

Yan Cui
I help clients go faster for less using serverless technologies.

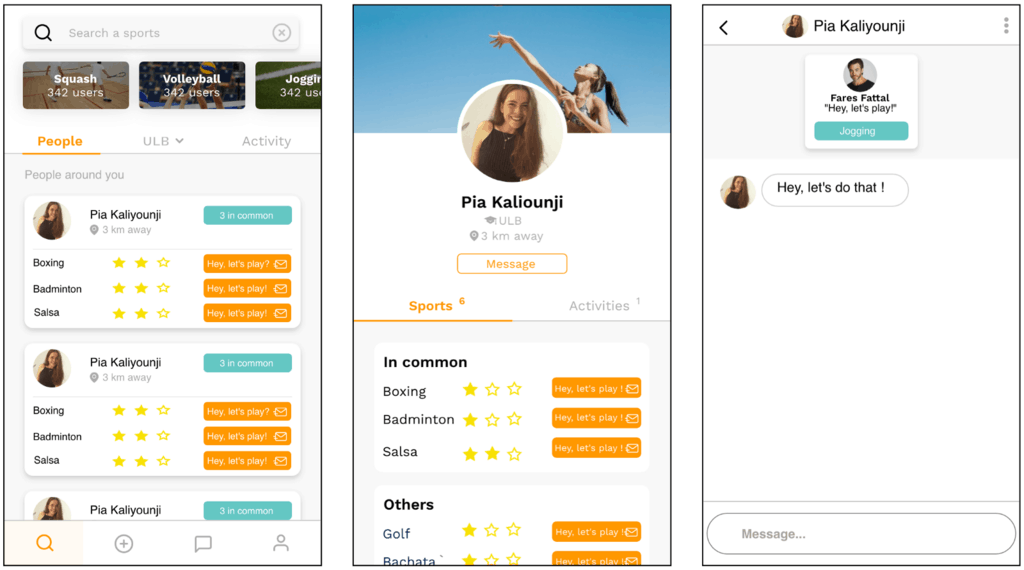
I have been involved with a client project to help the client launch a new social network for university students to engage with each other to do sports.
Amongst other things, users can:
- Arrange activities and ask to join others’ activities (like a basketball match or to run in the park).
- There’s private messaging.
- Users can book sports classes organized by their university’s sports centre.
And so on.
The client is a bootstrapped startup and we had to launch the app before the semester restarted in September 2020. So both the budget and the timeline was tight and that helped inform a lot of my technology choices.
- We need to maximize the speed of development. The client can’t afford a long development cycle.
- The system needs to be able to scale to millions of users if it takes off. The client had agreements in place to launch at several universities in Belgium.
- The system needs to require minimum upkeep. The client doesn’t have the budget for a fulltime team to look after this.
- The system needs to be cost-efficient.
Given these requirements, the choice of GraphQL and serverless technologies made perfect sense. For the initial launch version of the app, I worked part-time and delivered the entire backend in under 4 weeks. In fact, I built the backend for both a mobile app as well as a CMS system for the founders and university admins to manage their sports programmes.
The stack
The tech stack includes:
- S3 and CloudFront for hosting and serving static assets.
- AppSync is the managed GraphQL server.
- Cognito User Pool to provide authentication and authorization, including using identity federation for social sign-in with Facebook and Apple.
- DynamoDB as the backend database.
- Lambda for business logic.
- Algolia as the search service.
- DynamoDB streams and Lambda to synchronize data changes to Algolia.
- Kinesis Firehose streams to collect BI (business intelligence) events and write them to S3.
- Athena to run ad-hoc BI reports against the BI data collected in S3.
- Serverless framework for IaC (infrastructure-as-code) for the backend.
- Lumigo for monitoring and troubleshooting.
- GitLab as source code repository and GitLab CI/CD for CI/CD.
While this is not the full architecture, these are the components I used and how they’re connected at a high level.
