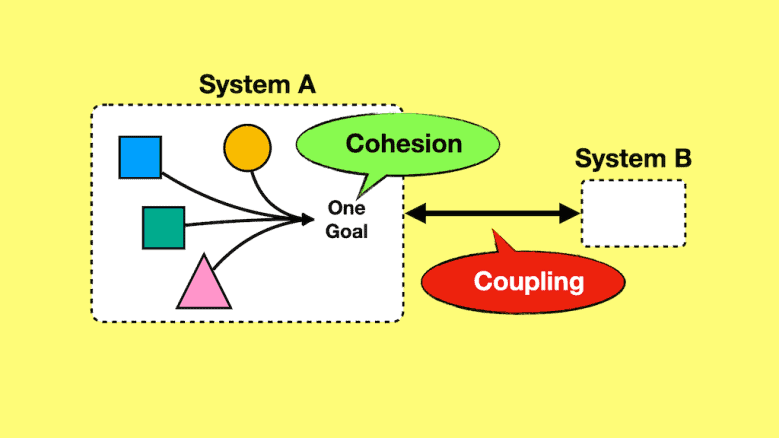
Cohesion vs. Coupling
“High cohesion, low coupling” is one of the most cited, and yet, most misunderstood principles in software engineering.
So in this short post, let’s explain their difference with a few easy-to-understand examples.
“High cohesion, low coupling” is one of the most cited, and yet, most misunderstood principles in software engineering.
So in this short post, let’s explain their difference with a few easy-to-understand examples.
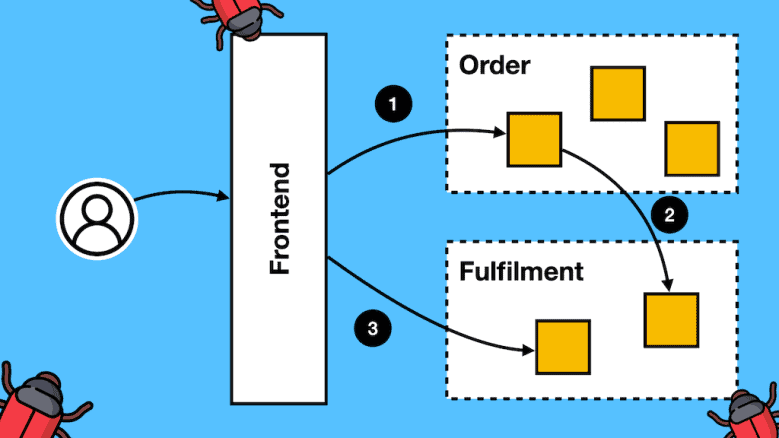
There is more than one way to test user journeys that span multiple bounded contexts. Your choice depends on organizational structure, team responsibilities, and the maturity of your testing practices.
Ultimately, every part of the user journey should be tested, whether it’s done piecemeal by individual teams or centrally by a QA/cross-functional team.
In this article, let’s look at several ways you can approach this problem, depending on if you have full-stack teams or specialised frontend and backend teams. We will look at trade-offs and whether it’s best to host other teams’ services in your environment, or use mock APIs, or delegate testing user journeys to a QA team and use a dedicated integration environment for testing.

Caching is still important for serverless architectures. Just because AWS Lambda auto-scales by traffic, it doesn’t mean we can forget about caching. In this post, let’s break down by caching is still relevant for serverless and where we can apply caching in a serverless architecture. Caching is still VERY relevant. Yes, Lambda auto-scales by traffic. …
All you need to know about caching for serverless applications Read More »

Update 06/04/2023: It’s been 3 years since I originally wrote this blog post and I want to share some updates to my thinking because this blog post was referenced in a recent PR for the serverless-esbuild project. Thanks, Fredrick for messaging me about this. Let me start by saying that the risks I outlined in …
Should you pack the AWS SDK in your deployment artefact? Read More »

A while back, a client asked me “how can I share business logic between services in a Node.js monorepo?”. The TL;DR of it is: Encapsulate the shared business logic into modules, and put them in a separate folder. In the Lambda handler functions, reference the shared modules using relative paths. Use webpack to resolve and …
AWS Lambda: how to share code between functions in a monorepo Read More »
We previously discussed how you can implement an ad-hoc scheduling system using DynamoDB TTL as well as CloudWatch Events. And now, let’s see how you can implement the same system using AWS Step Functions and the pros and cons of this approach. As before, we will assess this approach using the following criteria: Precision: how …
Step Functions as an ad-hoc scheduling mechanism Read More »
A while back I wrote about using DynamoDB TTL to implement ad-hoc scheduling. It generated some healthy debate and a few of you have mentioned alternatives including using Step Functions. So let’s take a look at some of these alternatives, starting with the simplest – using a cron job. We will assess this approach using the …
Using CloudWatch and Lambda to implement ad-hoc scheduling Read More »
If you’re not familiar with how cold start works within the context of AWS Lambda, then read this post first. update 24/03/2019: the tests include WebPack as well. When a Node.js Lambda function cold starts, a number of things happen: the Lambda service has to find a server with enough capacity to host the new …

The Serverless Framework [1] is still the most popular deployment framework for serverless applications. It gives you a convenient abstraction over CloudFormation and some best practices out of the box: Filters out dev dependencies for Node.js function. Update deployment packages to S3, which lets you work around the default 50MB limit on deployment packages. Enforces …
Making Terraform and Serverless framework work together Read More »
Update 15/03/2019: Thanks to Zac Charles who pointed me to this new page in the DynamoDB docs. It explains how the OnDemand capacity mode works. Turns out you DON’T need to pre-warm a table. You just need to create the table with the desired peak throughput (Provisioned), and then change it to OnDemand. After you change the table to OnDemand …
Understanding the scaling behaviour of DynamoDB OnDemand tables Read More »
By continuing to use the site, you agree to the use of cookies. more information
The cookie settings on this website are set to "allow cookies" to give you the best browsing experience possible. If you continue to use this website without changing your cookie settings or you click "Accept" below then you are consenting to this.