically tagged, e.g. CloudWatch log groups.
- autodeploy-layer: automatically deploys a Lambda layer to all new and existing functions in the region. Supports opt-in and opt-out via function tags.
The Serverless framework has also introduced Serverless Components. It is an alternative to SAR for building reusable and composable applications. But since it’s specific to the Serverless framework, you won’t be able to use it with Control Tower’s account factory. Because account factory relies on AWS Service Catalog and CloudFormation.
Summary
In summary, the rule of thumb is:
- If the capability is universal and should apply to all of your serverless projects, then build it into your platform.
- Otherwise, use a plugin to implement capabilities that are required at a project-by-project basis.
References
- Centralised logging for AWS Lambda
- Centralised logging for AWS Lambda, revisited (2018)
- Just how expensive is the full AWS-SDK?
- AWS re:Inforce 2019: Using AWS Control Tower to Govern Multi-Account AWS Environments (GRC313-R)
I hope you’ve found this post useful. If you want to learn more about running serverless in production and what it takes to build production-ready serverless applications then check out my upcoming workshop, Production-Ready Serverless!
In the workshop, I will give you a quick introduction to AWS Lambda and the Serverless framework, and take you through topics such as:
- testing strategies
- how to secure your APIs
- API Gateway best practices
- CI/CD
- configuration management
- security best practices
- event-driven architectures
- how to build observability into serverless applications
and much more!
Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.