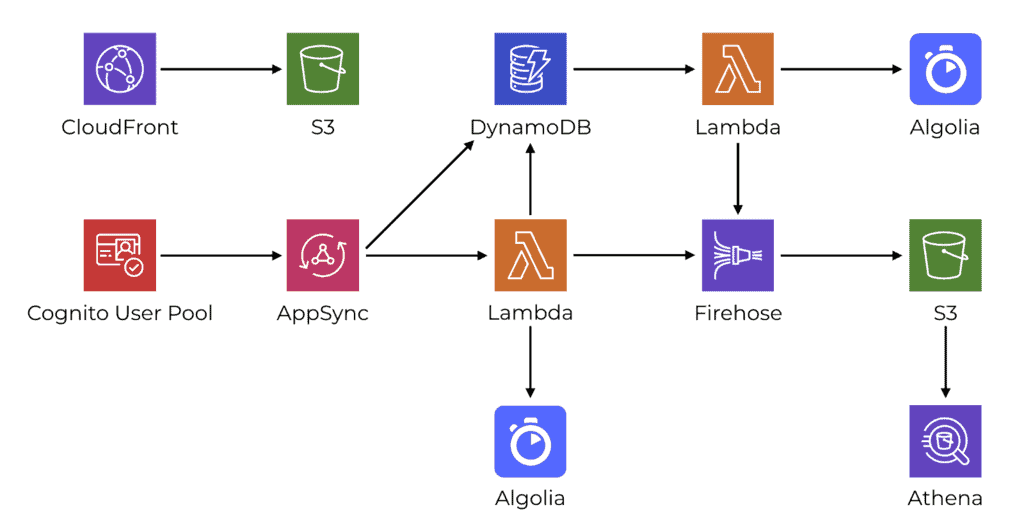
While most of the AppSync resolvers connect to DynamoDB directly, I also use Lambda resolvers where it makes sense. For example, where I have more complex validation logic that is hard to do in VTL, or when I need to integrate with 3rd party services such as Algolia.
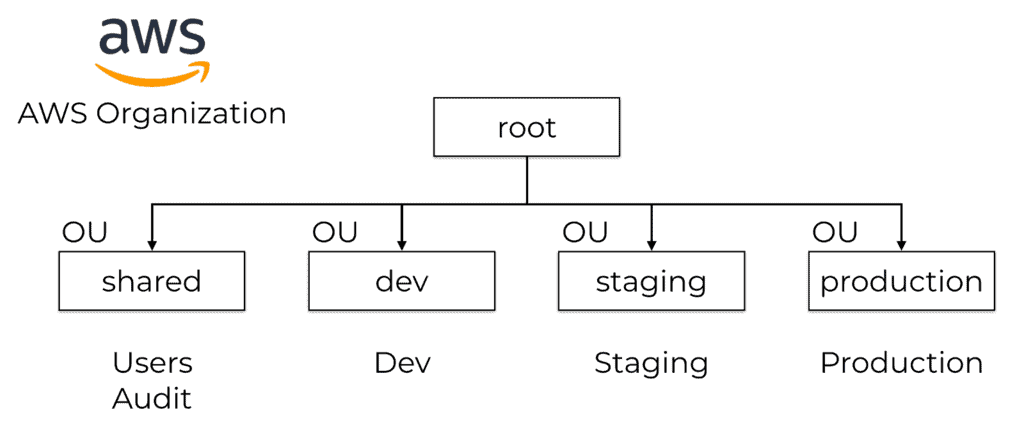
AWS Organization
On the AWS account level, I use AWS Organizations and group the AWS accounts into several OUs (Organization Units).
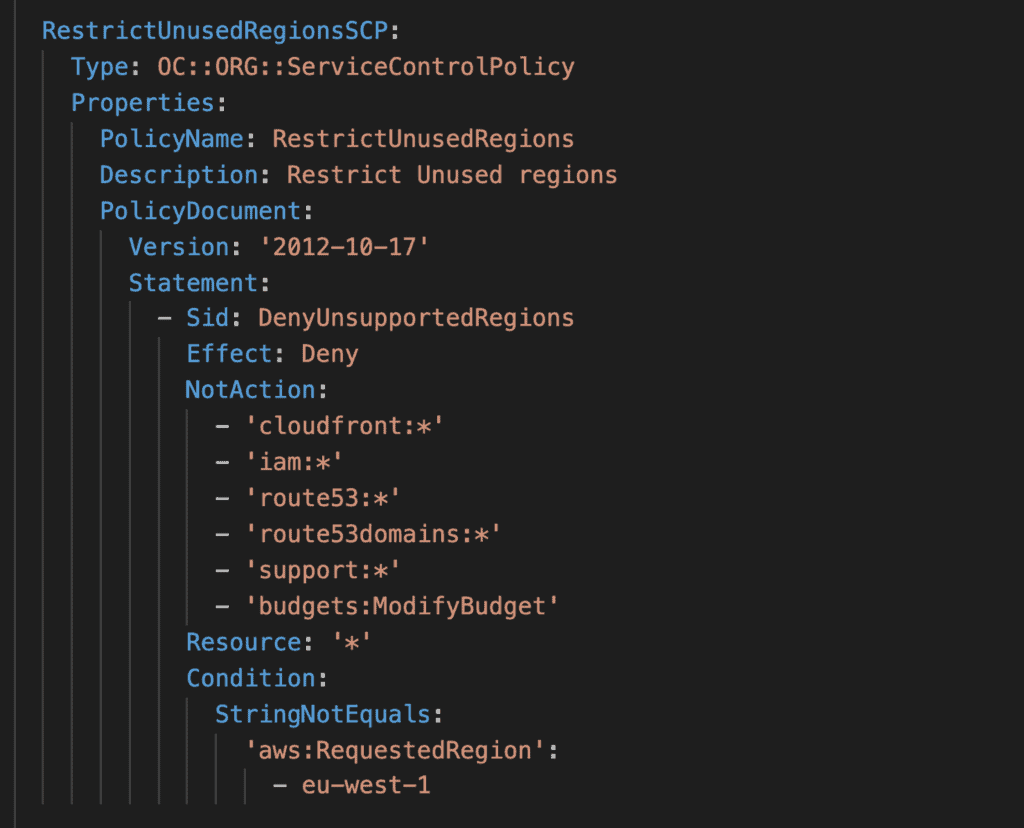
Several SCPs (Service Control Policies) are applied to the organization root and inherited by all the AWS accounts. For example:
- Disable all regions apart from
eu-west-1(see screenshot below). - Prevent tinkering of CloudTrail collection (e.g. disable trail collection or temper with the S3 bucket in any way).
I use org-formation for IaC for the AWS organization. Everything from account creation, password policy, SCPs and the landing zones are configured in code and source controlled.
How it’s going
Soon after the app went live in September, ~15k students signed up in the first few weeks. The level of activities on the app was on the up and averaged 150k–200k AppSync API calls per day.
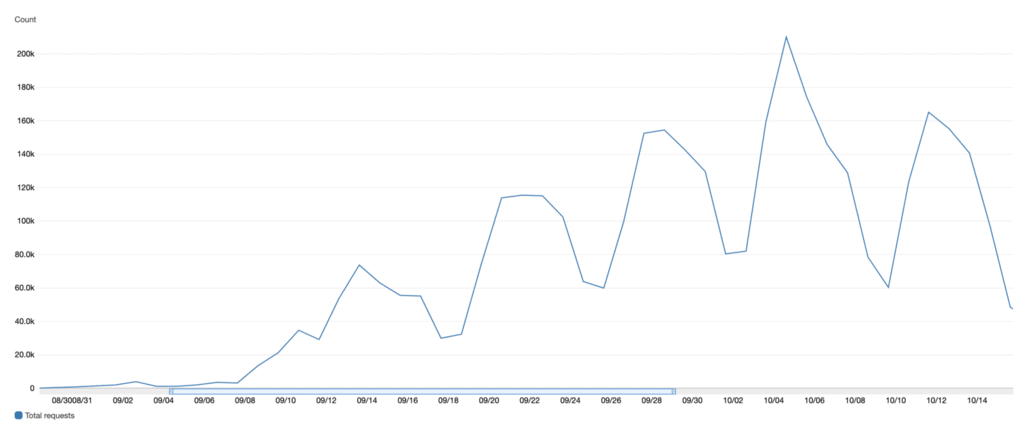
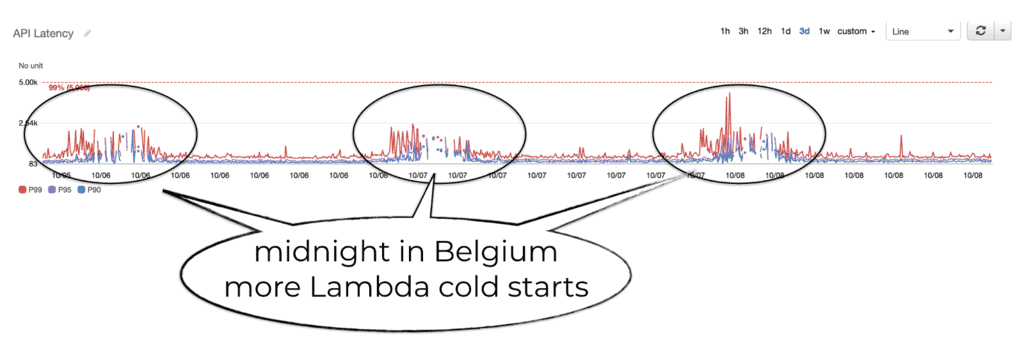
The performance has been great in general, with p99 latency consistently below 500ms except in the middle of the night when practically no one is using the app. There are more Lambda cold starts during these times and so the tail latencies tend to spike.
But that’s OK because again, practically no one is using the app.
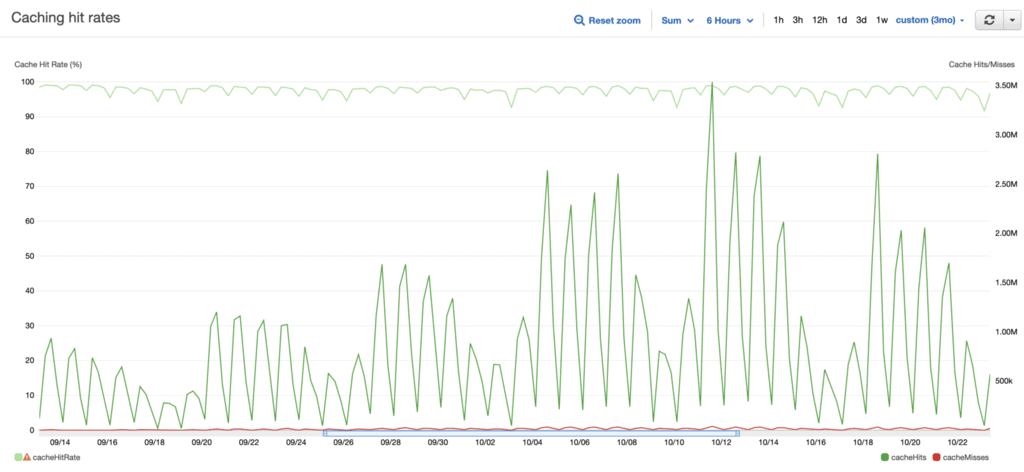
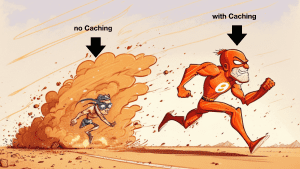
AppSync has built-in caching support and lets you configure caching at the resolver level. So after some fine-tuning, I achieved a steady 99% cache hit rate on the AppSync API.
That’s right, 99% of requests never hit the DynamoDB tables or Lambda functions. Forget the cost efficiency of single-table designs, a sensible caching strategy would save you far more.
By the end of October, the AWS bill was less than $60.
50% of which was on the AppSync cache, of which the app is using about 5% of the available cache capacity. So this cost will not grow for the foreseeable future.
Since the AppSync cache is soaking up 99% of the requests to the DynamoDB tables and Lambda functions, it keeps the DynamoDB and Lambda cost down. In fact, the app still within the Lambda free tier so the client hasn’t started paying for them yet!
Besides what you see below, there’s another $15 for CloudWatch Logs and X-Ray. So overall, the cost for this has been pretty reasonable. Especially when you consider that there’s multi-AZ redundancy for every layer of the stack and the servers are always patched with the latest security updates (because that’s just what you get with serverless components! :-P)

Since then, Belgium has gone into a second lock-down and so the activity on the app has dropped significantly. You can’t do sports together or book sports classes when everyone is staying at home and the universities are closed.
Luckily, with serverless components, you only pay for what you use. The only thing in the architecture that is charged by uptime is the AppSync cache. So as the activities on the app dropped, so too have the AWS costs.
Debugging/Troubleshooting
For debugging and troubleshooting, Lumigo has also been a big help during development as well as in production (although there hasn’t been any issues in production since the app launched).
The dashboard tells me a lot at a glance. What functions had errors, which functions have the most number of cold starts, and how my dependencies (Algolia, DynamoDB, etc.) are performing?
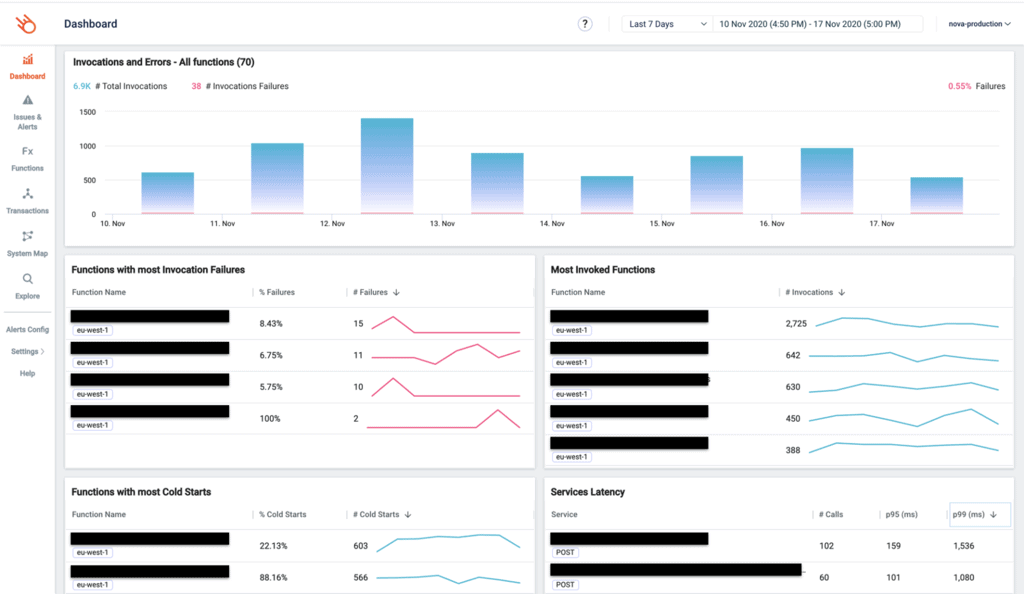
For individual requests, I can use the transactions view to see everything that happened in that transaction.
Lumigo automatically captures the Lambda invocation event and records the request and response in all outbound HTTP requests. So it’s easy to figure out what was going out without spraying my code full of debug logs.
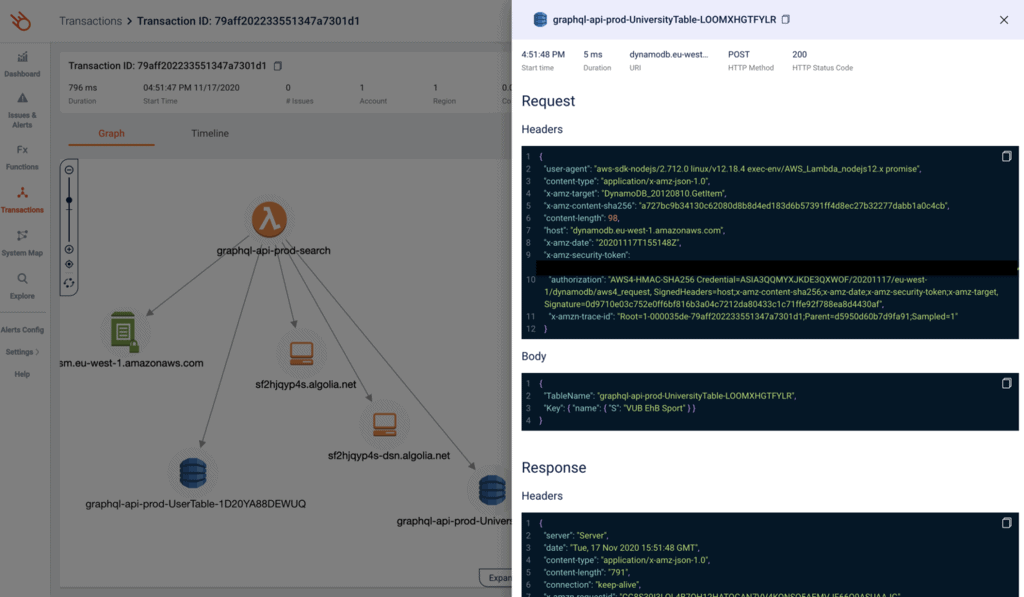
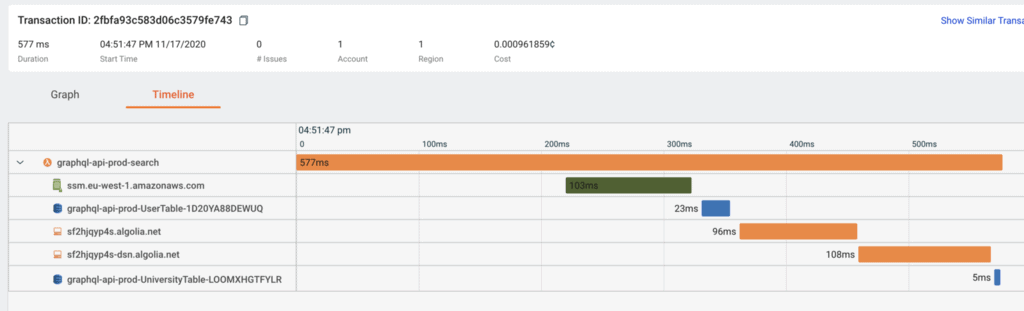
You can see a timeline of events too, so it’s easy to identify where those milliseconds are spent during a transaction.
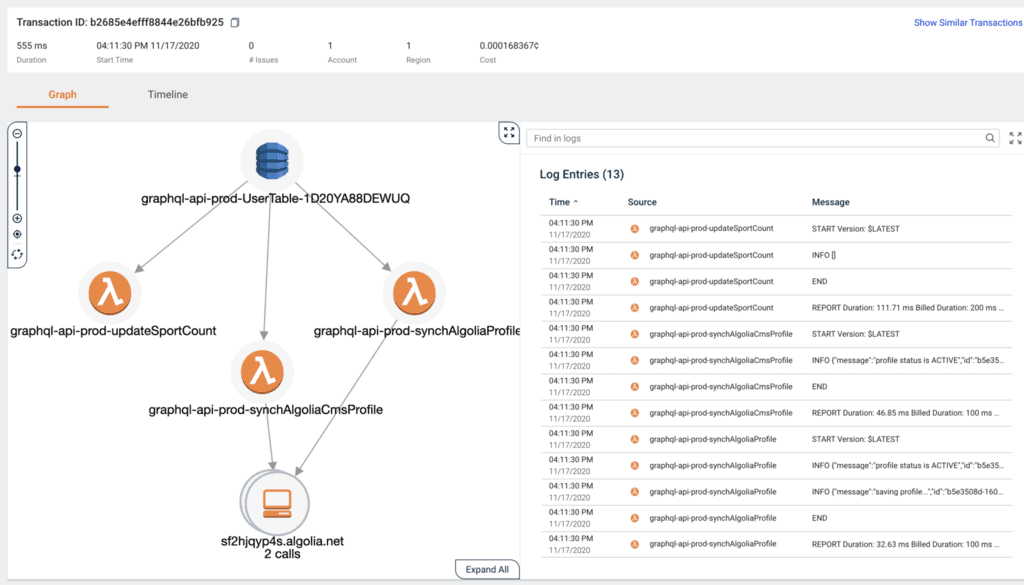
Oh, and this works for more complex scenarios too, like when DynamoDB streams are involved. And you can see your function logs side-by-side with the transaction. So everything is in one place and at your fingertips.
To debug AppSync resolvers that don’t involve a Lambda function, the AppSync resolver logs is a big help. You get sooo much information – how long each resolver step took, the state of the $context object, and even the transformed request and response templates if you enable verbose logging.
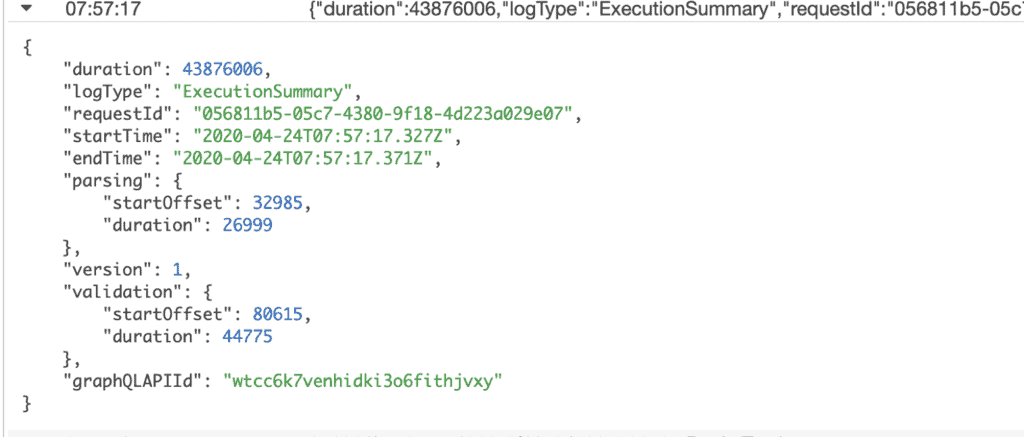
And on top of that, AppSync integrates with X-Ray out-of-the-box so you can see exactly what happens during a captured request.
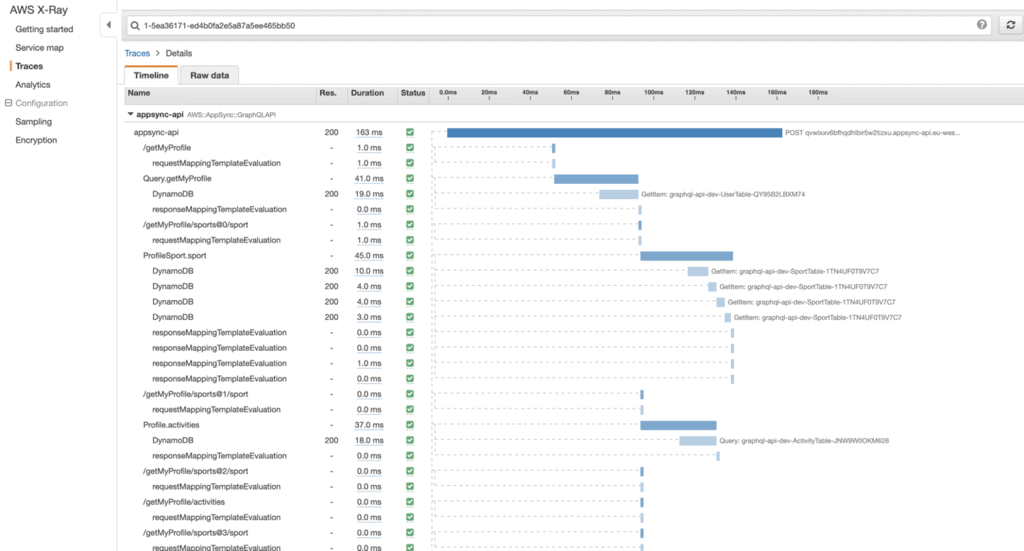
All in all, it has been pretty straight forward to debug issues when they come up during development.
GraphQL + Serverless gives you wings!
This was a non-trivial project, involving over 200 AppSync resolvers and 600 CloudFormation resources. And I have learnt a lot in the process, and honestly surprised myself a little by how much I managed to do in just a few weeks.
Mastering technologies like GraphQL and AppSync can make you so much more productive. There is a learning curve for sure, I don’t expect you to reach my level of proficiency right away. I have been building stuff on AWS for more than 10 years and working with serverless technologies in production for the last 4 years. I have spent a lot of time working with these technologies and have learnt their caveats and when to use which. It will take you time to learn them too, but it’ll be worth it.
To help you get there faster, I have packed everything I have learnt about AppSync and GraphQL into the AppSync Masterclass. In this course, you will learn AppSync by building a Twitter clone from scratch, and I’ll show you all the tips and tricks along the way – including how to unit test VTL templates, how to write end-to-end tests, and how to come up with an effective caching strategy and set up monitoring and logging and much more.
Hope to see you inside the course :-)

Related Posts







Whenever you’re ready, here are 3 ways I can help you:
- Production-Ready Serverless: Join 20+ AWS Heroes & Community Builders and 1000+ other students in levelling up your serverless game. This is your one-stop shop for quickly levelling up your serverless skills.
- I help clients launch product ideas, improve their development processes and upskill their teams. If you’d like to work together, then let’s get in touch.
- Join my community on Discord, ask questions, and join the discussion on all things AWS and Serverless.